
|
Table of Contents:
|
||||||||
Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
|
TWDT 1 (gzipped text file) TWDT 2 (HTML file) are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version. | |||
![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/ ,
http://www.linuxgazette.com/This page maintained by the Editor of Linux Gazette, gazette@ssc.com
Copyright © 1996-2001 Specialized Systems Consultants, Inc. | |||
 Greetings from Heather Stern
Greetings from Heather SternWelcome to the Extra issue this February. We had a few extra things in the queue here this time and figured you just couldn't wait, so here they are!
I have to say I am really very impressed by the Human Genome Project's results. There seem to be two sides of the camp... but, we can't call them "the Cathedral and the Bazaar":
Um, let's call them the College and the Commerce. Mr. James Kent in Santa Cruz wrote, over a fairly short time, a program to have about 100 pentiums help him assemble the genome data out of public and academic fragments. (I'm not sure which he used more of, ice packs, or Jolt Cola.)
Meanwhile, Celera was pouring lots of hours and corporate resources into doing the same thing. They both succeeded to an announceable degree, within days of each other. We're not quite at curing cancer yet, but maybe there are enough resources now to start nailing some of the more clearly genetic diseases. There's certainly a lot of work to be done. Anyways, you can read a lot about all this in the New York Times -- I did.
Of course, to read the New York Times online at http://www.nytimes.com, they want you to register. Sigh. To access Celera's database, you have to pay for access (but, they might have more than they published about, too, so maybe you're at least paying for some serious R&D). Still, what the school system paid for is available to all of us... though not terribly readable unless you're into genetics:
Hey wait a minute, I hear you cry. This isn't Linux! Well, I don't know. It could have been. It doesn't matter. (Gasp! Linux doesn't matter? What can you mean!?) What's more important is what gets done with a computer.
The sheer number of people who have contributed to figure out how we really tick, and the time they continue to put in, since we aren't nearly at the point where we can run a make script, have the waldos get out a petri dish, and create even so tiny a creature as a mouse "from scratch" is just amazing. (Let's see, if the Creator writes and debugs one line of code a year in us, we're as big as... er, never mind.) Compared to that, my effort every month on LG seems like a breeze.
 The Answer Gang
The Answer Gang

Why is diff so crazy?From sbcs
Answered By Heather Stern
This is the reformatting and basically kick-in-the-pants of a question that's been in the mill for a few months. For 3 months this fellow patiently sent the message again, certain that someday, we would get to him.
Before I get started with the actual question, I'd like to make it completely clear to our readers... we do enjoy answering questions. For some strange reason, that is part of what is fun about Linux for those of us here in the Answer Gang. The Gazette exists to make Linux a little more fun so here we are.
However, we're all volunteers, we all have day jobs and most of us have families and pillows we like to visit with once in a while. There is no guarantee that anyone who sends us mail gets an answer.
[ He also had some problems that made his mail a good candidate to get ignored. Since we had another thread elsewhere on features that will help you get an answer, I moved my comments there, and you saw those in Creed of the Querent earlier this month. ]
I've added paragraphs, and hit it with my best shot, and maybe the Gang can help out a bit further. Comments from you, gentle readers, are always welcome too!
So now, on to the tasty question.
![]() I wanted to build a fresh installation on my portable (Red Hat 5.2
upgraded to 6.0), but I didn't want to just erase the old one.
I wanted to build a fresh installation on my portable (Red Hat 5.2
upgraded to 6.0), but I didn't want to just erase the old one.
So I pulled the notebook's hard drive, plugged it into my server (Red Hat 6.2) and archived the contents with cp -a file file. The -a (archive) tells cp to preserve links, preserve file attributes if possible and to copy directories recursively. The copy process didn't return any errors... so far so good.
[Heather] Okay. So far, we have that you wanted to upgrade, so you planned to back it up. That's a good idea, but the method isn't so hot.
cp -a really only works if you're root, and I can't tell if you were, or not. But it's not the method I would use to do a proper backup of everything. I normally use GNU tar:
cd /mnt/otherbox
tar czvfpS /usr/local/otherbox-60-backup.tgz .
The options stand for (in order) [c]reate, use g[z]ip compression, be [v]erbose, send the output to a [f]ile instead of a tape (this option needs a parameter), save the [p]ermissions, be careful about [S]parse files if they exist. The file parameter given has a tgz extension to remind myself later that it's a tar in gzip format, and I put it in /usr/local because that usually has lots of free space. The very last parameter is a period, so that I'm indicating the current directory. I do not want to accidentally mix up any parts from my server into my otherbox backup.
Among other things it properly deals with backing up device files... all those strange things you'd normally use mknod to create.
tar dzvfpS /usr/local/otherbox-60-backup.tgz .
Where the d stands for diff and all the rest is the same. Diff does have a glitch, and will complain about one special kind of file called a socket. X often has at least one of these, the log system usually uses one, and the mouse often uses one too. It's okay to ignore that because a socket depends on the context of the program that owns it, and right now, there's no program running from that disk to give it the right context anyway. (Okay. I'm guessing. but, that is a theory I have which seems to fit all the ways I see sockets used.)
Now my husband Jim doesn't always trust tar, and sometimes uses cpio. I'll let him or one of the rest of the Gang answer with a better description of using cpio correctly. What I will tell you is why. When you are about to do a full restore of a tarball, it checks to see if can assign the permissions back to the correct original owners. However, a complete restore will be to an empty disk, which won't have correct passwd and group files yet. Oops.
But there is a fix for this too, and I use it all the time when restoring:
cd /mnt/emptydisk
tar xzvfpS --numeric-owner /usr/local/otherbox-60-backup.tgz .
It's just as valid to use midnight commander to create /mnt/emptydisk/etc, open up the backup tgz file, and copy across the precious /etc/shadow, /etc/group, and /etc/passwd files before issuing your restore command.
![]() But when I ran diff -r file file, I got screen-fulls of errors. The
most obvious problem was that diff was stuck in a loop with
"/usr/bin/mh", a symbolic link pointing back to "/usr/bin".
But when I ran diff -r file file, I got screen-fulls of errors. The
most obvious problem was that diff was stuck in a loop with
"/usr/bin/mh", a symbolic link pointing back to "/usr/bin".
![]() Make a
pair of directories, each containing a symbolic link pointing back at
the directory it resides in, and then run diff -r on those two
directories and you can see what I mean.
Make a
pair of directories, each containing a symbolic link pointing back at
the directory it resides in, and then run diff -r on those two
directories and you can see what I mean.
The diff program doesn't fail on all symbolic links... just those that lead into loops and some others (I didn't take time to explore what it was about the others). I removed "/usr/bin/mh" (I'd have preferred not to have had to, but I wanted to move along and see what other snags I could hit), ran diff again with output redirected to a file and started taking the file apart with grep and wc to find out what general classes of error I was dealing with... turns out diff was failing on "character special" files, sockets and "block special" files.
I don't know what any of those three are, but I used find and wc again on the file system and discovered that diff was failing on every single one that it tried to compare. Does anybody know what to do about these problems?
update: After a week of trying, I'm unable to duplicate the event above. I installed Red Hat 6.0 on a pair of Gateways... basically the same procedure as I did for my disk usage article at the other end of that link.
When I ran the diff, it seemed to start looping somewhere in "/tmp/orbit-root"... I let it run for about 24 hours and the hard drive light was still flashing the next day, no error message.
I tried 6.0 transplanted into a 6.2 box... same thing. I put 6.0 on my portable, pulled the drive and attached it to my server, and got the same thing. I put 5.2 on my portable, upgraded it to 6.0, pulled the drive and attached it to my server... same circumstances as the original event... and diff looped somewhere in "/tmp/.X11-unix" instead of "/tmp/orbit-root".
While we're at mentioning filesystems to skip, make sure not to bother getting the /proc filesystem, either. The -l (little ell) switch to tar when making a backup, will make sure it won't wander across filesystem borders unless you specify them on the command line.
cd /mnt/otherdisk
(mount its subvolumes here ... skip tmp, proc, and devfs if you have it)
tar czvfpSl /usr/local/otherbox-60-backup.tgz . usr var home
![]() The diff program definitely has issues with most types of non-regular
files (directories excluded), as well as the problem of at other times
looping without ever generating an error message (which could, of
course, be related to the same basic problem with non-regular files).
Suggestion(s), anyone?
The diff program definitely has issues with most types of non-regular
files (directories excluded), as well as the problem of at other times
looping without ever generating an error message (which could, of
course, be related to the same basic problem with non-regular files).
Suggestion(s), anyone?
![]()
State of the Art in softmodemsFrom Marcelo Henrique Gonalves
Answered By Heather Stern
Hi
I have a PCTel HSP Micromodem 56! Yes! Onboard
![]()
This modem is compatible with Conectiva Linux, in the site of conectiva
says "no" and yours too!
![]()
But can i configure my modem anyway! If a download a rpm or other file?!?!
Thankx
by
BM
OS PIRATA!!!
There used to be only two of these kind of modems with any hope for them whatsoever, in both cases very tricky because vendors had created binary drivers and orphaned them. The only way you can get more unsupported than that is to not have drivers at all.
(Can someome out there please spin up a new buzzword for "software released on the basis that you get no tech support" so we can go back to using "unsupported" for meaning "doesn't work" ?)
Normally for software-modems or controllerless modems (what's the difference? which chip out of three is missing. sigh) we of the Answer Gang simply point querents at the Linmodems site (http://www.linmodems.org) and shake our shaggy heads. It's a lot of work to go through just to use a modem that borrows so much CPU effort and buckles just when the dataflow gets good anyway.
However, I've been watching and it looks like the number of types that can work (whether "supported" or not) has grown to four.
I'll start with yours first because that's what you need. PCTel was one of the early ones to let a driver sneak out, maintained by PCCHIPS. Corel made a .deb of their driver for 2.2.16, and some unknown hero named Sean turned that into a .tgz and has also got available an extra site for Thomas Wright's effort toward the same chipset... a driver for 2.4
- Sean's site:
- http://walbran.org/sean/linux/stodolsk
- Download point for Thomas' 2.4 PCTel driver:
- http://www.geocities.com/tom_in_rc/pctel
Hopefully that does it for you!
Now as for good news for everyone else
Anyone using Lucent controllerless modems. will also want to take a look at Sean's site, because he keeps a decent listing of useful scripts and kernel parts that you'll find handy.
For those who prefer code built completely from scratch, Richard's LTmodem diagnostic tool moved up to version 0.9.9 ... it can now answer the phone, and handle voice grade work, so you can use it for mgetty setup (where you want to be able to dial straight home) but I think it still isn't good for ppp. Anyone's welccome to let us and the linmodem crowd know if you get ppp working with it:
- Richard's LTModem Page
- http://www.close.u-net.com/ltmodem.html
- IBM has a project they're calling "Mauve":
- http://oss.software.ibm.com/developer/opensource/linux/projects/mwave
...which is a driver for the ACP modem found in the IBM Thinkpad 600E. They say they are working on some licensing issues, but plan to release the source for it as soon as they can. Meanwhile, they have updated it at least once, so we know they're fixing bugs.
And lastly, Mikhail Moreyra wrote a driver for the Ambient Tech chipset... that's a DSP-based modem that used to be from Cirrus Logic, just in case one of you gentle readers has an older box. In theory this may work for your software-driven modem if it claims to be a "sound card modem" since that's what the DSP chip really is. Linmodems only points to his tgz but don't worry, it's source code
To the rest of you, sorry. Maybe you should go out and buy a solid external modem with its very own power supply and line-noise reduction features, or a Cardbus modem that isn't afraid to use a little real estate to offer a complete-chipset modem.
DistrosFrom Gerald Saunders
Answered By Don Marti, Mike Orr, Heather Stern
How about an (objective) artical on the relative diferences between the different GNU/LINUX distributions. Newbies have to rely on the "propaganda" generated by those distributions in order to make decisions as to which distribution serves their needs best. A realy informed guide is what is needed. I, for example, think that Mandrake is best for newbies and Debian is a more stable platform (and more philosophically correct!). Am I right though?
How to pick the best Linux distribution to run:
- Find the person who you would be most likely to ask for help if you have a Linux problem.
- Run what he or she runs.
If you would be most likely to ask on a mailing list for Linux help, read the list for a while and see what the most helpful posters run.
Any technology distinguishable from magic is insufficiently advanced.
Different users have different expectations and requirements, so finding one distribution that's the "best" is as futile as the emacs/vi wars.
- The Duke of URL has been writing reviews of new distributions as they appear. Read a few reviews, and that's the same as a comparision.
