
|
Table of Contents:
|
|||||
Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
|
TWDT 1 (gzipped text file) TWDT 2 (HTML file) are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version. | |||
![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/ ,
http://www.linuxgazette.com/This page maintained by the Editor of Linux Gazette, gazette@ssc.com
Copyright © 1996-2001 Specialized Systems Consultants, Inc. | |||
 The Mailbag
The Mailbag
Send tech-support questions, answers and article ideas to The Answer Gang <linux-questions-only@ssc.com>. Other mail (including questions or comments about the Gazette itself) should go to <gazette@ssc.com>. All material sent to either of these addresses will be considered for publication in the next issue. Please send answers to the original querent too, so that s/he can get the answer without waiting for the next issue.
Unanswered questions might appear here. Questions with answers--or answers only--appear in The Answer Gang, 2-Cent Tips, or here, depending on their content. There is no guarantee that questions will ever be answered, especially if not related to Linux.
Before asking a question, please check the Linux Gazette FAQ to see if it has been answered there.
 I've downloaded the ISO file. Now what do I do with it? I've burned a CD and it won't boot with it.
I've downloaded the ISO file. Now what do I do with it? I've burned a CD and it won't boot with it.Dear Answer Guy,
I really hope you can help me in my quest to change from Windows to Linux. Here is what I have done so far:
I've got a 2 year old standard PC: PII 333MHz, 128MB RAM, 4.3GB, CD-ROM, Modem, ESS soundcard.
I've downloaded the ISO file from SuSE and it is called live-evaluation-i386-70.iso
I've put this onto a CD. I can see the file on the CD under Windows. When I try to boot up using the CD ROM it ignores it. My BIOS is seto to Boot From CD and it will boot from a Windows OS CD so I know the capability is there.
I'm starting to feel that there is something I need to do to the ISO file when writing it to the CD. I've seen mention of doing this by "Burning the Image" - whatever that is. I've read the HOW-TO for CD and ISO and it doesn't explain how to do this under Windows only. It assumes you have a working Linux environment.
I came across your page, and dozens of others on this subject, and I thought I had found the holy grail as the question is exactly what I was going to ask. The thing is your answer is for a working Linux system - the guy had this as well as Windows - there is no mention of how to do this under Windows. Then the person who asked the original question writes back saying:
"Jim,
Thanks for your information. And ironically, shortly (next day) after I wrote you the email, I did find out what was going wrong and how to fix it.
WinOnCD did have the capability, but it was somewhat a "hidden" feature of sorts.
I do appreciate your response, though.
-Lewis"
He didn't even mention how he did it in WinOnCD!!!! ARRggghhh! I can find this software on the Web but I still need the knowledge to find the "hidden feature". Oh this is so frustrating., so close yet so far.
Please please please can you help me to make my ISO file, which took hours to download, into a bootable CD so that I can install my first ever Linux OS?
Thanks, EK.
To trim it down considerably, he has tried Nero Burning software but couldn't make sense of it, and the image that seems to result doesn't work. YaST2 booted from floppy gets as far as reaching for the CD, then continues to complain that the CD isn't valid.
Usually the Gang would suggest a rescue disk - our perennial favorites wouldn't help, they don't have cdrecord aboard, but you could try muLinux (http://mulinux.nevalabs.org/) boot that from floppy, and use the Linux software on it to mount up your DOS filesystem, then cdrecord according to the normal HOWTO to burn the SuSE CD. I have no idea if it would work though it seems worth a shot.
Would some kind soul out there who lives in both worlds point us to a reliable CD burning app for Windows, along with some fairly simple instructions? We'd be glad to let you put the article in the Gazette if it will help enough potential Linux'ers out there. -- Heather
Fetchmail questionI read Ben Okopnik's article in the February issue of Linux Gazette titled
No More Spam! (a "procmail"-based solution with tips on "fetchmail" and "mutt")
and I tried implementing some of his suggestions. My problem seems to be this: While fetchmail will get my e-mail, and pass it off to procmail, which delivers it to a designated file, I can't seem to read the e-mail with kmail. I've set my designated file as a local mailbox for kmail to read, but when I try to read it using kmail I get 1 of 2 behaviors:
I tried setting up kmail to read from the local mailbox with the following
lock file options:
mutt dotlocked
mutt dotlocked priveledged
Procmail lockfile
FCNTL
None
Any of the above will cause either behavior 1) or 2).
Anyway, I'm hoping you might be able to help me figure out how to read my local mailbox with kmail.
--Rod
P.s. Included is a snapshot of
my kmail configuration for reading the local mailbox into my inbox.
Hopefully, it will be of some use to you for diagnosing my problem.
P.p.s. Thanks in advance for any help you can give me on this.
P.p.p.s. Here are the configuration files for the various utilities:
(I blanked my password in the .fetchmailrc file in this e-mail, for security
reasons
![]() )
)
nuovo progetto
Cari amici della gazette
mi chiamo Francesco Barilà
Insieme ad alcuni amici vorremmo creare uno shell-wordprocessor emacs
based: qualcuno di voi è interessato?
Se lo siete mandate un email a fbaril@tiscalinet.it
oppure visitate linux.interpuntonet.it/angolinux al tread
"nuovo progetto"
grazie
Francesco
Dear gazette- friends
I am Francesco Barilà
I and my friends want create a shell- woprdprocessor emacs-based: is anyone
interested?
mail to fbaril@tiscalinet.it or visit
linux.interpuntonet.it/angolinux
and see the tread "nuovo progetto"
thanks
Francesco Barilà
Let him know what you think, folks. For my own part, we could still use a wordprocessor that actually works... -- Heather
syslog-ngHi, I'm fighting with syslog-ng, trying to centralize the logs of all a network to a log server. Till now, I'm justing testing it between two machines ... I've already been on it a long time and still no result, simply nothing appears in the final log on the logserver ... I've attached the syslog-ng.conf of the client and the server's one too.
You must know that for the server's source, I've already tried to enter
parameters (I mean an ip and a port) but it doesn't work either so at
the moment, I'm trying to use the defaults. The same thing for the
client ...
Can you help me on this?
Thanks
rebooting using rsh commandAnswerGuy,
I hope you can help me with this problem.
We've upgraded our kernel from 2.0.0 to 2.2.14-5.0 (Red Hat 6.2). We have a master node that is connected to a total of 14 nodes. In the past, when we rsh'd into a node and wanted to reboot we would just type at the prompt 'reboot'. We would immediatly be kicked back to the master node prompt while the other node was rebooting. This worked out fine.
However, when we rsh into a node and type 'reboot' the terminal hangs, for several minutes, until the node has completed rebooted and then it drops us back to the master node. We want it to work the way it has in the past. Is there some file or configuration I'm missing, some flag to turn off or on?
Any of you gentle readers with experience in this kind of clustering, if you have any idea what it might be, then feel free to lend a hand. We'll publish your answer here. -- Heather
queryHii james, this is mehul from india...
need to know if i can control bandwidth on a particular interface using ipchains or any other utilities in linux... basically, ill have a multi-homed linux workstation and i want to limit bandwidth on one interface to 512kbps... is that possible?
T&R
mehul
Defining Keyboard ShortcutsI would like to define keyboard shortcuts not specific to a Window Manager. I have read documentation on xmodmap, but the information I have found only talks about and show examples of changing key actions to another pre-defined action. That is, being able to change the caps lock key to function as an escape key. How would I go about assigning a command to a lctrl + F1 key code?
The ultimate use for this is to help a fellow LUG member. He wants to be able to assign text strings to "hot keys" whereby the text string would be copied to the window he is working in. He wants to be able to save the text strings as he is working so that they can be used in other session; and have the ability to delete or change these text strings. I can proably figure out a script to do this, but I am stuck on defining the keyboard shortcut.
Thanks
Daniel S. Washko
upgrade2.2.14 to 2.4 kernel documentionhello,
is there any kernel upgrade from 2.2.1# to 2.4 how-to 's. I have upgraded the kernel using a general how-to and I have problems mounting the vfat partitions by getting the error "invalid major and minor numbers". I know the way the system deals with special device files has changed at 2.4. Also the "eth0" ethernet adapter is not being recognised. Any help in finding good documentation for this process would be greatly appreciated.
mark taylor
Linux Sockets Stuck in FIN_WAITOn our project if an established client socket connection on a remote chassis is suddenly terminated (e.g., the chassis is powered off), the socket connection on the local chassis changes from ESTABLISHED to FIN_WAIT1. If we then try to restart our application on the local chassis, it does not work because the socket connection is stuck in a FIN_WAIT1. After 5-10 minutes the socket connection stuck in FIN_WAIT1 clears itself and we can successfully restart our application on the local chassis, but this wait is too long.
Do any of you know how to expedite the process of clearing FIN_WAITs on a Linux/UNIX chassis under these conditions? The only we can get them to clear is to either wait 10 minutes or perform a chassis reboot (sync; shutdown -r now). Is there a system call that can be used to tell the operating system to close/delete/clean-up/remove all socket connections immediately?
The only thing I have run across so far is to possibly make a kernel change (e.g., change #defines in .../include/net/tcp.h), or set a socket option which causes the sockets to close/clean-up faster. Note: these changes may be risky if we shorten the timeouts too much.
Any help would be appreciated.
Thanks,
Ken Ramseyer
CD-Writing with an ATAPI CDR Mini-HOWTO
Hi
I've read the articles from issue 57 of the Linux gazette, but am unable
to get my cd-rw to work. I don't think I am managing to emulate scsi
correctly, although I have followed the things sugested. I have a sony
cd-rw (CRX 145E ATAPI) and run mandrake 7.0, I also have a iomega 100Mb
zip drive on hdb, a dvd-rom on hdc and the cd-rw is on hdd. This is
what I've done and what the comp says:
In /etc/rc.d/rc.local added
/sbin/insmod ide-scsi
In /etc/conf.modules added
alias scd0 srmod alias scsi_hostadapter ide-scsi options ide-cd ignore=hdd
(also tried replacing srmod with sr_mod)
In /etc/lilo.conf added
append="hdd=ide-scsi"
then in console typed
lilo (and tried /sbin/lilo)
then rebooted, then dmesg gives at the end:
hdb:<3>ide-scsi: hdb: unsupported command in request queue (0) end_request: I/O error, dev 03:40 (hdb), sector 0 unable to read partition table scsi0 : SCSI host adapter emulation for IDE ATAPI devices scsi : 1 host. Vendor: IOMEGA Model: ZIP 100 Rev: 14.A Type: Direct-Access ANSI SCSI revision: 00 Detected scsi removable disk sda at scsi0, channel 0, id 0, lun 0 sda : READ CAPACITY failed. sda : status = 0, message = 00, host = 0, driver = 28 sda : extended sense code = 2 sda : block size assumed to be 512 bytes, disk size 1GB. sda:scsidisk I/O error: dev 08:00, sector 0 unable to read partition table
For some reason I can't get the machine to emulate scsi on anything other than hdb. cdrecord -scanbus only lists the zip drive too. The /sbin/insmod ide-scsi comand also stops the zip drive from working. Have you any ideas as to what might be going wrong?