- Links to the Duke's reviews and others are in the past several issues of LG in the News Bytes column.
- Linux Journal has a table comparing several distributions. http://noframes.linuxjournal.com/lj-issues/distable.html It was written July 2000. I'm cc'ing the Editor so they'll know there's interest in seeing an update.
- Several of the web sites that cater to new Linux users have information about different distributions. Look around and see if you find anything.
- Linux Weekly News has the most comprehensive listing of distributions of any site I know about. http://www.lwn.net
- You may find something at http://www.osopinion.com, although usually their focus is on Linux as a whole rather than on the differences between distributions. Nevertheless, it's a fun place to browse occasionally just to see what new articles they have.
It might be worthwhile to come up with some major criteria, and then attempt to map distributions against those criteria, so that people get a lot more useful data than "4 penguins, looks great to me."
You're right about propaganda, but, a "really informed guide" is going to be written by ... who? Surely not a newbie. Can a newbie really trust someone wiser enough than them to write a book, to have any idea what sort of things are easy or difficult for a newbie anymore?
Hi Heather!
Yeah I suppose you are right on that. If some one is advanced enough to know heaps about Linux then they probably wouldn't relate well to an abject newbie! I just thought it was a good Idea as when I was trying to find info on the different Linux distros I ended up guessing. There was not much out there to let me make an informed decision. I ended up trying Debian, which was a steep learning curve. I would probably tried Mandrake or Redhat if I had known how steep. I now use Mandrake because of Hpt366 (ata66) support, Reiser FS, Cups printing right out of the box. But my heart is still with Debian!
Cheers, Gerald.
Progeny is presently at Beta Two, with downloadable cdrom images available. See http://www.progenylinux.com/news/beta2release.html for the PR, release notes, and a list of discs.
You might also try Storm Linux, LibraNet, or CorelLinux; all are debian based commercial distros, so at least, their installer is a bit smoother. GUI installers drive me crazy, so of the three, I prefer LibraNet.
Thanks Heather!
I will check those out!
Thanks again, Gerald.
RE Solaris UNIX?From Mitchell Bruntel
Gee: I have a question, and an answer. I sent the question earlier about LILO and not booting hda5 (ugh)
Is AIX or Solaris or SunOS or HP-UX a UNIX?
[Heather] AIX and Solaris are blessed with this trademark under "UNIX 98", HP-UX and Tru64 among others are blessed under "UNIX 95". (You can see the Open Group's Registered Product Catalog if you care:http://www.opengroup.org/regproducts/catalog.htm
I don't think SunOS ever got so blessed; it was a BSD derivitive after all. You can read some about the confusions between SunOS and Solaris in this handy note:http://www.math.umd.edu/~helpdesk/Online/GettingStarted/SunOS-Solaris.html
Solaris (as opposed to SUN-OS) IS UNIX System V.4
AT&T merged Sun-OS back in with System V and got a bunch of stuff. especially the init systems we love, as well as package-add format.
btw, is there any demand in LINUX for users/programmers with SUN system V package-add experience?
BTW, Solaris also has the distinction of being BOTH BSD, and System V.4 both in one.
a great deal of the product is now engineered to favor V.4, but there are still some BSD roots and compatibility there!
Mitch Bruntel
(ATT Labs-- maybe that's why I know this trivia?)
linux anti virus?From Jugs
Answered By Mike Orr, Heather Stern
On Sat, Sep 16, 2000 at 03:59:53PM +0200, jugs wrote:
![]() hi
hi
i wonder if you could help?.
i am running a mail/internet server with the red hat linux (6.2) operating
system. Viruses are getting through the end user via emails and are spread
over my local area network.
1) is there any anti virus software that i can get for the linux box?
You could use:
- AMaViS (A Mail Virus Scanner) ...note, they have a bunch of great links too!
- http://www.amavis.org
- Freshmeat has a whole section on antivirus daemons
- http://freshmeat.net/appindex/Daemons/Anti-Virus.html
Mind you, most of these require that you have the linux version of one of the commercial vendors' antivirus apps, or, they're meant to deal with problems which usually break the clients (e.g. poor MIME construction, etc). At least one of the commercial vendors has a complete solution for us though... and a handful of other 'Ix flavors too:
- Trend Micro's Interscan VirusWall
- http://www.antivirus.com/products/isvw
...and in case anyone is wondering whether it only works on RH, I have a few clients who got it working on SuSE and seem pretty happy with it.
For those who prefer to go with all free parts, I have to note, VACina (a sourceforge project) isn't very far along, and anti-spam stuff can be twisted only so far if you aren't planning to become an antivirus engineer on your own.
![]() 2) the option of buying software for each machine wipes my budget out.
preferably the solution that i would like would be to stop the virus at
the server.
2) the option of buying software for each machine wipes my budget out.
preferably the solution that i would like would be to stop the virus at
the server.
A school I did a bunch of work with solved the problem in their labs in this way: every evening when the lab closed, they'd go around with a spot checker and take notes what was found. They didn't waste time cleaning any, they just reformatted and reinstalled the OS from a network image. (Among other things, that way they didn't have to worry if they missed some new breed.) But they posted the note on the wall, how many viruses were found the night before. They also made it easy for students to spot check their disks. Of course, the school had an educational license to the AV software. You can think of this as the "free clinic" style of solving it, if you like... though real illnesses, sadly, can't be solved by reformatting the human.
But, I can't say what your budget really is. In the end, you'll have to decide if you want to spend more time or more money.
![]() if you could suggest a solution i would be grateful
if you could suggest a solution i would be grateful
thanking you
jugs
Por favor Ayuda !From Carlos Moreno
Answered By Felipe E. Barousse Boue
(one of our translators)
This message was sent to the gazette mailbox in Spanish. Mike Orr forwarded it to Felipe for translation. Sadly, Carlos' accent marks got mangled in the transition.
Here it goes: (I decided to add a reply to Carlos...by the way, I can tell by his email that he seems to live in Mexico)
![]() Hi Linux friends, I need your help desperately. I just got a Linux disk
(Red Hat 6.0) and the installation process was very painful
Hi Linux friends, I need your help desperately. I just got a Linux disk
(Red Hat 6.0) and the installation process was very painful
After finding out how disk druid worked, I started to partition my disk. It took around 15 minutes to install and configure, at the end I assigned a password for "root" and reboot the equipment.
A huge amount of text was displayed with many "OK". Finally, it printed the "login" prompt where I typed out "root" and my password, then it displays the following message:
[Bash: root@localhost /root]#
I don't know what to do, I can't initialize Linux and it's very disspointing. I want to start on a KDE graphical interface and I can't. Please help me, I ned it a lot.
Regards.
Carlos Moreno.
Welcome to the world if Linux. It seems that you installed Linux correctly since you are getting all those "OK" prompts after rebooting your system and at the end you get a "login" prompt. When you type your "root" id and your password, in fact your ARE now in Linux but, you are in text mode.
If you want to initiate the graphical user interface, first you have to ensure that the graphical environment was installed in first place and, second, that it is configured correctly for your equipment. To start, give the "startx" command after you logged in and got the shell command prompt:
Bash: root@localhost /root]# prompt
This will attempt to initialize the Graphics Environment, if, and only if it is installed and configured correctly. Otherwise, you will have to install it and set it up. (that is a long question/reply so, lets first find out it if you are ok at this point.)
I will suggest that you take a look at http://www.gacetadelinux.com which contains the Spanish edition of Linux Gazette and there we have a new user forum -in Spanish- where you can get a lot of help related to Linux, including installations, configurations and Linux use.
I can assure that once you learn a little bit about Linux, you will have a great experience with this operating system.
Greetings for now.
Felipe Barousse
![]() Hola amigos de Linux necesito ayuda desesperadamente,acabo de
adquirir el disco de linux (red-hat 6.0) la instalacion fue un
verdadero viacrucis.
Hola amigos de Linux necesito ayuda desesperadamente,acabo de
adquirir el disco de linux (red-hat 6.0) la instalacion fue un
verdadero viacrucis.
Despues de averiguar como funcionaba el disk druid empece a hacer mi particio linux me tarde aprox. 15 minutos en instalarlo y configurarlo. y finalamente asigne una contrase?a para "root" y reinicio el equipo, se desplego una enorme cantidad de texto y muchos "Ok" Finalmente me pidio el login en el cual puse "root" y mi contrase?a, entonces desplega el siguiente mensaje
[Bash: root@localhost /root]#
y no se que hacer, no puedo iniciar linux y es traumatico kiero iniciarlo en interfase KDE y no puedo, por favor ayudenme es indispensable
Atte. Carlos Moreno
Bienvenido al mundo de Linux. Al parecer, por lo que describes, instalaste correctamente Linux. Esto lo puedo decir por todos los "OK" que aparecieron cuando re-iniciaste tu equipo. Al final, cuando te pide el "login" y tu tecleas root y tu password, de hecho ya estas en Linux solo que en modo de texto.
Si quieres iniciar el modo gráfico, primero hay que asegurarse de que lo hayas instalado en un principio y esté correctamente configurado. Para ello prueba usar el comando "startx" cuando te aparece el prompt de comando:
[Bash: root@localhost /root]# startx
Esto intentará iniciar el modo gráfico si y solo si está instalado. En caso contrario habr� que instalarlo o, en todo caso configurarlo correctamente.
Te sugiero visites la edición en Español de Linux Gazette en http://www.gacetadelinux.com y ahí, en el foro de principiantes puedes encontrar mucha ayuda relativa a la instalación, configuración y uso de Linux.
Te puedo asegurar que una vez que aprendas un poco de Linux, tendrás una muy agradable experiencia con éste sistema operativo
Un saludo por ahora.
Felipe Barousse Boué
SGI Visual WorkstationFrom Beth H.
Answered By Jim Dennis
Hi Answer Guys!
I must install LINUX on an SGI 540 Visual Workstation running WinNT4.0. I'm using RedHat 6.2 and want to make a dual boot system with LINUX on the 2nd SCSI drive.
My problem is that I can't boot off the RedHat install floppy or the CD. I can't get past SGI's system initialization/setup to boot off either device. I have installed this software on several INTEL Pentium platforms without any trouble.
Please help me get started and/or provide some useful websites that will help. I find SGI/MIPS stuff, but can't seem to find anything else. I checked your answers too so if I missed it, my apologies.
Thanks,
Beth H.
[From a U.S. Navy Address]
So you can't boot one with a typical Linux distribution CD or floppy. I guess we have to find a custom made kernel and prepare a custom boot floppy or CD therefrom. Did you call SGI's technical support staff? They probably have a floppy image tucked away on their web site somewhere; and SGI is certainly not hostile to Linux. Give them a call; if that doesn't work I'll try to dig up the e-mail addresses of some of the employees that took my class and see if I can get a personal answer.
After writing this I got to a point where my Ricochet wireless link could "see bits." (I do all of my e-mail from my laptop these days, and much of it as during business meetings or at coffee shops and restaurants; so it's a little harder to do searches --- I write most of my TAG articles from memory and locally cached LDP docs --- an 18Gb disk is good for that).
So I did a Google!/Linux (http://www.google.com/linux) search on the string: 'SGI "visual workstation" boot images' and found:
- Linux for SGI Visual Workstations:
- Linux 2.2.10 + Red Hat 6.0
Updated: July 28, 1999
http://oss.sgi.com/www.linux.sgi.com/intel/visws/flop.html
Luckily the main differences are in the kernel and (possibly) in the boot loader and a few hardware utilities. I wouldn't expect programs like hwclock, lspci, isapnp etc work --- though some of them might. I've seen lspci used on PowerPC (PReP) systems, and I've used it on SPARC Linux. I seem to remember that hwclock was modified to use a /proc interface and that most of its core functionality is now in the kernel.
The other software element that is very hardware dependent is the video driver. As more accelerated framebuffer drivers are being added to the kernel then this becomes less of an issue (it folds back into the earlier statement: "MOST of the differences are IN THE KERNEL").
So, once you get the boot disk/CD and an X server working most other software and all of your applications should work just fine.
Of course updates to RH6.2 or later, and to newer kernels might be a bit of a challenge. However, I'll leave those as exercises to the readership. The source is all out there!
 More 2¢ Tips!
More 2¢ Tips!
 iI've got an IDE CD-RW...
iI've got an IDE CD-RW...Joey Winchester asked:
I need to use the ide-scsi.o module, but NONE of the 'HOWTOs' help, they just give the code to check 'cdrecord -scanbus'. Okay, my CD-RW's not listed, so WHAT DO I DO?? The HOWTOs aren't helpful at ALL. So how can I recompile the kernel to use my IDE drive as a CD-RW and NOT just a CD-ROM.