Many thanks for any advice you can offer
Louise
Sci-Linux Project has a listed e-mail address ..Hi.
This is in reply to ghaverla@freenet.edmonton.ab.ca's mail about scilinux.freeservers.com not having a e-mail address on the page. In fact at the bottom of the page before the disclaimer we have links to contact us. It appears when i look at it from India On Netscape. I am one of the maintainers and please do contact me for your suggestions, ideas, flames, etc ..
We are just crystallising our thoughts after the fruitful discussion with TAG (Jan 2000 issue) and have decided to first install all the relevant packages on a RedHat partition of our PC, find the library dependencies, make a "library farm" and use ldconfig after adding the libraries in the library farm to the /etc/ld.so.conf. To check what problems this gives we will then make a "zeroth" version of our CDROM and installation script and try installing all on the SLACKWARE (my dream distro) partition of our PC. Test the software, check if anything else goes wrong, etc .. It seemed to work for scilab and octave when I did a manual check. From what I have read till now about libraries (not much at all, maybe I should read up and write an article for the LINUX GAZETTE -> best way to learn something) this does not seem to be a wrong thing to do.
Thanks, Manoj, we'd love to see your article! -- Heather
Another thing is we are not trying to make a platform independent package or installer, but just want to install some selected scientific software packages on any old/new Linux PC. We hope to make a zeroth version, test it at our institute PCs and only after thorough testing keep it for download at some voulenteering site or mail it to anyone who pays the posting and CDROM cost.
PS: We are still looking for some server to host our site. We do thank freeservers, but the it would be nice to host the site at some server that displays Linux related advts only.
Manoj
My Enviornment for scientific computing on Linux page :
http://Scilinux.freeservers.com
Navigation......I love what you do but how about putting links to the rest of LinuxGazette (or at least the front page) at the tops and bottoms of each Answer Gang article? Thanks!
-- Jim Coleman
Once upon a time this was the case, but folks wrote in, saying that having that main navbar as well as the links within the TAG area was a bit confusing... they often hit "next article" when they meant "next TAG message". But, we can try adding back in only the main Index, and see how that works. -- Heather
Mailto URL error in LG Mailbag (followup)I'm glad you're using mailto's that include the TAG address. The problem is the URL construction was incorrect.
It should be an equals sign (=) after the cc parameter. A quick run through sed should fix this before you get too many messages pointing out the error.
If there's any way to add the subject, you could make the URLs look like this:
mailto:user@domain?cc=linux-questions-only@ssc.com&subject=Re:%20SUBJECT
Note that the subject has to go through a filter that replaces spaces with the hex code "%20" to keep the URL legal. In perl, I'd do this:
$mailto_subject =~ s/ /%20/g;
You can quickly test the functionality of a mailto URL by typing variations directly into the address/URL box of the target browser and see if it calls the mail client as you intended.
Tony
Thanks, Tony, you win the AnswerBubble for the month. I like it when
folks not only nail us for a bug (that one was me, I'll go fix
the script so it'll be right next time
![]() ...
but also send us Tip grade material about fixing it. We're trying it this
month. I'm sure that our readers will let us know if there's any problems -- Heather
...
but also send us Tip grade material about fixing it. We're trying it this
month. I'm sure that our readers will let us know if there's any problems -- Heather
Heather SternI just want to say thank you.
Her greeting in The Answer Gang is beautiful. I'm a relative newbie to Linux (It took me a week of reading and playing to compile a kernel that would find my NICs). I understand the open source idea, and love it. I deal in 2 other fields where this idea (in a general sense) applies. Emergency Medical Services where we share ideas, issues, and solutions, not for money, but for the knowledge of helping others. Also in restoring old cars, Things are learned, forgotten, learned again, and most importantly past on. By sharing, we (Linux users) end up with a better app or method.
Again, Thank you
Remember, there are people out there who really appreciate the work that is done.
- Mike Gargiullo
The Answer GangIn Issue 64 you invite Ray Taylor to join The Answer Gang. How would one do that? Is it like a mailing list open to everyone? Can anyone help?
TAG is run like a mailing list in reverse. The public sends in questions, and the subscribers are the answerers. To join, send e-mail to tag-request@ssc.com with "subscribe tag me@mysite.com" in the message body. Then just jump in whenever you have something to say. At the end of the month, Heather selects some of the messages for publishing. -- Mike
SSH articleIn the article on ssh, scp, and sftp in the March issue, there is an important area that isn't covered: client/server compatibility.
If you're just doing a basic ssh (to get a remote shell), you're using a standard SSH protocol and any program named "ssh" is likely to work with any remote system that offers a service it calls "ssh."
But scp and sftp are not standard protocols. If you run the scp program from openssh against a remote system that's running an original ssh server, it will not work. (And when I learned this the hard way, it was very hard indeed: the error message isn't "this server doesn't implement this scp protocol." It is, for reasons that took a day of debugging to figure out, "invalid file descriptor"!
Mean Thoughts on the Linux Router ProjectFirst off let me apologize to all the developers or others who I have offended with my views on the Linux Router Project (LRP). By no means did I want to start a flame war. The truth is that I wrote about something outdated. Second, that article was entirely my own; not the work or opinions of Linux Gazette.
Since I wrote "Mean Thoughts" I have received a great many meaningful and insightful messages from LRP users and developers. If I wrote any untrue information I want to know about it. One point of contention for example was whether the ip command is 'nonstandard.' This is purely subjective. If ip really is standard, it should replace ifconfig or route like ipchains replaced ipfwadm.
Nevertheless my views on the LRP have changed. I received such an education that I feel obligated to state for the record I have learned uses for each of the three main LRP distributions, EigerStein (http://lrp.steinkuehler.net/DiskImages/Eiger/EigerStein.htm), Oxygen (http://leaf.sourceforge.net/pub/oxygen), LRP 2.9.8 (http://www.linuxrouter.org) --even in embedded systems. I am not brand-loyal. Advocacy is fine, but fanaticism has got to go. I'll use the best tool for the job, and how I determine what is the 'best tool' is purely subjective. Five years ago I preferred 3Com to any other NIC. Why? Two reasons: The founder of 3Com invented Ethernet, and the cards were recognized by all the OSs that the company used. I knew I would not have to worry about cross platform compatibility. Now I prefer SMC. Why? Mainly because all the OSs recognize them but also because I can jumper-select IRQ & I/O on the models I use.
Would I write another 'anti-Linux' article? Sure. But not one that could potentially insult anyone like when I said, 'developers wasting time'. Linux is merely a product. Windows NT is also a product. Never mind the fact that I despise products from Redmond, Washington: I don't think it's a sin to admit that NT is better than Linux at being a "Domain Controller." It does not change how much I like Linux.
Look at the article and notice its verbosity. It's an opinion, not a review. I did not write it solely for explaining my (i.e., not Linux Gazette == Don't shoot the messenger.) thoughts on the LRP, I also wanted to express and present other information that may be useful to the Linux community, for example the bit on standardization. I did not write it to maliciously annoy anyone. Also to my knowledge there is no technically inaccurate information. I wrote specifically, "I have not done a lot of work/research with LRP incarnation at linuxrouter.org as such but I am familiar with the Materhorn Project." My mistake was that I equated <Linux Router Project> with one flavor, Materhorn.
I may or may not follow with a "Nice Thoughts on the Linux Router Project"
article.
![]() In any case, I'd like
to put all hard feelings aside and hope that anyone who I have offended
would do the same.
In any case, I'd like
to put all hard feelings aside and hope that anyone who I have offended
would do the same.
Sincerely,
Mark Fevola
[Mike] We received several complaints about the article, feeling that it attacked the LRP unfairly. Dave Cinege, the creator of the LRP, was going to write a response addressing the inaccuracies he felt were in the article, but he did not have time to finish his letter by press time. I encourage readers with an interest in routing to follow the links above to the projects' home pages and decide for themselves if the LRP and its offspring are right for them.
Regarding Oxygen, EigerStein and 2.9.8, Dave writes:
They are derivatives of stable releases of LRP, which is currently 2.9.8. I have been creating a new OS similar to LRP for quite some time now. Many things have come out of this are a new multi-packaging system (standard?) that is more powerful then rpm or deb, yet not tied to any specific OS.
Regarding the 'ip' command, he writes:
ip allows you to control the extended routing features of 2.2 and 2.4, IE multiple routing tables. Ifconfig still works for the primary routing table and interface configuration. ip can replace ifconfig, but ifconfig is still the known standard.
A few letters questioned LG's editorial policy in allowing this article to be published. LG's policy is pretty open. If an article is about Linux, contains hard facts or cultural value (e.g., humorous articles, cartoons and articles about Linux VIPs), covers a topic relevant to a significant portion of the readership, is not an advertisement in disguise, and would still be relevant several months from now, we'll probably publish it. There are borderline cases, and this was one of them.
LG does not have a technical review board to screen every article, although I do send a few questionable articles to The Answer Gang for comment. You, our readers, are LG's technical review board, and usually this system works very well. 99% of LG's articles are published without complaint.
In any case, please remember this article describes one person's experience with certain routing programs. It's not meant to be gospel, in spite of the letter I received that said, "But newbies will read it and think it's gospel!" That's not how it works. If you want gospel, read several people's articles and compare them with your own experience.
Another thing this article does is raise the question, just because we can use Linux in a wide variety of routing situations, should we? Are you choosing a Linux router because it's the most appropriate solution for the task, or simply because "we're a Linux-only shop"? Even if the article failed to present LRP in a fair light, these are still questions worth asking.
As always, if you have any comments about an article, whether good or bad, send them to LG and we will forward them to the author.

|
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release.
 Linux 2.4.3
Linux 2.4.3
Linux 2.4.3 is out. See the changelog or find a kernel mirror.
Linux Journal and Embedded Linux Journal


The April issue of Linux Journal is on newsstands now. This issue focuses on Internet/Intranet. Click here to view the table of contents, or here to subscribe. All articles through December 1999 are available for public reading at http://www.linuxjournal.com/lj-issues/mags.html. Recent articles are available on-line for subscribers only at http://interactive.linuxjournal.com/.
The March/April issue of
Embedded Linux Journal was
mailed to subscribers in February.
Click
here
to view the table of contents. Professionals working in the embedded field
in the US, Canada or Mexico can get a free subscription by clicking
here. Paid
subscriptions to other countries are also available.
Caldera
Caldera Systems have announced the open beta availability of its new OpenLinux server product, code-named "Project 42," and an agreement with Lutris to ship the Enhydra Open Source Java/XML application server with the new version. The product is based on the new Linux 2.4 kernel and targets OEMs and VARs. Project 42 incorporates a secure Web server, a file and print server, and a set of network infrastructure servers, including DHCP, DNS, and firewall.
Caldera and SCO have unveiled Open UNIX 8, incorporating support for Linux applications. Open UNIX 8 will maintain compatibility and continuity with the UnixWare 7 operating system while providing a complete Linux environment. In addition, the product will incorporate support for the execution of unmodified Linux Intel Architecture binaries.
Debian
Debian has chosen Ben Collins as the new Debian Project Leader (DPL).
Progeny Debian
Progeny Linux Systems have announced that Release Candidate 1 of Progeny Debian is now available for download. Progeny Debian is based on woody, the current testing version of Debian, and made by a team of leading Debian developers. Company CEO Ian Murdock, has said that he expects any changes after RC1 to be bug-fixes and cosmetic improvements
Features of RC1 include: graphical installation and configuration tools, a GNOME interface for debconf, improved hardware detection and USB support, optional migration to GRUB, and automated multiple installations.
Software included in RC1 includes:
For more information about Progeny Debian, visit www.progeny.com.
SuSE
SuSE Linux have released apparently very positive news about the future of Linux in Germany. A poll commissioned by SuSE showed that 56 percent of the interviewed PC users have heard of Linux and ten percent already use the alternative operating system at home or at work. This statistic indicates that, in terms of distribution, Linux is second to Windows. Furthermore, 23 percent of the computer users consider switching to Linux when upgrading their equipment. This information was obtained from a survey recently conducted by the market research institute TNS EMNID, Bielefeld, Germany.
It also has KDE2, XFree86 4.0.2 and SaX2, the expanded graphical configuration tool which ensures a simple and secure setup of supported graphics cards, is also a new feature. An improved version of MOL (Mac on Linux), the virtual machine used to start MacOS in Linux, complements the distribution.
The range of supported IBM computers with PowerPC processors has been considerably enlarged. SuSE Linux 7.1 PowerPC Edition now runs on IBM Power3 machines. The possibility to use up to 3 GB RAM and an expanded multi-processor support provided by Kernel 2.4 make SuSE Linux 7.1 PowerPC Edition especially attractive for IBM pSeries 640. Thus, SuSE Linux 7.1 PowerPC Edition is the first Linux solution that supports these computers "out of the box".
The package includes 6 CDs, a 500-page manual and 60 days installation support for EURO 49.00.
Lion worm (DNS/BIND security alert!)
Anyone using BIND should be aware that there is a new worm on the loose. The Lion worm attacks certain versions of BIND (the domain name server program). The Sans Institute have plenty of information on the worm, and indicate that Bind versions 8.2, 8.2-P1, 8.2.1, 8.2.2-Px are vulnerable. BIND 8.2.3-REL has been reported as not being vulnerable (this information is preliminary and potentially incomplete). The BIND vulnerability is the TSIG vulnerability that was reported back on January 29, 2001. If you believe your system has been compromised, the SANS Institute has a program Lionfind that detects it. Now is a good time to get the latest version of BIND from your distribution vendor, run named as non-root, or switch to a BIND alternative.
It is also worth looking at general security issues. To get an idea of how security should be done, check out the results of the Honeynet forensic challenge. Candidates downloaded the partition images of a compromised Linux system and had to find out "who, what, when, where, how". The results show how professionals go about doing these things, but also how difficult and time consuming recovering from a compromise can be. The lesson is "BE PREPARED!"
Upcoming conferences and events
Listings courtesy Linux Journal. See LJ's Events page for the latest goings-on.
|
LINUX Business Expo | April 2-5, 2001 Chicago, IL http://www.linuxbusinessexpo.com |
|
Free Web ROI Seminar by Akami Technologies | April 3, 2001 Seattle, WA http://www.akamai.com/roitime/ |
|
Linux Expo, Madrid | April 4-5, 2001 Madrid, Spain http://www.linuxexpomadrid.com/EN/home |
|
Lugfest IV | April 21-22, 2001 Simi Valley, CA http://www.lugfest.org |
|
Linux Expo Road Show | April 23-27, 2001 Various Locations http://www.linux-expo.com |
|
Linux Africa 2001 | April 24-26, 2001 Johannesburg, South Africa http://www.aitecafrica.com |
|
Open Source Development Network Summit | April 30 - May 1, 2001 Austin, TX http://osdn.com/conferences/handhelds/ |
|
Linux for Industrial Applications 3rd Braunschweiger Linux-Tage | May 4-6, 2001 Braunschweig, Germany http://braunschweiger.linuxtage.de/industrie/ |
|
Linux@Work Europe 2001 | May 8 - June 15, 2001 Various Locations http://www.ltt.de/linux_at_work.2001 |
|
Linux Expo, São Paulo | May 9-10, 2001 São Paulo, Brazil http://www.linux-expo.com |
|
SANS 2001 | May 13-20, 2001 Baltimore, MD http://www.sans.org/SANS2001.htm |
|
7th Annual Applied Computing Conference | May 14-17, 2001 Santa Clara, CA http://www.annatechnology.com/annatech/HomeConf2.asp |
|
Linux Expo, China | May 15-18, 2001 Shanghai, China http://www.linux-expo.com |
|
SITI International Information Technologies Week OpenWorld Expo 2001 | May 22-25, 2001 Montréal, Canada http://www.mediapublik.com/en/ |
|
Strictly e-Business Solutions Expo | May 23-24, 2001 Minneapolis, MN http://www.strictlyebusinessexpo.com |
|
Linux Expo, Milan | June 6-7, 2001 Milan, Italy http://www.linux-expo.com |
|
USENIX Annual Technical Conference | June 25-30, 2001 Boston, MA http://www.usenix.org/events/usenix01 |
|
PC Expo | June 26-29, 2001 New York, NY www.pcexpo.com |
|
Internet World Summer | July 10-12, 2001 Chicago, IL http://www.internetworld.com |
|
O'Reilly Open Source Convention | July 23-27, 2001 San Diego, CA http://conferences.oreilly.com |
|
10th USENIX Security Symposium | August 13-17, 2001 Washington, D.C. http://www.usenix.org/events/sec01/ |
|
HunTEC Technology Expo & Conference Hosted by Hunstville IEEE | August 17-18, 2001 Huntsville, AL URL unkown at present |
|
Computerfest | August 25-26, 2001 Dayton, OH http://www.computerfest.com |
|
LinuxWorld Conference & Expo | August 27-30, 2001 San Francisco, CA http://www.linuxworldexpo.com |
|
The O'Reilly Peer-to-Peer Conference | September 17-20, 2001 Washington, DC http://conferences.oreilly.com/p2p/call_fall.html |
|
Linux Lunacy Co-Produced by Linux Journal and Geek Cruises Send a Friend LJ and Enter to Win a Cruise! | October 21-28, 2001 Eastern Caribbean http://www.geekcruises.com |
|
LinuxWorld Conference & Expo | October 30 - November 1, 2001 Frankfurt, Germany http://www.linuxworldexpo.de/linuxworldexpo/index.html |
|
5th Annual Linux Showcase & Conference | November 6-10, 2001 Oakland, CA http://www.linuxshowcase.org/ |
|
Strictly e-Business Solutions Expo | November 7-8, 2001 Houston, TX http://www.strictlyebusinessexpo.com |
|
LINUX Business Expo Co-located with COMDEX | November 12-16, 2001 Las Vegas, NV http://www.linuxbusinessexpo.com |
|
15th Systems Administration Conference/LISA 2001 | December 2-7, 2001 San Diego, CA http://www.usenix.org/events/lisa2001 |
LinuxFocus
LinuxFocus is a Linux webzine that's been around for years, but may not be familiar to some LG readers. Unlike LG, which is essentially in English with some foreign-language translations, LF was founded with the goal of providing non-English speakers with "enough [Linux] information in their native language that they can join in the Linux community." Currently, seven languages are fully supported and four more are partially supported. Translations happen both ways: there are currently six French articles waiting to be adopted by English translators. LG fully supports LF and wishes it success.
NetworX and AMD Supply Cluster to Boeing
The Boeing Company is using a Linux NetworX cluster powered by 96 AMD Athlon processors. The system, designed as a high performance cluster, is being used by Boeing Space & Communications in Huntington Beach, Calif. to run computational fluid dynamics applications in support of the Delta IV program. Boeing Delta IV engineers tested multiple processor platforms at Linux NetworX facilities prior to buying the cluster, and selected the AMD Athlon for its price and performance advantages.
Linux NetworX has also announced the development of LinuxBIOS for the Alpha platform. In conjunction with the LinuxBIOS Open Source project, Linux NetworX has replaced SRM firmware on the Alpha platform with a Linux-based BIOS. Users will now have the ability to boot to Linux directly out of the ROM on the motherboard.
Python Software Foundation & Python Cookbook
ActiveState have announced involvement in the launch of a collaborative programming book, the Python Cookbook, with O'Reilly & Associates. The Cookbook will be a repository of reviewed Python recipes that have been contributed by the Python community for the community. It will be freely available for download. For details please go to the website. Activestate will also be a founding co-sponsor of the new Python Software Foundation (PSF). The PSF's is to provide educational, legal and financial resources to the Python community. More information is available in the full press release
Penguin Computing Selects Arkeia Backup for Linux Servers
Knox Software Corp. have announced that the company has entered into a reseller agreement with Penguin Computing Inc. Under the agreement, Penguin Computing will now offer Knox's flagship network backup application, Arkeia, for bundling with Penguin's pre-configured custom Linux servers.
IBM, Biotech and Linux
For more information on IBM's Linux developments, refer to their website.