You need to give the kernel an option, to warn it that it not only requires the hardware level driver (IDE CDROM in this case) but also the IDE-SCSI interface driver. This applies just as much if your ATAPI device is builtin, or attached via Cardbus (as mine is). The easiest place to put this is in your /etc/lilo.conf:
append="hdc=ide-scsi"
If you have more than one kernel option, though, they have to be in one big append statement. What will happen is that you'll get some sort of warning message about a missing driver as the drive initializes. Ignore it, your device should be able to read fine without that. But, when you want to write, then modprobe ide-scsi and your virtual SCSI host will be established. After that the normal instructions for cdrecord and all its brethren will work.
3 legged router: FreeScoFirst, let me comment that I think TAG is exceptional. I stumbled upon it by accident, and ended up reading every question and answer, and after this email, will be going to look for previous months. Anyhow, in reference to one of the questions asked about a firewall (Firewall for a SOHO From Tom Bynum), you suggested a 3 legged Linux box to do his routing / Firewalling. There is a free router / firewall called FreeSCo (stands for FREE ciSCO) (http://www.freesco.org) that is essentially a firewall on a floppy, with support for a DMZ. I uses (I believe) masq and IPChains. Runs a mimumum of services, etc. You most likely already knew about it, but I thought I'd pass this along (since the guy lives by your mom and all).
Have a good 'un.
-Ray.
Many people still have the impression that Linux is about servers and typing commands in console. Well, that isn't all; Linux is being used on the desktop more and more. Why ? Here are some reasons.
Everybody likes music. The technology lets people listen to high-quality music on audio CDs. But if they aren't using a computer, they are missing a lot. Why change the CD because you want to listen to other album ? Lots of songs can be stored on the hard drive or CD-ROMs.
To do that, you'll have to transform the songs from audio CD to computer files. My favourite tool for that is grip. Download bladeenc (rpm) too, which compresses audio data to mp3 files. Launch grip, set Config -> MP3 -> Encoder to bladeenc and let it rip!
However, you should forget about mp3. A new, open format is available.
mp3 is quite old and has limitations; the encoding software uses
patented algorithms. The alternative, Ogg Vorbis, is intended for unrestricted private,
public, non-profit and commercial use and does not compromise quality for freedom.
You can already start using the ogg encoder instead of mp3. See
this article for an introduction Ogg Vorbis.
Download and install the following RPMs : XMMS plugin, encoder and libraries
Next set oggenc as encoder in grip.
You took all your audio CDs collection and encoded it in computer files. Now you'd like to listen to it, don't you ? Fire up X Multimedia System (I really did :-)
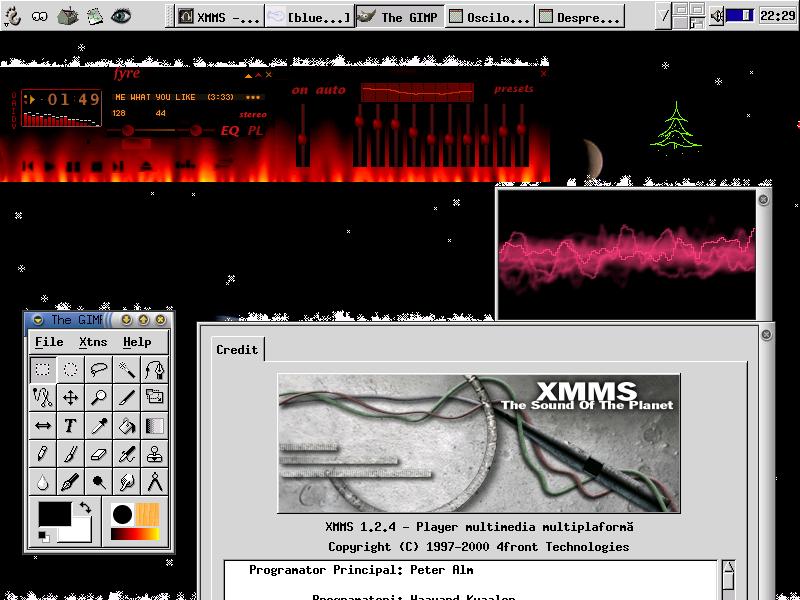
I use a very nice XMMS plugin for crossfading; when the current song is near the end, it fades out while the next song fades in. Let the music play!
While you listen, how about painting ? GNU Image Manipulation Program, or GIMP for short, is the best in digital art on Linux. It can be used as a simple paint program, a expert quality photo retouching program, an online batch processing system, a mass production image renderer, a image format converter, etc.
I'm not into digital art, but look how Michael Hammel managed to transform his cousin in an alien :
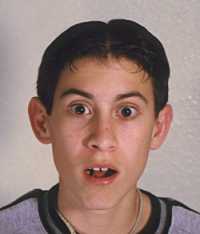

Never trust relatives :). Visit the Graphics Muse site for lots of materials about GIMP and Linux Artist for more resources. For an overview of 3D graphics programs, see this article.
After singing and painting, how about making the computer speak ? Try festival, a free speech synthesizer. As almost always, rpmfind provides links to rpms.
A free speech recognition engine is available from IBM : ViaVoice; it can be used to voice-control xmms for example and simple desktop commands, but writing entire documents from speech is still something for the future.
Besides music, I also watch movies on my computer. smpeg is a nice GPL mpeg player.
Having a movie in 320x240 resolution using up more than 1gb isn't so great though. Divx is the choice for now; a movie in 700x400 takes less than 700mb. Divx requires a better processor; 300Mhz is a good start. Another problem with it is that there isn't yet a native Linux player; avifile uses Windows DLLs to be able to play.
Thanks to open-sourcing of Divx at Project Mayo, a Linux player will be available too.
I don't have a TV, in the last year I saw more movies on PC than TV. I do have a TV tuner with remote control which I use from time to time.
If you don't wanna miss a show/movie and you're busy, set it to record a channel at a certain time (make sure you have plenty of space) and watch it later. Or do some Movie Making on your Linux Box.
I'll let you now enjoy your Linux desktop. Maybe you even show it to a friend. You can happily use it and forget about Windows (read On becoming a total Linux user). English knowledge isn't a requirement, as you see from my screenshots. We continue to improve GNOME support for Romanian. Visit the GNOME translation project to see how well your language is supported.
If you are new to Linux, see my previous article showing how to customize GNOME and stay tuned to Linux as a Video Desktop.
And finally, don't forget that Linux and applications like the ones I've talked about were done by volunteers. Feel free to join ;-)
In the lower levels of the Ontario Science Center in Toronto, Canada, there is a wide circular device made of thin rods of steel. Curious bystanders can take billiard balls, put there for that purpose, and let them loose on the machine. The balls whiz along their rails, richocheting off pins, clanging through wind chimes, grabbed by counterweighted arms and lifted towards the ceiling. At several places the balls chose one rail or another purely at random. How is it that a construct not powered in any way, laid out in a rigid pattern, still produces unexpected results?
Writing programs that use random numbers requires an understanding of error estimation, probability theory, statistics and other advanced numeric disciplines.
Bunk.
Random numbers are about getting your programs to do the unexpected without a core dump being involved. They're about having fun.
Computers do not use "real world" random numbers. Like the
billiard-ball machine, computers are rigid, constrained by rules and logical
behaviour. For a computer to generate truly random numbers, it would
have to choose numbers by examining real world events. In the early
days, people might roll some 10-sided dice and compose a list of digits
for a program to use.
Unfortunately real-world random numbers can be unexpectedly biased. As the old saying goes, "the real world is a special case." Instead, computers rely on mathematics to generate uniformly distributed (that is, random but not too random) numbers. They are "pseudo-random", generated by mathematic functions which create a seemingly non-repeating sequence. Over time, the numbers in the sequence will reliably occur equally often, with no one number being favoured over another.
The Linux standard C library (stdlib.h) has two built-in random number functions. The first, rand(), returns a random integer between 0 and RAND_MAX. If we type
printf( " rand() is %d\n", rand() );
printf( " rand() is %d\n", rand() );
printf( " rand() is %d\n", rand() );
rand() will return values like
rand() is 1750354891
rand() is 2140807809
rand() is 1844326400
Each invocation will return a new, randomly chosen positive integer number.
The other standard library function, random(), returns a positive long integer. On Linux, both integer and long integer numbers are the same size. random() has some other properties that are discussed below.
There are also older, obsolete functions to produce random numbers
* drand48/erand48 return a random double between 0..1.
* lrand48/nrand48 return a random long between 0 and 2^31.
* mrand48/jrand48 return a signed random long.
These are provided for backward compatibility with other flavours of UNIX.
rand() and random() are, of course, totally useless as they appear and are rarely called directly. It's not often we're looking for a number number between 0 and a really big number: the numbers need to apply to actually problems with specific ranges of alternatives. To tame rand(), its value must be scaled to a more useful range such as between 1 and some specific maximum. The modulus (%) operator works well: when a number is divided, the remainder is between 0 and 1 less than the original number. Adding 1 to the modulus result gives the range we're looking for.
int rnd( int max ) {
return (rand() % max) + 1;
}
This one line function will return numbers between 1 and a specified maximum. rnd(10) will return numbers between 1 and 10, rnd(50) will return numbers between 1 and 50. Real life events can be simulated by assigning numbers for different outcomes. Flipping a coin is rnd(2)==1 for heads, rnd(2)==2 for tails. Rolling a pair of dice is rnd(6)+rnd(6).
The rand() discussion in the Linux manual recommends that you take the "upper bits" (that is, use division instead of modulus) because they tend to be more random. However, the rnd() function above is suitably random for most applications.
The following test program generates 100 numbers between 1 and 10, counting how often each number comes up in the sequence. If the numbers were perfectly uniform, they would appear 10 times each.
int graph[11];
int i;
for (i=1; i<=10; i++)
graph[i] = 0;
for (i=1; i<=100; i++)
graph[ rnd(10) ]++;
printf( "for rnd(), graph[1..10] is " );
for (i=1; i<=10; i++)
printf( "%d " , graph[i] );
printf( "\n" );
When we run this routine, we get the following:
for rnd(), graph[1..10] is 7 12 9 8 14 9 16 5 11 9
Linux's rand() function goes to great efforts to generate high-quality random numbers and therefore uses a significant amount of CPU time. If you need to generate a lot mediocre quality random numbers quickly, you can use a function like this:
unsigned int seed = 0;
int fast_rnd( int max ) {
unsigned int offset = 12923;
unsigned int multiplier = 4079;
seed = seed * multiplier + offset;
return (int)(seed % max) + 1;
}
This function sacrifices accuracy for speed: it will produce random numbers not quite as mathematically uniform as rnd(), but it uses only a few short calculations. Ideally, the offset and multiplier should be prime numbers so that fewer numbers will be favoured over others.
Replacing rnd with fast_rnd() in the test functions still gives a reasonable approximation of rand() with
for fast_rnd(), graph[1..10] is 11 4 4 1 8 8 5 7 6 5
A seed is the initial value given to a random number generator
to produce the first random number. If you set
the seed to a certain value, the sequence of numbers will always repeat,
starting with the same number. If you are writing a game, for example,
you can set the seed to a specific value and use the fast_rnd() to position
enemies in the same place each time without actually having to save any
location information.
seed = room_number;
num_enemy = fast_rnd( 5 );
for ( enemy=1; enemy<=num_enemy; enemy++ ) {
enemy_type[enemy] = fast_rnd( 6
);
enemy_horizontal[enemy] = fast_rnd(
1024 );
enemy_vertical[enemy] = fast_rnd(
768 );
}
The seed for the Linux rand() function is set by srand(). For example,
srand( 4 );
will set the rand() seed to 4.
There are two ways to control the sequence with the other Linux function, random(). First, srandom(), like srand(), will set a seed for random().
Second, if you need greater precision, Linux provides two functions to control the speed and precision of random(). With initstate(), you can give random() both a seed and a buffer for keeping the intermediate function result. The buffer can be 8, 32, 64, 128 or 256 bytes in size. Larger buffers will give better random numbers but will take longer to calculate as a result.
char state[256];
/* 256 byte buffer */
unsigned int seed = 1;
/* initial seed of 1 */
initstate( seed, state, 256 );
printf( "using a 256 byte state, we get %d\n", random()
);
printf( "using a 256 byte state, we get %d\n", random()
);
initstate( seed, state, 256 );
printf( "resetting the state, we get %d\n", random() );
gives
using a 256 byte state, we get 510644794
using a 256 byte state, we get 625058908
resetting the state, we get 510644794
You can switch random() states with setstate(), followed by srandom()
to initialize the seed to a specific value.
setstate() always returns a pointer to the previous state.
oldstate = setstate( newstate );
Unless you change the seed when your program starts, your random numbers will always be the same. To create changing random sequences, the seed should be set to some value outside of the program or users control. Using the time code returned by time.h's time() is a good choice.
srand( time( NULL ) );
Since the time is always changing, this will give your program a new sequence of random numbers each time it begins execution.