OEone Teams Up with EarthLink
OEone and EarthLink are working together to integrate EarthLink's Linux based Internet access software with OEone's Internet-computer operating environment platform.
TeamLinux and Muze to Expand Relationship
TeamLinux is to expand its relationship with Muze Inc. to provide hardware support and service for its existing and future kiosk customers. This new multi-year contract provides for TeamLinux to be the premiere provider for all hardware and service. Muze will continue to provide its proprietary software and be the first level of contact for any Muze system issues.
Sair Linux & GNU Certification
Agenda Computing Sell Linux PDA
California-based Agenda Computing are launching a pure Linux PDA (personal digital assistant) to challenge Palm in the war for market share. Each Agenda VR3 and VR3r is loaded with unique software and hardware features like 16MB of Flash memory, which eliminates the problem of data loss associated with RAM-based units. It also supports 7 languages, is e-mail compatible, and will send a memo or message to a printer by wireless infrared transfer.
Keyspan Ships 4-port USB Serial Adapter for Linux
Linux Links
Galleo is a mobile multimedia communicator. It's a nifty-looking PDA with e-mail, web and music capabilities. Unfortunately, their web site is not so nifty: I can't get the menu buttons to show. So click on the Galleo image or try this link to their follow this link to get to the products page and use the text links from there, and click on "Virtual Tour". (Requires Javascript and who knows what [Shockwave?] for the movie.)
The Duke of URL has the following to offer:
Some links from the folks at ZDNet's Anchordesk UK
debianhelp.org offers, um, help on Debian.
Linux Valley, an Italian portal for the Linux operating system, has been updated. It offers a range of interactive and community services.
Microsoft says Linux is a threat to intellectual-property rights. Linux Journal disagrees.
Paranoid Backup is designed to "work with cheap tape drives and cheap tapes without shoe-shining or losing data; to never overwrite old backups; and to use as few tapes as possible."
The Pentagon's research agency is preparing to demonstrate a soldier's radio designed to provide mobile communications among individual troops on the battlefield. The network will be based on the Linux operating system. Courtesy Slashdot.
The Linux Expo Birmingham 2001 web site is now online. For information on other Linux-Expo events, consult their website.
OLinux have an interview with Rick Lehrbaum from LinuxDevices.com. OLinux are also currently looking for an investor or a company willing to translate and promote OLinux around the world.
Doug Eubanks has put together a new Linux/RoadRunner help site. He aims to consolidate the various threads in the field.
An article on Microsoft's complicated licensing terms for enterprise users. The title for the Slashdot link is, "Microsoft Turning Screws on Customers".
Tom's Root/Boot Updated
Tom Oehser has released a minor, but recommended, update to tomsrtbt. Current version is now 1.7.218. Get it from: http://www.toms.net/rb/. This is something everybody should have on hand in case you someday have to boot from an emergency floppy.
AbsoluteX Now Available for Download
Loki Games
Loki Software has announced an agreement with developer-driven computer and videogame publisher Gathering of Developers to bring the hit PC games Rune and Heavy Metal: F.A.K.K.2 to Linux early this year. Testers are required, register here.
Furthermore, in a race to GPL freedom, Loki Software, Inc. are releasing the latest in their line of open source projects: a complete set of end-user and developer tools for managing software releases.
"Emerald Isle" Ispell
GARLIC Version 1.1 Released
The FIEN Group to Sell
Teamware Office for Linux in the U.S.
Teamware Group , a Fujitsu subsidiary, and The FIEN Group, a Southern California-based technology consulting organisation have signed a partner agreement according to which The FIEN group will sell Teamware Office 5.3 for Linux groupware to customers across the USA. Teamware Office 5.3 for Linux includes facilities for electronic mail, time and resource scheduling, discussion groups as well as document storage and retrieval. The famous Teamware Office groupware suite has been in the market since 1989 and was ported to Linux platform in spring 2000.
Opera to be released as ad-ware
Opera Software has announced that the final release of its Linux browser will be available for free to all users. The free version has full functionality but contains banner ads. If you don't want banner ads, you can register your free copy for $39, or buy the adless version for the same price. If you are interested in this product, Opera 5 for Linux beta 7 is now out.
Open Motif Now Supports Latest Linux 2.4 Kernel Distributions
Integrated Computer Solutions has released an updated version of Open Motif Everywhere. This new release officially incorporates Open Group Patch 3 and Patch 4 into the Open Motif release. These patches include bug fixes and updates to the Motif libraries, clients and the demo source code. RPM (version 4) are also provided for both Red Hat Linux 7, SuSE Linux 7.1 and other distributions using glibc 2.2. The latest ICS Open Motif binary and source packages are available for free download at ICS's Motif Community site, the MotifZone. They are also available for $29.95 on ICS's Open Motif Everywhere distribution CD that can be purchased through the ICS Store.
Kaspersky Lab Introduces the New Version of
Kaspersky Anti-Virus for Linux
Kaspersky Lab have announced the release of the new version of Kaspersky Anti-Virus for Linux (3.0 Build 135.3). This new version adds several features, including installer support for different Linux distributions, and a ready-made solution to integrate centralised virus filtering for Postfix e-mail gateways. The new version of Kaspersky Anti-Virus is available for download from the Kaspersky Lab Web site. All registered users of previous versions of Kaspersky Anti-Virus for Linux may upgrade to the new version free of charge.
Other software
Rob Pitman has released a LGPL licensed software package that provides a "graphical user interface" between a Java application and an ASCII terminal. The package emulates the API of the Java AWT and the Swing toolkit. It provides "graphical" widgets such as Frames, Dialogs, Labels, TextFields and Buttons. One can design the GUI of an application using any Java IDE and then port it to use a text interface with little work. You can get more information about the package at: http://www.pitman.co.za/projects/charva/index.html.
Mahogany Version 0.62 is out. Mahogany is an OpenSource(TM) cross-platform mail and news client. It supports a range of protocols and standards (POP3, IMAP4, MIME, etc.,), secure communications via SSL, and can be extended using its built-in Python interpreter and loadable modules.
TUXIA specialises in embedded Linux software suites for Internet and Information appliances. TASTE (TUXIA Appliance Synthesis Technology Enabled) is a solution based on Linux Kernel 2.4 with an embedded Mozilla browser and other functionalities, that can be integrated into any hardware platform.
 The Answer Gang
The Answer Gang

There is no guarantee that your questions here will ever be answered. You can be published anonymously - just let us know!
 Greetings from Heather Stern
Greetings from Heather SternIt's that stormy month of the year again, when people expect us to be silly in print.
I feel silly for saying this but it seems like we have to every month:
- There is no guarantee that questions will ever be answered, especially if not related to Linux.
- HTML attachments drive us nuts...
ICANN expressed a desire to make a foolish mess of the entire internet. I wrote "An Open Letter to ICANN" which has been published in Linux Journal recently: http://www.linuxjournal.com/articles/conversations/0022.html
While we're thinking of messes, and Easter coming up, how about cute fluffy bunnies? I cleaned up the ol' home office a bit. I think Dust Puppy (http://www.userfriendly.org) can find a girlfriend named Dust Bunny if he tries hard enough.
As you hopefully know by now this is a Linux magazine and we normally only answer Linux questions. But, it's the silly month, so once again with that cardboard box thread that snuck in ...
And finally, something I've been messing with that makes us all continue to look foolish for using Linux. How can we call ourselves a desktop system when all the word processors suck? Oh yeah. We don't. We just call it an operating system, apps are for distros. Well, they still need to work on it.
The first thing you may wonder is why would Ms. My Box Is More Productive Without Producticity Software even care, anyway? Well, it so happens that a friend of mine, who isn't computer oriented in the slightest, wanted a resumé and of course since we're close, she asks me. No problem, I think. It's just an rpm -i or an apt-get install away. Right.
For a more positive view, see Tony's telecommunications article this issue.
Don't believe me, eh? Well let's start at the top. WordPerfect is time bomb ware. Their idea of "for personal use" includes dying at 90 days so you have to go get a registration key, allegedly free. In my old shareware days I always avoided timebombs. You never know if they might also try to take your documents with them or something. It's a shame because I always liked their DOS software. I may buy it someday, when I need it for myself, after all, with my consulting biz I guess I don't count as personal use anyway. But I resist - my principles don't call for supporting time bombs. Grr.
I tried StarOffice a few months ago. It shows many of the worst features of having originally been a port from the windows version via some translation library. Its "everything lives inside the Staroffice Window" mold was one of the GUI features I was glad to get away from when I left Windows behind, and its printer configuration is evil and broken. Okay, when it finally works it's rather cool to have numerous Avery papers selectable in the dialog so you can do labels and index cards. But, it's actually easier to set up a printer with plain old lpr and magicfilter. Yuck.
Applix might be okay. I dunno, I was in a hurry, and wanted something a bit smaller. I guess I just hate the idea that I have to download a whole suite just to get one part.
I think I have LyX installed, I try that. I do. It doesn't do a number of things that need doing. I tried to do spring margins and it has its own ideas how wide to make the table. This will never work.
The SIAG people have loose parts. Their word processor is called Pathetic Writer. I tried it... and they're right. If I recall correctly Wordpad has more features. Sigh.
How about Abiword? Those abisuite guys have their head on straight, let's try it. So happens Terry already has it on his box since we put Progeny on his desk. He tries to use it for one page reports and growls at it because it can't deal with tabs very well. Hmmm... anyway, just an ssh session over there and access it via X, right? Wrong! It whines that a font is missing. That's insane. Betel has the most complete font collection in the house, since it's setup to be our TTF font server...
Fine. Install it locally. (I have to get the whole suite. Oh well. Get a soda, come back.) One SuSE style rpm i coming up! (wave magic wand) uh, this doesn't load at all, even to pop up with the complaint. No error message in the xterm window, nothing. Fume.
Well, let's try the K office then. Kword coming up. Installs sweet enough. Even runs. (Yay!) Can't do tables even though it has buttons for it. Now, we are talking about everyone's favorite use for spring margins, putting the dates of your last employ all the way to the right, and since almost nothing has proper spring margins, can't do it without tables. At least it does those long beautiful bars, which I had figured would need tables. Even when I use just plain white space to push things to the end, the thing is iffy about whether they show up over there. If I change the font anywhere on the line its metrics are a scramble and things fall off entirely.
On the bright side, its preview feature generates very clean Postscript, not yet encapsulated. So, being the programmer type that I am, I let Kword do what it could, and improved the rest in text mode, previewing directly in ghostview.
One shouldn't have to be a programmer to whip together a friend's job hunting paperwork. It takes us back to the old days, when a CP/M box could be a decent terminal for a brighter Postscript printer, if you slipped it a sneaky enough program.
Oddly enough if I had just thrown it together in HTML it would have been pretty quick. But that would have been in a plain old text editor too -- since the state of the art in WYSIWYG editors for HTML is about the same. Bluefish and August seem to have them beat all over the place. I think I like Bluefish better, it has a feel very similar to HTMLedPro which I used when I used to live more closely with that other operating system.
If the Dot Com Fallout has made your company foolishly let you go, at least the Linux world has room for you. You can check out Linux Journal's Career Center (http://www.linuxjournal.com/employ), Geekfinder (http://www.geekfinder.com), the Sysadmin's Guild (SAGE) Job Center (http://www.usenix.org/sage/jobs/sage-jobs.html), or pay attention to your local area papers for when major high tech Job Fairs are in your area, so you can go to them. There are also some really generic job sites like Dice.Com (http://www.dice.com) or MonsterBoard (http://www.monsterboard.com). If you hate the corporate mold, check out some of the project offers at SourceXchange (http://www.sourcexchange.com) or Collab.Net (http://www.collab.net). Or put up your consulting shingle by listing yourself at Linuxports (http://www.linuxports.com) and getting listed into a few search engines.
Me, I don't have to worry about getting into search engines, do I?Have a happy April!
What's this word?From dana gillen
Answered By Jonathan Markevich,
Chris Gianakopoulos, Breen Mullins, Huibert Alblas, Heather Stern
![]() Can you tell me what PCMICIA stands for? Thanks!
Can you tell me what PCMICIA stands for? Thanks!
[Jonathan] Sure. "People Can't Memorize Computer Industry Acronyms". (You have an extra "I" in there)
Seriously, I believe it's "Personal Computer Memory Card Inter... ..." Uh, I forget the "A", thus proving the previous statement.
However, they've since ditched the obscure acronym and now call it "PC Card", since "Memory" was very rarely what it was about.
- A good resource for ATDA (All Those Dratted Acronyms) is the Babel File:
http://www.geocities.com/ikind_babel/babel/babel.html
HTH.
In Gnome is a litle utility called Gdict (Foot->utilities->Gdict) If you go to Settings->preferences->Server->Database you can select V.E.R.A. (Virual Entity of Relevant Acronyms) It's great for looking up Acronyms (Accept the 'wrong' or funny ones are not listed, is there a place those are listed)
Hope I could help
http://www.tuxedo.org/jargon
...although, oddly enough, this one isn't in there. We'll have to fix that!
Unable to Install LinuxFrom N P
Answered By Ben Okopnik
see attached equipment list
![]() I am trying to install RH 6.2 on the WD 12.3GB drive. However, it hangs
during the installation (after the partitions are formatted and progress
dialogs starts).
I am trying to install RH 6.2 on the WD 12.3GB drive. However, it hangs
during the installation (after the partitions are formatted and progress
dialogs starts).
![]() Well not quite true. If i don't select any packages (no X,
compilers, multimedia, etc) to install, it installs fine.
Well not quite true. If i don't select any packages (no X,
compilers, multimedia, etc) to install, it installs fine.
Another option is to try installing another distro; I'm a real Debian zealot, myself. One of the many reasons that I really like it is that something like the above procedure is already one of the standard installation options: the base system install takes 5-10 minutes, you tell 'apt' which of the many available servers you want to use, and walk away. 'apt' can use FTP, HTTP, local CDs, or packages right off the HD - and you can mix-and-match sources however you like. Dependency problems? What are those? <grin>
![]() When the
installation hangs there is no response to any keypress and it doesn't hang
at the same part of the installation i.e. at the beginning (just starting),
middle, or end (seconds to go).
When the
installation hangs there is no response to any keypress and it doesn't hang
at the same part of the installation i.e. at the beginning (just starting),
middle, or end (seconds to go).
DNS and telnetFrom crabe
Answered By Mike Orr
Hi, How do you get telnet working on your own machine as referred to in the DNS HOWTO, i.e telnetting at 127.0.0.1 ? I got telnet working to reach my ISP but never got around telnetting 127.0.0.1. So I gave up DNS. I have looked around all the HOWTOs available, and perhaps it's too simple for mentionning. I am running LinuxPPC2000. Thanks for any answer.
- Nobody is listening on the telnet port. If so, you'll get an immediate "connection refused" error. Telnetd is normally started from inetd. Uncomment the telnet line in /etc/inetd.conf and "killall -HUP inetd".
- Your loopback devide is not configured. What happens when you run "ping 127.0.0.1"? If you get no response, do "ifconfig". There should be a stanza for device "lo". If not, run "ifconfig lo 127.0.0.1" and/or "ifconfig 127.0.0.1 up". (If you're still running kernel 2.0.x, follow that with "route add -net 127.0.0.0"). Then look at your network startup scripts to see why it isn't being activated by default.
- Inetd runs telnet through a tcpd wrapper for security, and you're failing the tcpd check. This would cause the connection to do nothing (at least nothing visible) and then disconnect after a couple seconds. See "man tcpd" and "man 5 hosts_access".
- You are telnetting to port 53 and your nameserver is not running. If so, you'd get a "connection refused" error. If you installed named (bind), find out why it isn't running.
The TAG security hawks will send a follow-up if I don't also mention that telnet is a security risk bla bla bla because it doesn't encrypt your password or your data. Think twice before running telnetd, and think a third time before allowing tcpd to allow telnet connections from outside your local network.
Help on LILO stopping at LIFrom Alessio Frenquelli
Answered By Heather Stern
Hello,
I start thanking you for any help ... I am stuck at this stage, I am not a
GURU on LINUX and I cannot overcome the problem.
Therefore I cannot really point to what has been changed or went wrong.
Under the Internet I found many, many errors entries pointing to LILO not being able to load in a disk that is above the 1024 cylinders
But ever since the new version those are old messages. The normal solution until it came out, was to create a tiny /boot near the beginning of the free space - even most dual booters could manage to slip a 20 Mb partition below the boundary. This works because on the kernel and bootmap needs to be below the line; once the kernel is loaded you are no longer working with real mode BIOS issues at all, you are fully in protected mode and can access everything the kernel is built for.
![]() In my case LILO always worked so far, and I did not surely changed the disk
size, done any repartitioning under Windows NT nor under Linux.
In my case LILO always worked so far, and I did not surely changed the disk
size, done any repartitioning under Windows NT nor under Linux.
Under Windows, I have run Program => PartitionMagic =>PartitionInfo and I am attaching the output of the command to this email in case you need to see in details my machine's partitioning.
Dual bootable Laptop, Toshiba Tecra 8100; one partition is Windows NT workstation, the other is Linux RedHat 6.1.
Linux 6.1 LILO does not longer boot properly. Just stop at the word "LI".
When running : << /sbin/lilo >> I got messages:
[root@afrenquelli /etc]# lilo
Warning: device 0x0305 exceeds 1024 cylinder limit
Warning: device 0x0305 exceeds 1024 cylinder limit
Warning: device 0x0305 exceeds 1024 cylinder limit
Warning: device 0x0305 exceeds 1024 cylinder limit
Added linux *
[root@afrenquelli /etc]#
By the way, Redhat 6.1 is a bit old, and lilo itself was updated last year so that 1024 cylinder issues are not a problem for it. (You'll also want to keep up to date on RH security updates, not quite as drastic as upgrading the system entirely.)
With the newer version, you can add the keyword
LBA32
into the top of your /etc/lilo.conf and it would use a different method to know where things are on the disk.
Being a boot loader, it's critical for lilo to know precisely where the kernel resides on your drive. Moving your kernel file (even if you then moved it back) or your system maps is a good reason to run /sbin/lilo.
![]() Some machine's characteristics:
Some machine's characteristics:
[root@afrenquelli /tmp]# df -k Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda7 1510032 1201268 232056 84% / /dev/hda5 23302 2648 19451 12% /boot
[root@afrenquelli /etc]# lilo Warning: device 0x0305 exceeds 1024 cylinder limit. Use of the 'lba32' option may help on newer (EDD BIOS) systems. Fatal: sector 19926490 too large for linear mode (try 'lba32' instead)
------------------------------------- file /etc/lilo.conf contains
boot=/dev/hda7
Most people would have it in the MBR ... /dev/hda with no number. Do you have an NT boot menu pointing you into Linux? Because I also notice that you don't have a chain loader stanza, to ask the item below to offer you your NT boot setup.
![]() I did not "fiddle" with Linux at all before this error appeared !
I did not "fiddle" with Linux at all before this error appeared !
![]() So , I changed in /etc/lilo.conf the value "linear" with "lba32", and then
/sbin/lilo runs fine with :
So , I changed in /etc/lilo.conf the value "linear" with "lba32", and then
/sbin/lilo runs fine with :
c[root@afrenquelli /etc]# lilo -v LILO version 21.6-1, Copyright (C) 1992-1998 Werner Almesberger Linux Real Mode Interface library Copyright (C) 1998 Josh Vanderhoof Development beyond version 21 Copyright (C) 1999-2000 John Coffman Released 16-Dec-2000 and compiled at 17:04:30 on Jan 9 2001. Reading boot sector from /dev/hda7 Merging with /boot/boot.b Boot image: /boot/vmlinuz-2.2.12-20 Mapping RAM disk /boot/initrd-2.2.12-20.img Added linux * /boot/boot.0307 exists - no backup copy made. Writing boot sector.
At this stage I "REALLY" hoped that the problem went away, but I still get only "LI" at boot time, I can only use the boot diskette to get into Linux.
![]() ATTEMPTS TO SOLVE IT
===================
ATTEMPTS TO SOLVE IT
===================
Thinking that the latest version of LILO "could" have fixed this problem, I have downloaded LILO 21.6.1-1 from http://rpmfind.net/linux/RPM/contrib/libc6/i386/lilo-21.6.1-1.i386.html
I have then upgraded my LILO with : "rpm -Uhv <nomefile>.rpm"
You should also keep up to date on RedHat security updates for RH 6.1. (Not directly related to this, just a good idea)
Any other recent installs or upgrades?