One of the classic gaming problems that seems to stump many people
is shuffling, changing the order of items in a list. While I was
at university, the Computer Center there faced the task of sorting a list
of names. Their solution was to print out the names on paper, cut
the paper with scissors, and pull the slips of paper from a bucket and
retype them into the computer.
So what is the best approach to shuffling a list? Cutting up a print out? Dubious. Exchanging random items a few thousand times? Effective, but slow and it doesn't guarantee that all items will have a chance to be moved. Instead, take each item in the list and exchange it with some other item. For example, suppose we have a list of 52 playing cards represented by the numbers 0 to 51. To shuffle the cards, we'd do the following:
int deck[ 52 ];
int newpos;
int savecard;
int i;
for ( i=0; i<52; i++ )
deck[i] = i;
printf( "Deck was " );
for ( i=0; i<52; i++ )
printf( "%d ", deck[i] );
printf( "\n" );
for ( i=0; i<52; i++ ) {
newpos = rnd(52)-1;
savecard = deck[i];
deck[i] = deck[newpos];
deck[newpos] = savecard;
}
printf( "Deck is " );
for ( i=0; i<52; i++ )
printf( "%d ", deck[i] );
printf( "\n" );
The results give us a before and after picture of the deck:
Deck was 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
44 45 46 47 48 49 50 51
Deck is 35 48 34 13 6 11 49 41 1 32 23 3 16 43 42 18 28
26 25 15 7 27 5 29 44 2 47 38 39 50 31 17 8 14 22 36 12 30 33 10 45 21
46 19 24 9 51 20 4 37 0 40
People acquainted with statistics know that many of real life events
do not happen with a uniform pattern. The first major repair for
a car, for example, might happen between 5 and 9 years of after purchase,
but it might be most common around the 7th year. Any year in the
range is likely, but its most likely to be in the middle of the range.
Small unexpected events like these occur in a bell curve shape (called a normal distribution in statistics). Creating random numbers that conform to such a complex shape may seem like a duanting task, but it really isn't. Since our rnd() function already produces nicely uniform "unexpected" events, we don't need a statistics textbook formula to generate normally distributed random numbers. All we need to do is call rnd() a few times and take the average, simulating a normal distribution.
int normal_rnd( int max ) {
return (rnd( max ) + rnd( max ) + rnd( max ) + rnd(
max ) +
rnd( max ) + rnd(
max ) + rnd( max ) + rnd( max ) ) / 8;
}
Using normal_rnd() in the test function, we get values that are clustered at the mid-point between 1 and max:
for normal_rnd(), graph[1..10] is 0 0 4 26 37 23 10 0 0 0
Normal random numbers can be used to make a game more life-like, making enemy behaviour less erratic.
For numbers skewed toward the low end of the range, we can create a low_rnd() which favours numbers near 1.
int low_rnd( int max ) {
int candidate;
candidate = rnd( max );
if ( rnd( 2 ) == 1 )
return candidate;
else if ( max > 1 )
return low_rnd( max
/ 2 );
else
return 1;
}
In each recursion, low_rnd() splits the range in half, favoring the lower half of the range. By deducting a low random number from the top of the range, we could write a corresponding high_rnd() favoring numbers near the max:
int high_rnd( int max ) {
return max - low_rnd( max ) + 1;
}
The skewing is easily seen when using the test program:
for low_rnd(), graph[1..10] is 36 15 11 8 9 3 4 3 3 8
for high_rnd(), graph[1..10] is 4 5 8 5 4 10 6 10 14 34
Arbitrary branches in logic can be done with a odds() function.
int odds( int percent ) {
if ( percent <=
0 )
return
0;
else if ( percent
> 100 )
return
1;
else if ( rnd(
100 ) <= percent )
return
1;
return 0;
}
This function is true the specified percentage of the time making it easy to incorporate into an if statement.
if ( odds( 50 ) )
printf( "The cave did not collapse!\n" )
else
printf( "Ouch! You are squashed beneath a mountain
of boulders.\n" );
The standard C library rand() and random() functions provide a program with uniformly distributed random numbers. The sequence and precision can be controlled by other library functions and the distribution of numbers can be altered by simple functions. Random numbers can add unpredictability to a program and are, of course, the backbone to exciting play in computer games.
Bryan Brunton is the creator of the Merchant Empires Project. Merchant Empires is a multiplayer, web-based game of space exploration and economic competition. It is a game of strategy, role-playing, combat, and diplomacy. Merchant Empires is based on the venerable BBS game Tradewars. In the article below, Bryan Brunton is interviewed about his experiences in bringing Merchant Empires to life.
Q: Why did you write ME?
A: A number of reasons. First, I wanted to see if it could be done. I have always been a fan of space based strategy games and I have always wanted to write one. Although I knew that the efforts of bringing the idea to completion would be at times tedious, I didn't care. Secondly, I ran across a game called Space Merchant which is a closed-source, ASP-based implementation of Tradewars, and I was appalled at how badly it had been done. In my opinion, there are many things wrong with the Space Merchant implementation but one thing really struck me as ridiculous: when playing Space Merchant, occasionally an error screen would pop up that said, "Command not processed due to an Error Storm. Please log out and try again." The utter inanity of the the concept of an "Error Storm" and that someone was attempting to pass that explanation off as rational was, to me, hilarious. I said to myself, "Tradewars deserves better than this." However, at the same time, I don't want to overly disregard the thought and effort that went into Space Merchant. The developers of SM deserve a lot of credit for their work.
Q: What software have you used to bring ME to life?
A: Here is a brief summary of the open source software used in ME:
- Apache
- Any webserver that supports PHP could be used.
- PostgreSQL
- PHP
- PHPLIB
- This libary provides classes that simplify PHP database access and session tracking.
- Python
- The first version of ME was written entirely in Python. Due to performance considerations, I switched to PHP. Parts of ME remain in Python.
- PygreSQL
- The ME event processor and map creator gather and update ME data that is located on a PostgreSQL server using these libraries.
- Medusa Asyncronous Network Libraries
- Medusa is used in the ME event processor. These libraries provide telnet access to the ME event processor.
- The ME event processor and map creator gather and update ME data that is located on a PostgreSQL server using these libraries.
- KDevelop
- KDevelop is a great editor for HTML/PHP code. I will probably be purchasing the new PHP IDE from Zend.
- Gimp
- Almost every ME image has been created with this excellent tool.
Q: Many of the ME players tell me that the ME site has been, at times, less than stable. What problems have you run across while developing ME?
A: I ran across a number of bugs and gotchas. The pre-configured scalability of the operating system itself and applications such as Apache and PostgreSQL in most Linux distributions is really quite horrible. In my opinion, pre-configured Linux does not provide a stable platform for a medium traffic, database backed website (Apache + PHP + PHPLIB + PostgreSQL). And when I say pre-configured, I mean as installed on the average PC from any of the popular distro CDs.
Here are a few of the problems that I have run across (most of these caused major headaches):
A: The stateless void of HTML is certainly the last place a player wants to be when, potentially, an enemy vessel could be pounding him into space dust. But a browser based gaming environment has advantages that I value. I looked at a number of similarly directed projects before writing ME. Many of them had stalled or the developers had spent six months time writing a server and client with no playable game to show for their efforts. I wanted to spend my time immediately writing game code. Spending untold hours writing a scalable multiplayer game server was (1) beyond my ability and (2) boring. Also, I like the lowest common denominator factor involved in playing ME. All you need is a web browser that supports javascript. You can have access to and play ME from a far greater number of places than a game that requires client installation and configuration. As far as what makes a good game, I have always enjoyed intelligent turn-based game play, not frames per second.
Q: The gaming industry as a whole has been very silent concerning Merchant Empires. Recently, when questioning one industry representative about ME and his company's initiatives in bringing games like ME to the marketplace, we received nothing but silence and utter denials of any involvement. What commercial interest has been shown in ME and what future do you see for the "resurrected-from-the-dead, BBS2HTML" gaming market?
A: There is no commercial interest. I despise banner ads. The Merchant Empires site that I run will never use banner ads. This means that I can probably never afford to purchase additional bandwidth to host ME (it is currently run on a friend's 768K DSL line). There is always the chance that a well funded organization that wants the honor and privilege of sponsering ME could provide additional bandwidth. One side note on DSL: while it is great that such cheap bandwidth can be brought to the masses, the reliability of DSL (as profided by QWest in the Colorado Springs, US area) is attrocious. Only a company in monopolistic control of the market, as QWEST is, can afford to provide such lousy service.
Q: How popular is ME?
A: Over 7,000 people have created users. ME has a loyal group of a couple hundred players that play very regularly. In my opinion, the game is somewhat limited in its playability due to its simplistic economic and political models. I would like to flesh out these areas so it might have a greater appeal. The possibility for role-playing is very limited beyond pirating and player-killing.
I enjoy hosting ME because there is something that is just cool about writing a piece of software that gets frequent use and can potentially generate lots of data. I don't know why but I just like lots of data. The ME database can grow to over 100 megs before I delete data from old games and players.
Q: What do the ME players most enjoy about the game?
A: The players seem to most enjoy the politics of planning ways to kill each other. The same is true for most online games that involve combat. In ME, players pick sides and then organize toward the goal of conquering galaxies and then the entire game universe. It is fascinating to watch the organizational approaches that different alliances take along a autocratic to democratic continuum. Many of the ME players are also programmers who provide development assistance. The players definitely enjoy watching the game grow and improve.
Q: What plans do you have for improving ME?
A: IMO, Scalable Vector Graphics (SVG) are the future of the web. SVG is essentially an open implemenation of Flash. SVG could potentially be more powerful because it is based on open standards such as XML and Javascript. It is unfortunate that browser-based SVG support on Linux is limited to a some barely functional code in the MathML-SVG build of Mozilla. On the Windows and Mac side, Adobe provides a high quality SVG plug-in. But as Linux is my current desktop of choice, I am currently caught in this SVG dilemna.
There are a few big features that I want to put into ME. I'd like to implement a java applet that could provide realtime game information. I would also like to introduce computer controlled ships and planets. Eventually, a computer controlled Imperium (the police in ME) will play a larger part in the game.
I would also like to remove ME's dependency on PostgreSQL. I have nothing against PostgreSQL but other people have inquired about running ME with MySQL. Currently most of ME's database access is through data classes provided by PHPLIB so removing the few PostgreSQLisms in the code wouldn't require much work.
I am planning on a few major changes in ME 2.0. I want to have hexagon based maps (currently sectors are square). But to do this right, I need SVG. I want to implement a whole new trading model where there are literally hundreds of different goods and contract based trading agreements. I'd like to do away with ports as separate entities, making ports simply a feature of planets. I would like to replace ME's current simple experience point advancement model with one that is skilled based. These and other ideas are discussed at the ME Wish List over at SourceForge.
Q: It has been noted by your players that your code sucks. Please don't take this the wrong way, but I really must agree. Before this interview, I was looking through the code to your event processor, the server side Python process that handles important game events, and I noticed that all of the program's intelligence is crammed into your networking loop.
A: You should first consider that I wrote Merchant Empires as fast as I possibly could. My approach was very simple: look at a Space Merchant screen shot and reproduce it as quickly as possible. Also, writing Merchant Empires was quite intentionally a learning process for myself. Parts of Merchant Empires use C++, PHP, and Python. While I had limited C++ experience, I had never used, and knew nothing about, either PHP or Python. I wanted to learn both of these languages. Parts of Merchant Empires, such as the inconsistent use of CSS and the combat functionality, are from a coding standpoint barely at the proof of concept stage. At the time that I wrote the event processor, I barely understood what a select networking loop was. Today, I have forgotten everything that I learned on that concept and now I am just pleased that that particular piece of code still works.
Q: So your code is pretty rough around the edges. Have you considering using any recursive programming techniques to spruce it up?
A: Recursion, if properly used, is an awesomely powerful programming tool. However, I have never actually used it. I thought that by interviewing myself for this article (which is a somewhat recursive process), I could introduce myself to the concept of recursion, and if I like it, consider using it in the future.