![]() The upgrade completed fine, and then when I try to run /sbin/lilo I got:
The upgrade completed fine, and then when I try to run /sbin/lilo I got:
[root@afrenquelli /etc]# lilo Warning: device 0x0305 exceeds 1024 cylinder limit. Use of the 'lba32' option may help on newer (EDD BIOS) systems. Fatal: sector 19926490 too large for linear mode (try 'lba32' instead)
![]() So , I changed in /etc/lilo.conf the value "linear" with "lba32", and then
/sbin/lilo runs fine with :
So , I changed in /etc/lilo.conf the value "linear" with "lba32", and then
/sbin/lilo runs fine with :
c[root@afrenquelli /etc]# lilo -v LILO version 21.6-1, Copyright (C) 1992-1998 Werner Almesberger Linux Real Mode Interface library Copyright (C) 1998 Josh Vanderhoof Development beyond version 21 Copyright (C) 1999-2000 John Coffman Released 16-Dec-2000 and compiled at 17:04:30 on Jan 9 2001. Reading boot sector from /dev/hda7 Merging with /boot/boot.b Boot image: /boot/vmlinuz-2.2.12-20 Mapping RAM disk /boot/initrd-2.2.12-20.img Added linux * /boot/boot.0307 exists - no backup copy made. Writing boot sector.
At this stage I "REALLY" hoped that the problem went away, but I still get only "LI" at boot time, I can only use the boot diskette to get into Linux.
Maybe you need to take the linear or lba32 mark out ??
If I could avoid to rebuild the LINUX partition would be GREATLY appreciated, since I am not a Linux expert and I would need some guidance also lots of other software is installed and I would like to avoid to reinstall the all lot !
![]() Could I just de-install LILO and re-install LILO ?
Could I just de-install LILO and re-install LILO ?
Then, you should be able to run lilo again to install it as a fresher instance.
![]() Or should I add something into the /etc/lilo.conf and try to run "lilo"
again ?
Or should I add something into the /etc/lilo.conf and try to run "lilo"
again ?
Could I somehow just rebuild the "booting" portion of the Linux, and if so, could you please provide detailed instructions on how to do it ?
The README, however, is the right place to start, because unlike most readme files around here (which can be summarized "so this is the foo program, I created it because bla bla. It's under the GPL/artistic/whatever license, see COPYING. If there are any bugs (hope not) get in contact with me at ...") it has some serious data in it. Consider it your quickstart guide to a working LILO.
You've already done a number of the obvious things, so, let us know if the uninstall/reinstall trick works, and if that readme isn't helpful to you we may be able to translate it to plainer english.
![]() Kind regards,
Kind regards,
alessio
Here's where my "doc" script would come in really handy: all you'd have to do is type something like "doc lil", and it would give you a numbered list of all the subdirectories in your "doc" directory that start with 'lil'. Typing that number enters the directory and shows you a numbered file list; typing one of those numbers displays the file, no matter what its format is. When you exit the viewer, it shows you the list again, and gives you a chance to "fish around" in subdirectories and other files.
I know I sent it into LG as a 2-cent tip quite a while ago, but I believe I've made a few improvements since then, so here it is:
See attached doc.bash.txt
Heather,
thank you for your complete and prompt reply.
I will provide here some answers from the queries that you had. At this stage it seems that the problem is caused by one of our product, that I have recently installed under Linux. After reporting the LI problem to our support team, I received a reply where they state that this product ast times seems to affect LILO, and to cause the problem that I have described to you.
I am still awaiting from our support team, if they know how to fix the problem of LILO.
And now to your questions:
![]() Yes, I have installed a new Micromuse Package under LINUX. After the
installation I rebooted few times without problem, but then one day, LI
started to happen.
Yes, I have installed a new Micromuse Package under LINUX. After the
installation I rebooted few times without problem, but then one day, LI
started to happen.
Warning: device 0x0305 exceeds 1024 cylinder limit
![]() No changes on disk size, or disk partitioning under Linux or under NT. I
never run /sbin/lilo before , so I cannot tell you if this was a problem.
But LILO always worked before.
No changes on disk size, or disk partitioning under Linux or under NT. I
never run /sbin/lilo before , so I cannot tell you if this was a problem.
But LILO always worked before.
I did not "fiddle" with Linux at all before this error appeared !
![]() I use Linux to run Micromuse products, and as I said, the problem started to
happen since I installed one of our package. Other people installed it on
their laptop, but they did not report the error. Support told me that at
times this product is know to cause some problem with LILO, but they are not
too sure.
I use Linux to run Micromuse products, and as I said, the problem started to
happen since I installed one of our package. Other people installed it on
their laptop, but they did not report the error. Support told me that at
times this product is know to cause some problem with LILO, but they are not
too sure.
Maybe you need to take the linear or lba32 mark *out* ??
![]() You mean, remove linear or lba32 from lilo.conf and try to run lilo again ?
I will try this.
You mean, remove linear or lba32 from lilo.conf and try to run lilo again ?
I will try this.
![]() So I should just run :
So I should just run :
Thank you for your help once again, I will keep you posted !
ciao, alessio
Heather,
here is how I got this problem fixed with the help of the support personnel in our company
Thank you once again for your support !!!
Support adviced me that the following recovery procedure for LILO problems is to be used for Laptop that have dual boot partition, NT & Linux, when the menu received at boot time shows OS LOADER, and then it presents 2 choice , Windows NT or Linux.
Steps taken:
mount -t msdos /dev/fd0 /mnt/floppy
/dev/hda7 Mounted /
/dev/hda5 Mounted /boot
dd if=/dev/hda7 of=/tmp/bootsect.lnx bs=512 count=1
PROBLEM solved, LILO loads correctly.
Ciao, alessio
How can you do a recursive search to find broken symbolic links?From bandido
Answered By Ben Okopnik, Faber Fedor, Mike Orr
![]() I found the odd broken link after a few upgrades, and was wondering how
can I hunt down any other such beasties, 'ls' doesn't have any suitable
way to delimit, and poking about in man pages for find etc made me quite
nautious.
I found the odd broken link after a few upgrades, and was wondering how
can I hunt down any other such beasties, 'ls' doesn't have any suitable
way to delimit, and poking about in man pages for find etc made me quite
nautious.
So, to find all the links on your system, you would type
find / -type l
Simple, no?
What's needed here is the "symlinks" program, written by Mark Lord. It will find and classify all the links, hard and soft, in the filesystem. If you want to see all the dangling (i.e., broken) links on your system, just type
symlinks -r / | grep ^dangling # Recursive search starting from /
If you want to delete all the broken ones, just enter
symlinks -dr / # Recurse and delete broken links starting from /
For me personally, this wouldn't work too well. I use dangling links as placeholders; as an example, I've disabled NFS during the boot procedure by "breaking" the symlink in "/etc/rc2.d":
S19nfs-common -> ../init.d/nfs-common # Original link
S19nfs-common -> ../init.d/nfs-commonXXX # Dangling!
If I should need to restore NFS, a 5-second fix will do it, without having to figure out what directory the link should go into, where in the process it should load (as determined by the number after the 'S'), or where it should point.
![]() Thank you Ben, and others, a google search found "symlinks", although it
only appears to be available for Debian.
Thank you Ben, and others, a google search found "symlinks", although it
only appears to be available for Debian.
<http://packages.debian.org/stable/utils/symlinks.html>;
They always provide a link to the tarball from which the package was made, and you can compile it yourself. <grin> I like Debian. A lot.
( find / -type l | xargs file ) | grep 'broken symbolic link'
![]() The symlinnks prog worked a charm, indeed ot cleaned up everything nicely,
changing absolute to relative links too, lovely.
The symlinnks prog worked a charm, indeed ot cleaned up everything nicely,
changing absolute to relative links too, lovely.
The real issue, is my rampant stupidity, since after downloading symlinks, lo and behold, I discovered it is part of Mandrake 7.2 which I use.
I had pissed about pouring over man pages trying to find out how to delimit a search to find the buggers, only to discover my salvation was close at hand.
I have received several TAG replies, and I must say the 1st was within
45 minutes. Astounding
![]()
![]() Keep it up guys.
Keep it up guys.
-- Merp!
BIOS passwords - Bane of my existanceFrom Unidentified Querent
Answered By Ben Okopnik, Heather Stern
Can I send the Answer Gang a question and ask that I not be identified? PLEASE??? Reason: I feel stoopid enough already. Hey, you may decide that it isn't even a good idea to print this one. I doubt I would...
As Editor Gal I can make sure this thread is scrubbed thorughly of your identity, and will.
![]() It's really TWO questions but the second question is not necessary if
you have an answer to the first (which I doubt).
It's really TWO questions but the second question is not necessary if
you have an answer to the first (which I doubt).
(1) I read your "LILO:Password Protected Entries" article in the new March LinuxGazette. Though I do not have a LILO question, I'd like to ask you to follow up on something else you touched on in that article.
One of my toys is a CTX EzBook 800 laptop which is currently running SuSE 7. A while back, I thought it would be a good idea to block access to "Lorraine's" BIOS settings. I set the BIOS password so that access to the BIOS is blocked but booting is not. Good thing. I soon forgot the password.
![]() This isn't a HUGE problem since I don't have to access the BIOS very
often but booting from a CDROM is now impossible (without using a boot
floppy) and setting or correcting local time is a real pain in the rump
(see question 2).
This isn't a HUGE problem since I don't have to access the BIOS very
often but booting from a CDROM is now impossible (without using a boot
floppy) and setting or correcting local time is a real pain in the rump
(see question 2).
hwclock --systohc
![]() I know BIOS backdoors exist but I've been unable to find one for mine.
I know BIOS backdoors exist but I've been unable to find one for mine.
![]() Lorraine's got a PhoenixBIOS 4.0 Release 6.0.67A dated 1985 - 1997. In
the year or so since I got stoopid, I've scoured the Internet for info
on what the Phoenix backdoor might be - I found nothing. I even
contacted the manufacturer, CTX, to see if they would help. All they
would suggest was popping open the laptop and removing the BIOS battery,
something I'm not sure I'd do even if I knew how to (yeah, I know I'm a
wimp).
Lorraine's got a PhoenixBIOS 4.0 Release 6.0.67A dated 1985 - 1997. In
the year or so since I got stoopid, I've scoured the Internet for info
on what the Phoenix backdoor might be - I found nothing. I even
contacted the manufacturer, CTX, to see if they would help. All they
would suggest was popping open the laptop and removing the BIOS battery,
something I'm not sure I'd do even if I knew how to (yeah, I know I'm a
wimp).
But the BIOS is usually a watch battery and about as easy to deal with as a watch once you have it.
You may want to get printouts and take notes during bootup of things that are BIOS options as far as you know them. dmesg may help some.
![]() So... The questions remain: Do you know how to foil this sucker or,
failing that, can you
So... The questions remain: Do you know how to foil this sucker or,
failing that, can you
(2) Tell me how to reset the BIOS time from within SuSE 7? That'd be a piece of cake with RedHat's linuxconf but I've yet to find anything in SuSE that would do the trick. Don't even ask about yast and yast2... Change time zone, yeah. Change time, no way.
As for linuxconf, err, I haven't had good luck with it myself. YaST (yess, that's really how the command is spelled) is the admin tool under SuSE, but as you can see, it's really more about installing stuff, not so much for sysadmin work.
!!! WARNING WARNING WARNING !!!
Do not do this if you don't know what you're doing! Wiping your CMOS will make your system unbootable. You must know at least the CHS (cylinder-head-sector) values for your hard drive, and either know or be able to figure out the other necessary settings. If you dump your CMOS and get stuck, you are on your own!
Now that I've scared you into twitching fits and heebie-jeebies...
Most BIOSs today are auto-configuring, and will either auto-detect or give you the option of auto-detecting your HD; Phoenix BIOS certainly does that (it's been my favorite for many years now.) For myself, if I'm going to do that sort of thing - and I've worked on many, many machines where the owner had set a BIOS password and forgot it - I'll boot DOS, save a copy of the settings to a bootable floppy via 'savecmos', and only then blow away the password via 'cmosedit'. That way, if things go truly awry, I can at least get back to where I was and try something else. The 'savecmos' utility (including 'cmosedit') is available all over the Net, e.g. <http://members.tripod.co.uk/paulc/cmosutil.zip>;.
![]() P.S.: I bought this laptop new from Sears (don't laugh) and have the
receipt and everything. Honest!
P.S.: I bought this laptop new from Sears (don't laugh) and have the
receipt and everything. Honest!
![]() Thanks!!!
Thanks!!!
Signed: Stoopid
Making the ConnectionBy Anthony E. Greene
Somewhere in the shuffle the original querent's message has been lost, but basically, they asked about connecting their hospital together, so that the doctors could communicate with ER and ICU, staff could access suitable records or charts, etc. The doctors are not dumb people, but they already have a specialty and a job to do, so it has to be a pretty clean setup.
You could setup a PPP server and use the modems to make dialup PPP connections. This would allow you to use graphical network applications such as browsers, FTP clients, and network file managers such as GNOME's GMC.
Without knowing more about what resources you have available, I cannot make specific recommendations. Red Hat, Mandrake, Slackware, Debian, SuSe, and Caldera all come with the tools you'll need to setup a network. I have not used Corel but I've read that they left some server and development packages out. That may be fine for home desktops, but in a business environment I'd want a distribution that includes everything I might need and lets me choose what to leave out or disable. You will need some server packages to implement a solution and you will want development packages available in case you need some tools that are not available in a package.
First you need to figure out what applications will be used for data entry. Eventually, you may find you need a database application, but it sounds like what you need right now is something that generates documents that can be shared. If the results are to be typed out as free text, a text editor is probably the best way to go. The text editors that ship with GNOME (gedit) and KDE (kedit) are both adequate, but something like Nedit has fewer bugs and more power. If you need to use templates for data entry, you could either create some read-only files as templates or create templates in a StarOffice for use with its word processor.
For something with a little more familiarity to GUI users, AbiWord can edit plain text, RTF, and simple DOC files. It has a toolbar that any Word user could use with no problem and is fairly lightweight. AbiWord is part of GNOME Office and ships with the Ximian (Helixcode) desktop.
There are some Open Source medical applications available. Try searching for them at Freshmeat <http://www.freshmeat.net/>;, Sourceforge <http://www.sourceforge.net/>;, and Google <http://www.google.com/>;.
If you really need an integrated solution for Linux desktops at a minimal cost, StarOffice is a good choice. The latest version (5.2) is still a serious memory and resource hog and takes time to startup. But once it's running, its speed is reasonable, considering its large feature set.
I haven't used Applixware, but it is supposed to be very usable and programmable. The latter may prove useful to you if you plan to use it for data entry. Applixware is not free, but is a lot less expensive than MS Office.
For intranet browsing and email, I still recommend Netscape Communicator 4.7x. It works fairly well, is stable on non-Java pages, and supports LDAP and HTML mail. These last two features are very useful in an organizational mail client. Netscape 6.x does not support LDAP and StarMail's LDAP interface is too difficult to be useful. An LDAP server is not too hard to setup for small organizations and is great for maintaining an organizational address book.
After the data is entered, you will need to make it sharable. I suggest each department have a directory that only they can write to and any authorized use can read. Setting up these groups and permissions is not too complicated, but is more than I want to cover here.
The key thing about sharing is deciding what protocols you will use to share. Client applications for FTP and HTTP are easy to use. Both servers are easy to install. But the permissions scheme for HTTP is separate from the system user and groups settings. That makes it complicated to setup if you have multiple groups of users that need different permissions. So I don't recommend using Apache and HTTP to share the documents.
You can use FTP, but the WuFTPd server that has shipped with many distributions is an almost constant source of security problems. Just make sure you disable anonymous logins if you choose to use FTP. Web browsers are great FTP clients because they can launch external applications to view documents. The only real problem with FTP is that passwords are sent over the network unencrypted. On a small, closed network this should not be a problem.
This is probably more than you expected, but it's just enough to get you started. Running a network will mean learning a lot at first, but it should run well after it's setup.
Setup of Microsoft Outlook Express 5 for Sending of Clear TextAnswered By Chris Gianakopoulos
[Heather] We get so many people who send us perfectly good questions, in
HTML, which drives some of our mailers crazy. It's not surprising that
someone with a crippled Linux box would reach for a nearby Windows system
to send the mail. So, here's some help for you. Utterly self serving,
to help us get plaintext
![]()
I glanced at the March 2001 Linux Gazette and noticed your (subtle) request for the steps needed to set up my Outlook Express mailer to send clear text. I read in a textbook (circuits) that a promise made is a debt unpaid. I will recoin the phrase to "A request made is a response unpaid". Therefore, I will post you a response which attempts to provide a coherent step of steps to achieve our goal.
I actually executed these steps while typing the steps into a text file using vi for DOS. I use my Microsoft machine when I email late nights. I hope that this is coherent! Anybody can sanity check me, of course (that's what teams do -- review each other's work). Here are the steps.
You're all set!
-------------------- End of Instructions ----------------------
The line lengths of the steps look short because I typed those steps into a text file, using vi, and I always keep lines less than 80 characters. I'm from the old days of using terminals (not ASR-33 teletypes although once I had a General Electric Terminet 300 TTY for a printer), so I avoid line wrap.
Thank you and Ben for the encourgement that you give. I'm still a cross between a soon to be Linux hacker and an embedded software hacker (they call me an engineer, but, I think that is questionable).
You are a kick-a## teem! Keep up the good work!
Chris G.
iconsFrom Joseph Ibbitson
Answered By Thomas Adam
Hello Gang
I'm an old guy (81) trying to learn Linux with very little computer experience. Strangly, with so much help available online I find it easier to learn Linux than Windows. However, one problem I have is just what does the various icons indicate when left clicking on the file tree. I see gears, folders, screens with and without locks, apparently sheets of paper, some with corners folded over, cubes of assorted colours, etc. etc. I am running Mandrake 7.2. My main problem is that I cannot find any instruction on how to navigate the file system when I don't know anything! I have yet to find a book that explains the very basics. Example-how do I find the proper way to install software. I have installed ,I beleive ,Sane, see it listed but how do I arrange it so I can Use it?
I hope you will exscuse this rambling requests. I really want to master Linux but until I can get over the basics I am having trouble. Any help you can give me will be sincerely appreciated. Thank You.
-- Joseph
Judging from your description, I assume that you are using KDE. The icons that you see, are supposed (although I admit, I have trouble with this) to help you understand what KFM (the KFile Manager) is doing.
Cog wheels indicate that the program is executable folders indicate just that, that they are folders screens usually indicate that the program is a script of sorts. Try clicking on it once and opening it in a text editor such as "kwrite" or "kedit"
In really basic term, the Linux File system, has various components to it....
the root of the file system "/" holds folders such as:
etc home usr rootmnt
"etc" holds most of the initialisation scripts that loads as linux is booting (i.e. the output from the kernel)
"home" is the folder which stores the users work that is on the system
"root" is the folder where all of "roots" work is stored. Root is the system admin of a linux computer and has read\write permissions on every file. In other words root controls everything.
"mnt" holds the symbolic links to other partitions on your local machine
"usr" is the folder which stores main executables, man pages, etc.
Using your file manager as before replace what is already entered at the top, and put /usr/bin
here you'll find a lot of cog wheel icons. This is the main folder which will store all your programs.
Since you are using Linux-Mandrake (as do I) installing software is often done by using RPM's (RedHat Package Manager). To install these, insert your CD and at the console, type:
cd /mnt/cdrom/Mandrake/RPMS
then type:
ls
and you'll see a huge long list. To install any RPM (regardless of the path..folder that it is stored in) type:
rpm -i nameofrpm-1.0-0mdk.i586.rpm
and that should install it (assuming there are no module dependencies!)
I know this must seem very vague and confusing, but I believe I have started you off....
Corrupt Tar ArchiveFrom Mohamed Ezz
Answered By Ben Okopnik
I have 'ftp'ed an 8MB tar archive file and cannot untar it. I did not do a checksum after the ftp because I know ftp should do this on its own. When I run: $ tar xvf myfile.tar I get:
tar: This does not look like a tar archive tar: Skipping to next header tar: 447 garbage bytes ignored at end of archive tar: Error exit delayed from previous errors
My problem is I lost the files of which the archive is composed of, so I can't regenerate it. To make things worse, the archive file on the source machine (from where I did the ftp) was deleted. So the local archive is my only hope of retrieving my files.
Any help is greatly appreciated.
Ezz
tar xvzf myfile.tar
Note that the file really should have been called "myfile.tgz", if that's what it turns out to be.
![]() Hello Ben,
That was it! Thank you so much. Excuse my ignorance about the
extension.
Ezz
Hello Ben,
That was it! Thank you so much. Excuse my ignorance about the
extension.
Ezz
masquerade in sendmail is broken.From Clark Ashton Smith
Answered By Ben Okopnik
![]() In issue 21 there was an article by the "The Answer Guy"
which explained how to use the masquerade feature in a
local sendmail configuration.