Courtesy Linux Today, where you can read all the latest Help Dex cartoons.
[Shane invites your suggestions for future HelpDex cartoons. What do you think is funny about the Linux world? Send him your ideas and let him expand on them. His address is shane_collinge@yahoo.com Suggesters will be acknowledged in the cartoon unless you request not to be. -Mike.]
To advertise the efforts of http://www.dict.org and to provide the means by which any Linux user regardless of experience, can install a functional dictionary system either for local or network use.
I have been using Linux exclusively as my operating system for over three years now. One of the very few things I miss about "that other operating system" is the easy availability of cheap or even free versions of commercial encyclopedias and dictionaries.
So when I installed a recent version of S.u.S.E. linux I was both surprised and happy to find a package called Kdict had been installed on my machine. Reading the documentation that came with the package revealed that the program was only a front end to another program, and that though it is possible to install a dictionary server locally, if I wanted to do so I would have to get everything else I need from the Internet.
Note:- This section paraphrases the contents of ANNOUNCE in the dict distribution.
The DICT Development Group (www.dict.org) have both developed a Dictionary Server Protocol (as described in RFC 2229), client/server software in C as well as clients in other languages such as Java and Perl, and converted various freely available dictionaries for use with their software.
The Dictionary Server Protocol (DICT) is a TCP transaction based query/response protocol that allows a client to access dictionary definitions from a set of natural language dictionary databases.
dict(1) is a client which can access DICT servers from the command line.
dictd(8) is a server which supports the DICT protocol.
dictzip(1) is a compression program which creates compressed files in the gzip format (see RFC 1952). However, unlike gzip(1), dictzip(1) compresses the file in pieces and stores an index to the pieces in the gzip header. This allows random access to the file at the granularity of the compressed pieces (currently about 64kB) while maintaining good compression ratios (within 5% of the expected ratio for dictionary data). dictd(8) uses files stored in this format.
Available in separate .tar.gz
files are the data, conversion programs, and formatted output for
several freely-distributable dictionaries. For any single dictionary,
the terms for commercial distribution may be different from the terms
for non-commercial distribution -- be sure to read the copyright and
licensing information at the top of each database file. Below are
approximate sizes for the databases, showing the number of headwords
in each, and the space required to store the database:
|
Database |
Headwords |
Index |
Data |
Uncompressed |
|
web1913 |
185399 |
3438 kB |
11 MB |
30 MB |
|
wn |
121967 |
2427 kB |
7142 kB |
21 MB |
|
gazetteer |
52994 |
1087 kB |
1754 kB |
8351 kB |
|
jargon |
2135 |
38 kB |
536 kB |
1248 kB |
|
foldoc |
11508 |
220 kB |
1759 kB |
4275 kB |
|
elements |
131 |
2 kB |
12 kB |
38 kB |
|
easton |
3968 |
64 kB |
1077 kB |
2648 kB |
|
hitchcock |
2619 |
34 kB |
33 kB |
85 kB |
|
www |
587 |
8 kB |
58 kB |
135 kB |
All of these compressed databases and indices can be stored in approximately 32MB of disk space.
Additionally there are a number of bi-lingual dictionaries to help with translation. Though I have not looked at these judging from their different sizes some will be more useful than others (i.e. English to Welsh is unfortunately not very good, whereas English to German is probably quite useful).
All the dictionaries seem to be under constant development so interested people should keep up with latest developments.
The Oxford English Dictionary this is not! It is however a very pleasant dictionary. It seems to be an American version of one of those Dictionary/Encyclopedias, so common at the time of its writing. Quite often in a definition you will find a poetic quote and it really is very informative and pleasant to use.
This dictionary seems to be under constant development. The aim seems to be to provide definitions of all the words people want to have definitions for! In practice it seems to miss some obvious words such as "with" and "without". I guess the idea is to simply provide necessary update to the definitions found in Webster's. Unfortunately this dictionary is neither as informative or as pleasant as Webster's. If you need a more up to date dictionary it is necessary.
FOLDOC is a searchable dictionary of acronyms, jargon, programming languages, tools, architecture, operating systems, networking, theory, conventions, standards, mathematics, telecoms, electronics, institutions, companies, projects, products, history, in fact anything to do with computing. The dictionary is Copyright Denis Howe 1993, 1997.
This is probably only of interest to people wanting information about America. The original U.S. Gazetteer Place and Zipcode Files are provided by the U.S. Census Bureau and are in the Public Domain.
These Dictionary topics are from M.G. Easton M.A., D.D., Illustrated Bible Dictionary, Third Edition, published by Thomas Nelson, 1897. Due to the nature of etext, the illustrated portion of the Dictionary has not been included.
This dictionary is from "Hitchcock's New and Complete Analysis of the Holy Bible," published in the late 1800s. It contains more than 2,500 Bible and Bible-related proper names and their meanings. Some Hebrew words of uncertain meaning have been left out. It is out of copyright, so feel free to copy and distribute it. I pray it will help in your study of God's Word. --Brad Haugaard
This dictionary database was created by Jay Kominek <jfk at acm.org>.
This somewhat typically short sighted view of the World (sorry I love America, I lived there for a while - its great, but it is not ALL THE WORLD!), really only becomes useful if you look in the index file and see that there are Appendix's, these are though of limited use to normal people, who think that the world ends at their keyboard.
The Jargon File is a comprehensive compendium of hacker slang illuminating many aspects of hackish tradition, folklore, and humor. This bears remarkable similarity to FOLDOC above.
_The Devil's Dictionary_ was begun in a weekly paper in 1881, and was continued in a desultory way at long intervals until 1906. In that year a large part of it was published in covers with the title _The Cynic's Word Book_, a name which the author had not the power to reject or happiness to approve. Users of the fortune program will already have some familiarity with this ;-).
Who Was Who: 5000 B. C. to Date: Biographical Dictionary of the
Famous and Those Who Wanted to Be, edited by Irwin L. Gordon
OTHER DICTIONARIES
A number of other dictionaries have been made available, see the
dict home page for details. In many cases you may find the
program to convert dictionary data to the format dict
requires has not been written yet ;-(
As mentioned elsewhere, there are a number of translation dictionaries also available (see below).
The links given here were correct at the time of writing. If it is a long time since this paper was published you should visit http://www.dict.org to see what has changed.
Unfortunately installation of the above mentioned software did not go quite as easily as it should have, which partly explains why I am writing this;-).
The first thing you will need is plenty of disk space. The largest dictionary available is Webster's 1913 dictionary, which will need about 85Meg to be re-built in.
Unarchive dictd-1.5.5.tar.gz in the normal manner.
IMPORTANT:- The HTML support has been turned off in this version of dict. You need to turn it back on if you want to take advantage of Kdict.
Load the file dict.c into your favorite editor and remove the comments from line 1069:-
{ "raw", 0, 0, 'r' },
{ "pager", 1, 0, 'P' },
{ "debug", 1, 0, 502 },
{ "html", 0, 0, 503 }, //Remove comments from this line
{ "pipesize", 1, 0, 504 },
{ "client", 1, 0, 505 },
so the file becomes as above.
Now you can run ./configure;make;make install. You
will see a great many warnings produced by the compiler, but at the
end you should have working client, server and compression program
installed.
Unpack the files dict-web1913-1.4.tar.gz and web1913-0.46-a.tar.gz:
$ tar xvzf dict-web1913-1.4.tar.gz
$ tar xvzf web1913-0.46-a.tar.gz
$ cd dict-web1913-1.4
$ mkdir web1913
$ cp ../web1913-0.46-a/* web1913
$ ./configure
$ make
$ make db
Now go make a cup of tea, this takes over an hour on my 133MHz box.
When done, decide on a place for your dictionaries to live and copy
them there, I use /opt/public/dict-dbs as suggested:-
$ mkdir /opt/public/dict-dbs
$ cp web1913.dict.dz /opt/public/dict-dbs
$ cp web1913.index /opt/public/dict-dbs
Grab dict-wn-1.5.tar.gz
It is a great shame that one of the most useful dictionaries is
also the one that refuses to compile correctly. To create a viable
dictionary the original data must be parsed by a program. When you do
make it is this program that is created. Unfortunately
this package uses a Makefile created by ./configure
which does not work. I am unable to correct the automake
procedure but can assure you that the following will work:
$ tar xvzf dict-wn-1.5.tar.gz $ cd dict-wn-1.5 $ ./configure $ gcc -o wnfilter wnfilter.c $ make db
Again this process takes a considerable amount of time ( > 1 hour on my 133MHz). Once complete if you have not already created a directory for your dictionaries do so now and copy the dictionary and its index there:
$ cp wn.dict.dz /opt/public/dict-dbs $ cp wn.index /opt/public/dict-dbs
Grab dict-misc-1.5.tar.gz
$ tar xvzf dict-misc-1.5.tar.gz $ cd dict-misc-1.5 $ ./configure $ make $ make db $ cp easton.dict.dz /opt/public/dict-dbs $ cp easton.index /opt/public/dict-dbs $ cp elements.dict.dz /opt/public/dict-dbs $ cp elements.index /opt/public/dict-dbs $ cp foldoc.dict.dz /opt/public/dict-dbs $ cp foldoc.index /opt/public/dict-dbs $ cp hitchcock.dict.dz /opt/public/dict-dbs $ cp hitchcock.index /opt/public/dict-dbs $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
$ tar xvzf dict-jargon-4.2.0.tar.gz $ cd dict-jargon-4.2.0 $ ./configure $ make $ make db $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
Grab dict-gazetteer-1.3.tar.gz
$ tar xvzf dict-gazetteer-1.3.tar.gz $ cd dict-gazetteer-1.3 $ ./configure $ make $ make db $ cp gazetteer.dict.dz /opt/public/dict-dbs $ cp gazetteer.index /opt/public/dict-dbs
As with the language dictionaries below, the dictionary has already been created for you. Simply unpack this file in your dictionary directory.
Grab http://www.hawklord.uklinux.net/dict/www-1.0.tgz
$ tar xvzf www-1.0.tgz $ cd www-1.0 $ ./configure $ make $ make db $ cp www.dict.dz /opt/public/dict-dbs $ cp www.index /opt/public/dict-dbs
Visit ftp://ftp.dict.org/pub/dict/pre/www.freedict.de/20000906
Installing a language dictionary does not involve re-building the dictionary from original data, so you just need to unpack each file into you dictionary directory.
dictd expects to find the file /etc/dictd.conf,
though an alternative file may be specified on the command line. Each
dictionary needs to be specified in this file so dictd can
find the dictionary and its index. For example if you just want to
use Webster's, WordNet and The Devils Dictionary, then the following
entries will be required (assuming you use /opt/public/dict-dbs
as your dictionary directory):
database Web-1913 { data "/opt/public/dict-dbs/web1913.dict.dz"
index "/opt/public/dict-dbs/web1913.index" }
database wn { data "/opt/public/dict-dbs/wn.dict.dz"
index "/opt/public/dict-dbs/wn.index" }
database devils { data "/opt/public/dict-dbs/devils.dict.dz"
index "/opt/public/dict-dbs/devils.index" }
It seems it is possible to implement user access control and other security measures. I have not tried this. If I were into security issues the current state of the software gives me no reason to trust any security feature it might have. But why anyone would want to restrict access to these dictionaries is completely beyond me, this is stuff any user has a right to use.
You should be aware of a number of security issues if you intend to make dictd available over a local network since not being aware will leave your server vulnerable to a number of possible attacks.
Unless you are installing dictd on a server for a school/college or for some other large network these issues will probably be of no concern to you. If you are installing on such a network then you should already be aware of the issues below.
All these symptoms can occur if a number of users send queries
like MATCH * re . at the same time. Such queries return
the whole database index and each instance will require around 5MB
buffer space on the server.
Possible solutions include limiting the number of connections to the server, limiting the amount of data that can be returned for a single query or limiting the number of simultaneous outstanding searches.
The server can be driven to a complete stand still by any evil minded cracker that wants to connect to the server 1,000,000 times.
To prevent such anti-social behavior simply limit the number of connections based on IP or mask.
If you experience this kind of problem you should make your
logging routines more robust, use strlen and examine
daemon_log.
dict expects to find the file /etc/dict.conf.
This file should contain a line with the name of the machine you wish
to use as your dictd server, though this can be overridden at
the command line.
The current version of dict is a little disappointing as a users front-end for dictd. If all you have is a console and you can't use Kdict then you will just have to get used to dict. The worst thing about dict is that it can trash your console and you will need to take action (such as logging out and back in) to restore the keyboard to normal! This typically occurs if there is a problem with dictd; such as when it is not running and you try to use dict.
Since dict is just a console program, it just sends output to less. So unless you have a very good memory you will need to use `cut and paste' to transfer referenced words or phrases back to the command line.
There is an option to send output to a pager program. I tried the
command dict -html -P lynx luser, the result was not a
happy one! Lynx went mad, referencing random help and configuration
files in a manner that reminded me of certain viruses in MS operating
systems.
Personally I would say if you can avoid using dict directly, avoid it! It is necessary to have it if you want to use Kdict, and you do want to use Kdict.
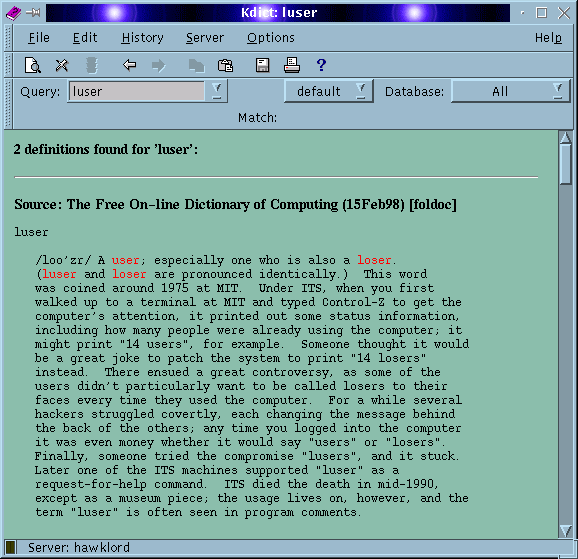
To take full advantage of dict you really need Kdict from http://www.rhrk.uni-kl.de/~gebauerc/kdict. I have used version 0.2 and cannot speak for any other version.
To use Kdict you must turn HTML support back on for dict as described above.
The screen shot above shows Kdict in use. Kdict makes good use of the limited HTML tags provided by dict, and inserts extra tags so that you can easily cross-reference words. Any phrase or word shown in red can be clicked on with the mouse to show its definition.
What makes Kdict so good is the fact that you can use the clipboard to highlight a word from any window on the desktop and paste it into Kdict as a query.
This is a great project that can only get better, so it is a lot like Linux and gnu software in general... Give it your full support!
If you get xscrabble from Matt Chapman's homepage, you can enhance your enjoyment of the game by looking up the definitions of words you don't know, - as the computer beats the sh*t out of you;-).
Both Perl and Python will let you download webpages off of the internet. You can do more than just download webpages, such as ftp, gopher, and connect to other services. Downloading a webpage is just one thing these languages can do.
There are several things the programming language has to do:
This article isn't going to be too long. I commented the Python code.
<!--#include virtual="/lthead.html" -->in your webpage. Various programming languages (like PHP, Perl ASP, Perl Mason, etc) can also include files.
It is assumed you are using a GNU/Linux operating system. Also, I was using Python 1.5.2, which is not the latest version. You might have to do a
chmod 755 LinuxToday.pyon the script to make it executable. [Text version of this listing.]
#!/usr/bin/python
# One obvious thing to do is apply error checking for url download,
# download must contain at least one entry, and we are able to create the
# new file. This will be done later.
### import the web module, string module, regular expression, module
### and the os module
import urllib, string, re, os
### define the new webpage we create and where to get the info
Download_Location = "/tmp/lthead.html"
Url = "http://linuxtoday.com/backend/lthead.txt"
#-----------------------------------------------------------
### Create a web object with the Url
LinuxToday = urllib.urlopen( Url )
### Grab all the info into an array (if big, change to do one line at a time)
Text_Array = LinuxToday.readlines()
New_File = open(Download_Location + "_new", 'w');
New_File.write("<ul>\n")
### Set the default to be invalid
Valid = 0
### Record the number of valid entries
Entry_No = 0;
Entry_Valid = 0
### Setup the defaults
Date = ""
Link = ""
Header = ""
Count = 0
### Create the mattern matching expression
Match = re.compile ("^\&\&")
### Append && to make sure we parse the last entry
Text_Array.append('&&')
### For each line, do the following
for Line in Text_Array :
### If && exists, start from scratch, add last entry
if Match.search(Line) :
### If the current entry is valid and we have skipped the first one,
if (Entry_No > 1) and (Entry_Valid > 0) :
### One thing that Perl does better than Python is the print command. I
### don't like how Python prints (no variable interpolation).
New_File.write('<li> <a href="' + Link + '">' + Header + '</a>. ' + Date + "</li>\n")
## Reset the values to nothing.
Header = ""; Link = ""; Date = ""; Entry_Valid = 0
Count = 0
### Delete whitespace at end of line
Line = string.rstrip(Line)
### If count is equal to 1, header, 2 link, 3 date
if Count == 1: Header = Line
elif Count == 2: Link = Line
elif Count == 3:
Date = Line
### If all fields are done, we have a valid entry
if (Header != "") or (Link != "") or (Date != "") :
Entry_No = Entry_No + 1
Entry_Valid = 1
### Add one to Count
Count = Count + 1
New_File.write("</ul>\n")
New_File.close()
### If we have valid entries, move the new file to the real location
if Entry_No > 0 :
### We could just do:
### os.rename(Download_Location + "_new", Download_Location)
### But here's how to do it with an external command.
Command = "mv " + Download_Location + "_new " + Download_Location
os.system( Command )
#/bin/sh ### Crontab file ### Name the file "Crontab" and execute with "crontab Crontab" ### Download every two hours */2 * * * * /www/Cron/LinuxToday.py >> /www/Cron/out 2>&1
#!/usr/bin/perl
# Copyright Mark Nielsen January 20001
# Copyrighted under the GPL license.
# I am proud of this script.
# I wrote it from scratch with only 2 minor errors when I first tested it.
system ("lynx --source http://www.linuxgazette.com/ftpfiles.txt > /tmp/List.txt");
### Open up the webpage we just downloaded and put it into an array.
open(FILE,'/tmp/List.txt'); my @Lines = <FILE>; close FILE;
### Filter out lines that don't contain magic letters.
my @Lines = grep(($_ =~ /lg\-issue/) || ($_ =~ /\.tar\.gz/), @Lines );
my @Numbers = ();
foreach my $Line (@Lines)
{
## Throw away the stuff to the left
my ($Junk,$Good) = split(/lg\-issue/,$Line,2);
## Throw away the stuff to the right
($Good,$Junk) = split(/\.tar\.gz/,$Good,2);
## If it is a valid number, it is greater than 1, save it
if ($Good > 0) {push (@Numbers,$Good);}
}
### Sort the numbers and pop off the highest
@Numbers = sort {$a<=>$b} @Numbers;
my $Highest = pop @Numbers;
## Create the url we are going to download
my $Url = "http://www.linuxgazette.com/issue$Highest/index.html";
## Download it
system ("lynx --source $Url > /tmp/LG_index.html");
### Open up the index.
open(FILE,"/tmp/LG_index.html"); my @Lines = <FILE>; close FILE;
### Extract out the parts that are between beginning and end of TOC.
my @TOC = ();
my $Count = 0;
my $Start = '<!-- *** BEGIN toc *** -->';
my $End = '<!-- *** END toc *** -->';
foreach my $Line (@Lines)
{
if ($Line =~ /\Q$End\E/) {$Count = 2;}
if ($Count == 1) {push(@TOC, $Line);}
if ($Line =~ /\Q$Start\E/) {$Count = 1;}
}
### Relink all the links to point to the Linux Gazette magazine
my $Relink = "http://www.linuxgazette.com/issue$Highest/";
grep($_ =~ s/HREF\=\"/HREF\=\"$Relink/g, @TOC);
### Save the output
open(FILE,">/tmp/TOC.html"); print FILE @TOC; close FILE;
### Done!
#!/usr/bin/perl
# Copyright Mark Nielsen January 20001
# Copyright under the GPL license.
system ("lynx --source http://www.debian.org/News/weekly/index.html > /tmp/List2.txt");
### Open up the webpage we just downloaded and put it into an array.
open(FILE,'/tmp/List2.txt'); my @Lines = <FILE>; close FILE;
### Extract out the parts that are between beginning and end of TOC.
my @TOC = ();
my $Count = 0;
my $Start = 'Recent issues of Debian Weekly News';
my $End = '</p>';
foreach my $Line (@Lines)
{
if (($Line =~ /\Q$End\E/i) && ($Count > 0)) {$Count = 2;}
if ($Count == 1) {push(@TOC, $Line);}
if ($Line =~ /^\Q$Start\E/i) {$Count = 1;}
}
### Relink all the links to point to the DWN
my $Relink = "http://www.debian.org/News/weekly/";
grep($_ =~ s/HREF\=\"/HREF\=\"$Relink/ig, @TOC);
grep($_ =~ s/\"\>/\" target=_external\>/ig, @TOC);
### Save the output
open(FILE,">/tmp/D.html"); print FILE @TOC; close FILE;
### Done!
Python rules as a programming language. I found it very easy to use the Python modules. It seems like the Python module for handling webpages is easier than the LWP module in Perl. Because of the many possibilities of Python, I plan on creating a Python script which will download many webpages at the same time using Python's threading capbilities.
The goal of this Perl script is to just delete the hard drive at /dev/hdb (the slave drive on the Primary IDE controller) since I have a hard drive removeable kit there. I want it to delete all partitions, create one partition that takes up the whole hard drive, and then fill up the hard drive with garbage data (including some random encrypted data just to ruin a hacker's day trying to find out what the data is).
I remember researching many different options to alter partitions on a hard drive, and doing it manually yielded the best results. I had used a Perl Expect script to automate the fdisk program (fdisk partitions hard drives in Linux) in the past, and I decided to continue to do it that way. I believe there are better alternatives for the simple task of deleting all the partitions, like sfdisk and others, but if one solution covers all possibilities with 100% power and flexibility, I usually just stick to one way of doing things so that I don't have to remember too many things and if it ever gets more complicated, I don't have to learn anything new.
Thus, I used Expect code to simulate a user typing in the commands for fdisk. The Expect code deleted all the partitions and then it created one big partition.
Just deleting partitions isn't enough to delete the data. I want to overwrite all old data with garbage to make sure the previous data was deleted. I used sfdisk to get the size of the partition that fdisk created. Then, I created a loop which would continuously print garbage data until the amount printed was equal or greater than the size of the partition.
I created random binary data using the random function and "chr" function in Perl. Then, I encrypted the random data using the Perl Blowfish module. If someone manages to decrypt the data, it will still look like garbage and confuse them. I wanted to encrypt the data so that it didn't look purely random in a mathematical sense.
This was easy. I just used a simple "mkfs" command.
There are a lot of things I need to enhance to make this script more user friendly. There should be a lot more error checking, considering how dangerous this script is, and prompts to ask a user if they really want to do so stuff. I am waiting until I restart my MILAS project (which will be written in Python) before I make this script better. It was only to get me through moving from Columbus to the Bay Area.
I have commented a lot of the code, so hopefully a novice Perl programmer can understand most of what I am trying to do. (Text version of this listing)
#!/usr/bin/perl
##### Things to do
# 1. Make sure we create a brand new directory for temporary mounting
# in order to avoid security risks in case someone is logged in.
# 2. Use perl functions to handle a lot of the system calls.
# 3. Let it autodetect hard drives, and floppy drives, and only perform
# actions on unmounted hard drives and floppy drives.
#####
use strict;
use Expect;
use Crypt::Blowfish;
#-----------------------------------------------
my $Junk;
### Set the drive to the slave drive on the Primary IDE controller.
my $Drive = "hdb";
### Let us do a lot of random stuff, and get the last line from the
### /etc/passwd file to make it really random, assuming one person
### has been added to the computer.
my $time = time();
my $Ran = rand($time);
my $Ran = rand(10000000000000);
my $LastLine = `tail -n 1 /etc/passwd`; chomp $LastLine;
$LastLine = substr ($LastLine,0,30);
my $Blowfish_Key = $LastLine . $Ran . $time;
$Blowfish_Key = substr ($Blowfish_Key,0,20);
while (length ($Blowfish_Key) < 56)
{
$Blowfish_Key .= $Ran = rand($time);
}
$Blowfish_Key = substr ($Blowfish_Key,0,56);
### Done making up random key, now create Blowfish Encryption object.
my $Blowfish_Cipher = new Crypt::Blowfish $Blowfish_Key;
#------------------------------------
system "clear";
print "This will wipe out the hard drive on Drive /dev/$Drive\n";
print "Press enter to continue\n";
my $R = <STDIN>;
### Get the list of mounted partitions on the drive we want to wipe out
my @Mounted = `df`;
@Mounted = grep($_ =~ /\/dev\/hdb/, @Mounted);
### Foreach mounted partition, umount it
foreach my $Mount (@Mounted)
{
my ($Partition,$Junk) = split(/\s+/, $Mount,2);
print "Unmounting $Partition\n";
my $Result = system ("umount $Partition");
if ($Result > 0)
{
print "ERROR, unable to umount $Partition, aborting Script, Error = $Result\n";
exit;
}
}
### Start the expect script, which will simulate someone doing this
### commands manually.
my $Fdisk = Expect->spawn("/sbin/fdisk /dev/$Drive");
### Get a list of mounted partitions by printing the partition table
print $Fdisk "p\n";
my $match=$Fdisk->expect(30,"Device Boot Start");
my $Temp = $Fdisk->exp_after();
my @Temp = split(/\n/, $Temp);
## Get the lines that tell us about the partitions
my @Partitions = grep($_ =~ /^\/dev\//, @Temp);
## Foreach line, delete the partition
foreach my $Line (reverse @Partitions)
{
## Get the /dev/hdb part, and its number
my ($Part,$Junk) = split(/[\t ]/, $Line,2);
my $No = $Part;
$No =~ s/^\/dev\/$Drive//;
print "Deleting no $Drive $No\n";
## Delete command
print $Fdisk "d\n";
$match=$Fdisk->expect(30,"Partition number");
## Which partition number to delete
print $Fdisk "$No\n";
$match=$Fdisk->expect(30,"Command (m for help):");
}
$Fdisk->clear_accum();
### If we had partitions, write changes, or otherwise, just end it
if (@Partitions < 1) {print $Fdisk "q\n"; $Fdisk->expect(2,":");}
else
{
print $Fdisk "w\n";
$Fdisk->expect(30,"Command (m for help):");
}
#-------------------------------
## Get the geometry of the hard drive
my $Geometry = `/sbin/sfdisk -g /dev/$Drive`;
my ($Junk, $Cyl, $Junk2, $Head, $Junk3, $Sector,@Junk) = split(/\s+/,$Geometry);
if ($Cyl < 1)
{print "ERROR: Unable to figure out cylinders for drive. aborting\n"; exit;}
### Create a new expect script to simulate a person using fdisk
my $Fdisk = Expect->spawn("/sbin/fdisk /dev/$Drive");
#### Tell fdisk to create new partition
print $Fdisk "n\n";
$Fdisk->expect(5,"primary");
### Tell it the new partition should be a primary partition
print $Fdisk "p\n";
$Fdisk->expect(5,":");
### Which partition, number 1
print $Fdisk "1\n";
$Fdisk->expect(5,":");
### Start at cylinder 1
print $Fdisk "1\n";
$Fdisk->expect(5,":");
### Go to the end
print $Fdisk "$Cyl\n";
$Fdisk->expect(5,":");
### Write and save
print $Fdisk "w\n";
$Fdisk->expect(30,"Command (m for help):");
#------------------------------------------
### Format the partition and mount it
my $Partition = "/dev/$Drive" . "1";
my $Result = system ("mkfs -t ext2 $Partition");
if ($Result > 0) {print "Error making partition, aborting.\n"; exit;}
### There should be better error checking here
system "umount /tmp/WIPE_IT";
system "rm -rf /tmp/WIPE_IT";
system "mkdir -p /tmp/WIPE_IT";
system "chmod 700 /tmp/WIPE_IT";
## See if we can mount the new partition.
my $Result = system ("mount $Partition /tmp/WIPE_IT");
if ($Result > 0) {print "Error mounting drive, aborting.\n"; exit;}
system "chmod 700 /tmp/WIPE_IT";
#--------------------------------
### Now create the file and stop when we hit the size.
my $Count = 0;
my $Written_Size = 0;
### Open up a new file.
open(FILE,">>/tmp/WIPE_IT/Message.txt");
### If someone actually wants to screw around with your hard drive,
### let us play with them and waste their time by adding a teaser.
my $Ran = rand 259200000; # between now and ten years ago (approx)
($Ran, $Junk) = split(/\./, $Ran, 2);
## New date minus random number of seconds
my $Date = `date --date '-$Ran seconds'`;
print FILE "DATE CREATED $Date\n";
my $Ran = rand 50;
($Ran, $Junk) = split(/\./, $Ran, 2);
$Ran = $Ran + 10;
print FILE "This document is extremely secure. It is a violation to let
any unauthorized persons read it. Known password holders need to
apply Method $Ran in order to decrypt binary data.\n";
### Create random number plus 25000
my $Ran = rand 25000;
($Ran, $Junk) = split(/\./, $Ran, 2);
$Ran = $Ran + 25000;
### Create an array of numbers which we will use most of the time.
my @Blank = (1..$Ran);
### Take the array and make into a string.
my $Blank = "@Blank";
### Empty the array to free up memory.
@Blank = ();
my $B_Length = length $Blank;
### Let us get the amount of real space we have for the partition
my @Temp = `df`;
@Temp = grep($_ =~ /^$Partition/, @Temp);
my $Line = $Temp[0];
my ($Junk,$Blocks,@Junk) = split(/\s+/, $Line,4);
### We are assuming 1k blocks.
my $Size = $Blocks*1000;
## While the file we have written is less than the size of the
## partition, print some more data.
while ($Written_Size < $Size)
{
$Count++;
### 9 out of ten times, we just want to print blank spaces to hurry
### up printing. One out of ten times, print garbage binary.
my $Ran = rand (10);
if ($Ran > 1)
{
print FILE $Blank;
$Written_Size = $Written_Size + $B_Length;
}
else
{
## This part makes a long string (upto 10000 bytes) of random data.
my $Garbage = "";
my $Length = rand(10000);
($Length, $Junk) = split(/\./, $Length, 2);
for (my $i = 0; $i < $Length; $i++)
{
my $Ran = rand 256;
($Ran, $Junk) = split(/\./, $Ran, 2);
$Garbage .= chr $Ran;
}
## This parts encrypts the random data 8 bytes at a time.
my $Temp = $Garbage;
my $Encrypted = "";
while (length $Temp > 0)
{
while (length $Temp < 8) {$Temp .= "\t";}
my $Temp2 = $Blowfish_Cipher->encrypt(substr($Temp,0,8));
$Encrypted .= $Temp2;
if (length $Temp > 8) {$Temp = substr($Temp,8);} else {$Temp = "";}
}
### Print the encrypted random data to file.
print FILE $Encrypted;
$Length = length $Encrypted;
$Written_Size = $Written_Size + $Length;
my $Rest = $Size - $Written_Size;
print "$Size - $Written_Size = $Rest to go\n";
}
### At every 500 prints, start saving to a new file.
if ($Count =~ /500$/)
{
close FILE;
open(FILE,">>/tmp/WIPE_IT/$Count");
}
}
close FILE;
#----------------------------------------------------
my $Result = system ("umount $Partition");
if ($Result > 0) {print "Error unmounting partition $Partition, aborting.\n"; exit; }
### Let us reformat the partition. Doesn't delete data, just removes it
### from the directory.
my $Result = system ("mkfs -t ext2 $Partition");
if ($Result > 0) {print "Error making partition, aborting.\n"; exit;}
I don't understand the complete complexity of hard drives, so I am not sure if there are residual data left on the hard drive. For my purposes, and my level of security, it does exactly what I need. As I develop MILAS more, I am sure there will be tighter checks and enhancements to delete all data off of a hard drive.
I tend to look forward in time trying to anticipate things which might be needed in the future, which always causes a programmer to work more than is required for the project at hand. However, the mood struck me, and I like the direction the script is going, and so, it doesn't bother me to write up this article on an airplane flight. Making something cool doesn't wear me out, unlike having to do work for someone else, which is real work.
[You can also use /dev/random or /dev/urandom to overwrite a disk. See
The Answer Gang: "Classified Disk - Low-level Format" in issue 60. But it doesn't do encryption. -Mike.]
[Editor's note: Linux users are currently migrating from kernel series 2.2 to 2.4. Linux 2.4 includes vastly improved USB support. Most distributions and users have not yet made the switch, but will during the next several months. The steps below were written for kernel 2.2.8. See the links in the References section below (especially the Linux-USB Guide), for the latest information on getting USB to work with Linux.Also, the 2.4 kernel includes PCMCIA support, so try that first. Those drivers don't work for everyone; if you're one of the unlucky few, get the pcmcia-cs package.
The problem with my laptop was the fact it was using pcmcia devices. I found out later that I had to download pcmcia-cs and install it after I installed the new kernel 2.2.18.
Getting USB to work on my laptop meant I had to do several things,
## change to the src directory for the linux kernel ## for xconfig, I selected the usb options and VESA VGA graphics console ## under console drivers for my laptop make xconfig make clean make dep make bzImage make install make modules make modules_installHere are the steps I used to install pcmcia-cs.
tar -zxvf pcmcia-cs-3.1.23.tar.gz ### Make sure you specify the root directory for the new kernel ### mine was /usr/src/linux-2.2.18/linux ### I didn't change the other default options. make config make all ### This puts the modules under /lib/modules/2.2.18 make install
Old configuration.
### Configuration for GNUJobs.com test laptop vga=791 boot=/dev/hda map=/boot/map install=/boot/boot.b prompt timeout=50 default=linux image=/boot/vmlinuz-2.2.12-32 label=linux initrd=/boot/initrd-2.2.12-32.img read-only append="hdc=ide-scsi" # ramdisk_size=40000 root=/dev/hda5New lilo.conf configuration.
### Configuration for GNUJobs.com test laptop
### New kernel installed. Remember to install console drivers
### into new kernels otherwise vga=791 doesn't work.
vga=791
#vga=ask
boot=/dev/hda
map=/boot/map
install=/boot/boot.b
prompt
timeout=50
default=linux_new
image=/boot/vmlinuz-2.2.18
label=linux_new
read-only
append="hdc=ide-scsi"
### /dev/hda5 is root for GNUJobs.com laptop
root=/dev/hda5
image=/boot/vmlinuz-2.2.12-32
label=linux
initrd=/boot/initrd-2.2.12-32.img
read-only
append="hdc=ide-scsi"
### /dev/hda5 is root for GNUJobs.com laptop
root=/dev/hda5
### This command mounts the filesystem for usb to /proc/bus/usb. mount -t usbdevfs none /proc/bus/usb ### Load a generic usb module -- choose one of these three depending on your ### motherboard or USB card. I have been able to use ### uhci or usb-uhci on all my motherboards so far. If you aren't sure ### which module to use, see "Basic USB Configuration" in the Linux-USB Guide ### at http://www.linux-usb.org/USB-guide/c122.html#AEN124 insmod /lib/modules/2.2.18/usb/uhci.o # insmod /lib/modules/2.2.18/usb/usb-uhci.o # insmod /lib/modules/2.2.18/usb/usb-ohci.o ### Load the module for modems, like Ricochet insmod /lib/modules/2.2.18/usb/acm.o
mkdir /dev/usb mknod /dev/usb/ttyACM0 c 166 0
Again, I changed my modem from using /dev/ttyS0 to /dev/usb/ttyACM0. Now my Ricochet modem is working, and it seems like it is going faster than the serial modem, like it should be, but it could be my imagination. Note that these two commands are permanent: you only need to run them once. Also, this is /dev/usb, not /proc/bus/usb (explained in the Linux-USB Guide). Kernel files magically appear and disappear in /proc/bus/usb as devices are plugged in and unplugged, but that's not what this file is. USB Ricochet modems require a /dev entry; some other USB devices don't. The usbdevfs manages /proc/bus/usb, not /dev/usb.
I bought another laptop for one of my employees at GNUJobs.com from Emperor Linux, and it was properly configured, and I grilled the salesperson to make sure I got everything working without any problems. I am much happier with the laptop I got from Emperor Linux.
Another goofy thing I did was I forgot to install the iso9660 format into the kernel (or as a module). Now I can't read cdroms. I will have to compile the kernel one more time and specify to include the iso9660 filesystem format as a module.
Overall, I am impressed with the fact that is was pretty painless to install the new kernel. Installing one kernel didn't blow away earlier kernels, which made it so I could test out the new kernel without getting rid of the old one. This is helpful if I want to revert back to the old kernel. For example, before I installed pcmcia-cs for the new kernel, my laptop's ethernet card didn't work, and hence, it was helpful that I could boot to the old kernel where the ethernet card would still work. Had this happened in a lame operating system which just forces upgrades and wouldn't let you choose how to control your system, I might have been screwed.
Even though the installation was fairly easy for me, it might be easier for other people to just use rpms and to rely on their favorite Linux distribution to help them out. This is the easiest installation of the kernel and pcmcia drivers for a laptop that I have ever experienced. It is nice to see the installation getting easier and easier. After years of having to fight with the kernel for one reason or another, it is nice to see all these technologies come together.
I don't see how the evil empire will be able to resist its downfall considering the fact that GNU/Linux (and OpenBSD and FreeBSD) are technologically superior and are providing user friendliness with GNOME and KDE. The evil empire has never cared about technology, but marketing and user-friendliness. Some of the evil commercial UNIX vendors only cared about technology and did not care about making their environment pleasant to use or user-friendly. Since GNU/Linux is merging technology with user-friendliness, which is the way people want it, we get the best of both worlds, instead of having evil empires dictate to us what they think is best (or how to control us so that they can milk us).
2000-July-12 For USB help other than the readme files that are located in linux/Documentation/usb/*, see the following: Linux-USB project: http://www.linux-usb.org mirrors at http://www.suse.cz/development/linux-usb/ and http://usb.in.tum.de/linux-usb/ Linux USB Guide: http://www.linux-usb.org/USB-guide/book1.html READ THIS! (or other Linux-USB mirrors) Linux-USB device overview (working devices and drivers): http://www.qbik.ch/usb/devices/ The Linux-USB mailing lists are: linux-usb-users@lists.sourceforge.net for general user help linux-usb-devel@lists.sourceforge.net for developer discussions
Experimentation is fun. After all, one of the things that makes Linux so interesting to a number of people is the ability to twiddle settings and see what happens - I'll admit that it's a major factor for me. One of the problems with that, though, is that some types of twiddling can lead to serious problems. A bit like sawing off the branch you're sitting on, in fact...
A number of people write to the Answer Gang with a query that goes something like this:
"Dear TAG: I have a stick of dynamite strapped to the CPU, and I'm not afraid to use it. Now that I have your undivided attention: I ran into a problem while trying to reinstall..."
What it turns out to be - after the police, the fire department, and the burly men in the white coats have come and gone - is that they've run into the classic "fried MBR" problem: install Linux, realize that Windows will screw up the boot record, delete the Linux partition, try to install Windows first... OOPS. The Windows setup runs into a problem and stops.
The reason for all of the above is that they forgot to uninstall LILO, which would have written out the original MBR; as it is, the boot code in the MBR is trying to pass control to the Linux kernel - and that's no longer there.
Nothing helps. The undocumented "fdisk/mbr" option that is supposed to write a clean Master Boot Record seems to have no effect; "fdisk" in interactive mode refuses to delete the "Non-DOS" partition; even the detonator fails to explode. What to do, what to do...
By the way, a factor in the first two problems might be the Windows
"lock" command - by default, 'raw writes' to disk are disallowed, and "lock
c:" 'locks' the drive to allow writing to it. (For the last problem, stick
to the bridge-wire type detonators from Dynamit Nobel, and store them
properly. :)
* * * * * * * * * * * * * *
* * * * * * * * * * * * * * * * * * * * * *
Note: The following advice
will completely wipe your Master Boot Record,
which contains all your partition
information. DO NOT DO THIS unless you
know that this is exactly the
result you want - it will leave your HD in
an unbootable state, in effect
bringing it back to "factory-fresh", i.e.,
empty of data and requiring
partitioning and formatting.
* * * * * * * * * * * * * *
* * * * * * * * * * * * * * * * * * * * * *
Linux-based solution
If you can still somehow fire up Linux - say, via Tom's Root-Boot floppy - you can simply invoke "dd", like so:
dd if=/dev/zero of=/dev/hda bs=512 count=1
Yep, that's it. That MBR is gone. Obviously, you have to be root
to do this.
DOS-based solution
Boot with a DOS floppy that has "debug" on it; run "debug". At the '-' prompt, "block-fill" a 512-byte chunk of memory with zeroes:
f 9000:0 200 0
Start assembly mode with the 'a' command, and enter the following code:
mov dx,9000
mov es,dx
xor bx,bx
mov cx,0001
mov dx,0080
mov ax,0301
int 13
int 20
Press <Enter> to exit assembly mode, take a deep breath - and press "g" to execute, then "q" to quit "debug". Your HD is now in a virgin state, and ready for partitioning and installation.
Obviously, you have to be root... oh, oops. Anybody that walks up with a DOS floppy can do this to your system in about a minute, including boot time. Let's see; where was that article about securing your box, again?...
The "dd" man page.
DOS-based fix: Original idea and code by Mark Minasi, used for clearing infected/damaged MBRs in a course of his that I used to teach; all code/command modifications mine.
A spoofing attack involves forging one's source address. It is the act of using
one machine to impersonate another. Most of the applications and tools in UNIX
rely on the source IP address authentication. Many developers have used the
host based access controls to secure their networks. Source IP address is a
unique identifier but not a reliable one. It can easily be spoofed.
To understand the spoofing process, First I will explain about the TCP and
IP authentication process and then how an attacker can spoof you network.
The client system begins by sending a SYN message to the server. The server then acknowledges the SYN message by sending SYN-ACK message to the client. The client then finishes establishing the connection by responding with an ACK message. The connection between the client and the server is then open, and the service-specific data can be exchanged between the client and the server. Client and server can now send service-specific data
TCP uses sequence numbers. When a virtual circuit establishes between two
hosts , then TCP assigns each packet a number as an identifying index. Both
hosts use this number for error checking and reporting.
Rik Farrow, in his article "Sequence Number Attacks", explains the
sequence number system as follows:
"The sequence number is used to acknowledge receipt of data. At the beginning of a TCP connection, the client sends a TCP packet with an initial sequence number, but no acknowledgment. If there is a server application running at the other end of the connection, the server sends back a TCP packet with its own initial sequence number, and an acknowledgment; the initial number from the client's packet plus one. When the client system receives this packet, it must send back its own acknowledgment; the server's initial sequence number plus one."
Thus an attacker has two problems:
1) He must forge the source address.
2) He must maintain a sequence number with the target.
The second task is the most complicated task because when target sets the initial sequence number, the attacker must response with the correct response. Once the attacker correctly guesses the sequence number, he can then synchronize with the target and establish a valid session.
Services vulnerable to IP Spoofing:
Configuration and services that are vulnerable to IP spoofing :
TCP and IP spoofing Tools:
1) Mendax for Linux
Mendax
is an easy-to-use tool for TCP sequence number prediction and rshd spoofing.
2) spoofit.h
spoofit.h
is a nicely commented library for including IP spoofing functionality into your
programs. [Current URL unknown. -Ed.]
3) ipspoof
ipspoof is a TCP and IP
spoofing utility.
4) hunt
hunt is a sniffer
which also offers many spoofing functions.
5) dsniff
dsniff is a collection
of tools for network auditing and penetration testing. dsniff, filesnarf, mailsnarf,
msgsnarf, urlsnarf, and webspy passively monitor a network for interesting data
(passwords, e-mail, files, etc.). arpspoof, dnsspoof, and macof facilitate the
interception of network traffic.
Measures to prevent IP Spoofing Attacks:
Conclusion:
Spoofing attacks are very dangerous and difficult to detect. They are becoming
more and more popular now. The only way to prevent these attacks are to implement
security measures like encrypted authentication to secure your network.
ns_xml command to the embedded Tcl interpreter.
You can
download the source or get it directly from the CVS repository doing:
cvs -d:pserver:anonymous@cvs.aolserver.sourceforge.net:/cvsroot/aolserver login cvs -z3 -d:pserver:anonymous@cvs.aolserver.sourceforge.net:/cvsroot/aolserver co nsxmlYou need to press Enter after first command since CVS is waiting for a password (which is empty).
As of Dec. 2000 Linux distributions usually come with
version 1.x of libxml library so chances are that you'll need to
install 2.x by yourself (this will change in the future since
everyone is migrating to 2.x). To install nsxml module go
into nsxml directory, optionally edit a path in
Makefile to point into AOLserver source directory. Then
run make. You should get nsxml.so module
that should be placed in AOLserver bin directory (the same that has
main nsd executable). Add the following to your
nsd.tcl config file:
ns_section "ns/server/${servername}/modules"
ns_param nsxml ${bindir}/ns_xml.so
and restart AOLserver. You can verify that the module gets loaded by
watching server.log, I usually use a shell window with:
tail -f $AOLSERVERDIR/log/server.logThis is also a great way to debug Tcl scripts since AOLserver will dump detailed debug information every time there is an error in the script.
set doc_id [ns_xml parse ?-persist? $string]
|
| Parse the XML document in a $string and return document id (handle to in-memory parsed tree). If you don't provide ?-persist? flag the memory will be automatically freed when the script exits. Otherwise you'll have to free the memory by calling ns_xml doc free. You need to use -persist flag if you want to share parsed XML docs between scripts. |
set doc_stats [ns_xml doc stats $doc_id]
|
| Return document's statistics. |
ns_xml doc free $doc_id
|
| Free a document. Should only be called on a document if ?-persistent? flag has been passed to either ns_xml parse or ns_xml doc create |
set node_id [ns_xml doc root $doc_id]
|
| Return the node id of the document root (you start traversal of the document tree from here.) |
set children_list [ns_xml node children $node_id]
|
| Return a list of children nodes of a given node. |
set node_name [ns_xml node name $node_id]
|
| Return the name of a node. |
set node_type [ns_xml node type $node_id]
|
| Return the type of a node. Possible types: element, attribute, text, cdata_section, entity_ref, entity, pi, comment, document, document_type, document_frag, notation, html_document |
set content [ns_xml node getcontent $node_id]
|
| Get a content (text) of a given node. |
set attr [ns_xml node getattr $node_id $attr_name]
|
| Return the value of an attribute of a given node. |
set doc_id [ns_xml doc create ?-persist? $doc-version]
|
| Create a new document in memory. If -persist flag is given you'll have to explicitely free the memory taken by the document with ns_xml doc free, otherwise it'll be freed automatically after execution of the script. $doc_version is a version of an XML doc, if not specified it'll be "1.0". |
set xml_string [ns_xml doc render $doc_id]
|
| Generate XML from the in-memory representation of the document. |
set node_id [ns_xml doc new_root $doc_id $node_name $node_content]
|
| Create a root node for a document. |
set node_id [ns_xml node new_sibling $node_id $name $content]
|
| Create a new sibling of a given node. |
set node_id [ns_xml node new_child $node_id $name $content]
|
| Create a child of a given node. |
ns_xml node setcontent $node_id $content
|
| Set a content for a given node. |
ns_xml node setattr $node_id $attr_name $value
|
| Set the value of an attribute in a given node. |
ns_xml parse $xml_doc
to parse XML document in string $xml_doc and get
its document id
ns_xml doc root $doc_id
to get the id of a root node
ns_xml node children
$node_id to traverse document tree and ns_xml node ... commands to get
node content and attributes
-persist flag to
ns_xml parse
you'll have to explicitly call ns_xml doc
free $doc_id to free memory associated with this
document, otherwise it will get automatically freed after execution of
a script.
In code it could look like this:
proc dump_node {node_id level} {
set name [ns_xml node name $node_id]
set type [ns_xml node type $node_id]
set content [ns_xml node getcontent $node_id]
ns_write "<li>"
ns_write "node id=$node_id name=$name type=$type"
if { [string compare $type "attribute"] != 0 } {
ns_write " content=$content\n"
}
}
proc dump_tree_rec {children} {
ns_write "<ul>\n"
foreach child_id $children {
dump_node $child_id
set new_children [ns_xml node children $child_id]
if { [llength $new_children] > 0 } {
dump_tree_rec $new_children
}
}
}
proc dump_tree {node_id} {
dump_tree_rec [list $node_id] 0
}
proc dump_doc {doc_id} {
ns_write "doc id=$doc_id<br>\n"
set root_id [ns_xml doc root $doc_id]
dump_tree $root_id
}
set xml_doc "<test version="1.0">this is a
<blind>test</blind> of xml</test>"
set doc_id [ns_xml parse $xml_doc]
dump_doc $doc_id
ns_xml parse command will throw
an error if XML document is not valid (e.g., not well formed) so in
production code we should catch it and display a meaningful error
message, e.g.:
if { [catch {set doc_id [ns_xml parse $xml_doc]} err] } {
ns_write "There was an error parsing the following XML document: "
ns_write [ns_quotehtml $xml_doc]
ns_write "Error message is:"
ns_write [ns_quotehtml $err]
ns_write "