In issue 21 there was an article by the "The Answer Guy"
which explained how to use the masquerade feature in a
local sendmail configuration.
On the other hand, the information that is available for setting up sendmail is generally pretty poor, and not at all intended for the casual user; it's pretty nightmarish out there.
![]() It worked fine with Redhat 5.2 Linux, but I just tried
it on Redhat 6.0 and the FEATURE(nodns) reports that it
is a no-op and I should use the service.switch file to
disable dns lookup. Well after 5 hours of reading
sendmail faqs, newsgroups and tips I am no closer to
making this work.
It worked fine with Redhat 5.2 Linux, but I just tried
it on Redhat 6.0 and the FEATURE(nodns) reports that it
is a no-op and I should use the service.switch file to
disable dns lookup. Well after 5 hours of reading
sendmail faqs, newsgroups and tips I am no closer to
making this work.
I have a simple network with a ppp connection to the internet. Many folks out there must have similar setups.
Could someone please show us how to get the masquerade feature working again?
If you set it up and it does what you need, you owe the Oracle an article on your experience. <grin> Just kidding. Hope this helps.
neighbour table overflowFrom Berg Alexander
Answered By Heather Stern
hi,
i have the problem that i have a running terminal-server (booting over net via Root-NFS) system. now we want to add a second subnet to the server, and all should be okay in the config files. BOOTP is working, TFTP is working but the client is not able to mount the root-fs, with the error message "neighbour table overflow"... we also have changed the nfs-server, no luck...
bye
Alexander Berg
It means that your arp cache is overflowing because your machine can't tell who is on its own subnet... its neighbors. Which usually means your localhost setup is broken (because lots of applications use networking internal to your machine - which is always on its own subnet, so those packets should never even escape the computer) or, far less commonly, that your netmask for your own external address is wrong.
Sadly, tftp and network booting are things I'm not so familiar with, so perhaps one amongst the rest of The Answer Gang can help tell you where to correct your terminals' localhost setup.
Because this happened when you're adding a new subnet, you may find a need to set up machines on both subnets with ethernet aliases. When properly set up then running ifconfig should result in something like this:
eth0 Link encap:Ethernet HWaddr so:me:he:xv:al:ue
inet addr:192.168.129.15 Bcast:192.168.129.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5939693 errors:0 dropped:0 overruns:0 frame:0
TX packets:5971444 errors:0 dropped:0 overruns:0 carrier:0
collisions:8308 txqueuelen:100
Interrupt:10 Base address:0xff00
eth0:1 Link encap:Ethernet HWaddr di:ft:he:xv:al:ue
inet addr:192.168.64.2 Bcast:192.168.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:10 Base address:0xff00
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:1
RX packets:320906 errors:0 dropped:0 overruns:0 frame:0
TX packets:320906 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
Best of luck!
note, Alexander put antispam hooks in his address when mailing us, so he never saw his emailed response. We still hope this helps him and others with the dreaded Neighbour Overflow.
VIDEO CARDFrom Tracy
Answered By Heather Stern
DEAR ANSWER GUY:
Greetings.
Do you know who is making two-monitor cards for 98SE?
Thanks.
So, as a matter of hardware, you might not need one card that does two monitors at a time; some video cards are okay with having two of the same kind in the computer, but then you need a video driver that will survive the experience. Some past linux'er described his troubles doing this at (http://www.tarball.net/docs/multihead_fb_howto.html) -
The keyword you probably want to try in the search engines is "dual monitors" or "multi-headed" video cards.
Perhaps a visit to one of the windows magazine sites would be more useful. With luck they might have had an article on the topic in the last few months so you could get some reviewer comments about which are any good in your platform.
![]() ENTHUSIASTICALLY YOURS,
tracy
ENTHUSIASTICALLY YOURS,
tracy
DEAR HEATHER,
Thanks. Matrox answered too and it appears that Matrox has a card (G450) with two outlets which allows two monitors to operate as one big one.
ENTHUSIASTICALLY YOURS,
tracy
fat versus inodesFrom narender
Answered By Heather Stern
dear sir ,
i want to know why the viruses are so common in dos and windows while unix is ammune to these ?
NT has slightly better natural defenses, but also gets some interesting ones.
The ability of viruses to spread seems to be enhanced by some other features which you would otherwise find handy, like the ability of several apps to share a single macro language.
This is why there are so many antivirus companies - even after they've gone and bought each other up a bunch. They're in the business of selling immune systems and the ability to spot that the machine is "ill" before the symptoms get obvious.
![]() is it all due to inodes
concept in the unix ?
is it all due to inodes
concept in the unix ?
The main case I know of was basically a research virus - it could only spread if the system's user also did a few things to improve his ability to access the system as root when working remotely. Very few people do that, or even want to.
We have much more to fear from crackers trying to generate these failures deliberately, than from viruses trying to invade our systems automatically.
However, it's worth noting that LILO is a master boot record - it looks different, but it's still an mbr, so any virus you catch in a dual boot system that attacks the mbr, will attack your LILO. That it's code "coming from Linux" won't save it. It does have a few defenses, but it's not very big. Many other bootloaders exist too, and if you're living in a virus rich environment you might want to use one that specifically has some antivirus features.
![]() if so will you please tell me in more detail
the responcible differences between fat and inodes tables ?
if so will you please tell me in more detail
the responcible differences between fat and inodes tables ?
needing yr help
regards
narender
FAT is a table at the beginning of the disk, which divides the disk up into "clusters" and marks how each cluster is used. (There's actually two tables, so that there is a safe copy in case of problems, but normally, they contain the exact same data.)
inodes contain a small amount of information (called metadata) about the things they point to, and the things they point to can be put anywhere on the disk, because part of the metadata says where that is. We have a different way of keeping track of what disk space is still free to allocate. For more about this, study about the "superblock" since we do have things that affect how many inodes we can use, and so on, as options when we format a disk under linux.
So it is simplest to say that the difference is that FAT directly represents the disk, but Linux' system indirectly represents the disk.
Installing Linux without cdromFrom Berry Vos
Answered By Ben Okopnik
Hello,
The other day I bought a second-hand computer. I already had a laptop-computer with SuSE linux installed, which is running perfectly. I bought the new pc to install linux to experiment a bit without messing up my primary computer in case I do something wrong. The problem is that the new pc has no cdrom. Also, neither the new pc, nor my laptop has a network card. I wonder if it is possible to connect the laptop with the pc with a null-modem cable and install linux off of the laptop on the pc. Is this possible? If so, how?
I hope you can help me.
The one thing you want to be aware of is that, at best, you'll be pumping the data across at just over 11kB/s. To put that in perspective, copying the installation CD to your laptop (this is not necessary for the installation, but it'll give you an idea) will take approximately 16 hours. I've done a Debian installation by pumping across the base install files (24MB, about 40 minutes) and running them, then setting up 'apt' to FTP the individual files from the source machine via the serial link. I let it run overnight; by the time I woke up the next morning, it was all done.
Not that this is a big deal - it wasn't to me, anyway - but you want to be aware of the time scale involved. <grin> I do love my serial link. It lets me get out of buying a PCMCIA NIC for a laptop that's on its last legs anyway, and 99% of the files are small enough that speed isn't really an issue.
Installing RedHat 7.0 and a driver for the Chipset Cirrus CL-GD5436Answer By Wilf
Hello and Good'ay,
Installing RedHat 7.0 was nothing special though programmes seem to run a bit faster than under RedHat 6.0... but:
Althoug RH 7.0 does recognize the graphics chipset Cirrus CL-GD5436 (on a Compaq Deskpro 2000) it does not provide the correct driver as RH 6.0 does (though after a long and despairing search I found the information that the driver was no longer included in "XF86_SVGA-3.3.6-33.rpm" shipped with RH 7.0). The mouse pointer under X (I use WindowMaker) was displayed as a barrecode found on products, windows overlapped and were redrawn in a rather chaotical and randomly manner. Other Window Managers (KDE or GNOME) did not display it any better.
Falling back to RH 6.0 or coping with this particular problem? I did both, but used some (perhaps not necessary force) to install RH 7.0 all the same.
I first installed RH 7.0 and configured graphics display with default values. After installing and BEFORE calling up a graphical display with "startx" I force-installed the driver from RH 6.0 with:
rpm -i XF86_SVGA-3.3.3.1-49.rpm --force
and -much to my delight and would ya believe it, matey?- all possible mode of graphical displays (640x480, 800x600 and 1024x768, all 16bits colour) now work as expected: very good indeed!
In the event that this procedure could have been done otherwise, I'd appreciate a comment.
Yours Linuxely,
Wilf
P.S. I take it that section "2 cent tips" rather means "2 US ¢ Tips" or are you talking EURO ¢? Mind you, it's just a thought ...
Forcing the old series rpm into place in this fashion is just the right thing here. You should be safely able to apply X parts from 6.2 ... XFree86-3.3.6-20.i386.rpm ... as an upgrade (-U) to the 3.3.3 you successfully installed, if you like.
cd-writing mini-howtoAnswer By Chris Coyle
I found the "CD-Writing with an ATAPI CDR Mini-HOWTO" (http://www.linuxgazette.com/issue57/stoddard.html) very helpful. Thank you.
Here are a couple of suggestions which other readers who are interested in the same subject may find useful.
- (very minor) I think it should be /etc/modules.conf not /etc/conf.modules
- I just discovered that the ide-scsi module in kernel 2.2.17 (from RH rpms I just DL'ed), either has a big problem, or else it is significantly incompatible with previous kernels.
Here's what happened:
I DL'ed and installed the RH rpms for kernel 2.2.17-14. These were recommended in a security advisory. I kept my previous kernel (2.2.16) installed just in case, adding a new section to /etc/lilo.conf by copying the previous one, mutatis mutandis. Then I ran lilo and rebooted. At first everything appeared to be OK with the new kernel, but then I tried to mount my cd-rom and it failed, giving the message
mount: wrong fs type, bad option, bad superblock on /dev/cdrom or too many mounted filesystems
While I was searching for the cause of this I remembered that I had set up my cd-recorder to use ide-scsi.
My regular cd-rom reader is hdc and the cd-recorder is hdd. Following the directions in your mini-howto, I had inserted
append="hdd=ide-scsi"
and this I had copied faithfully into the new 2.2.17 section. When I removed it and rebooted, I found I could mount the cd-rom again. Then I put the line back in and rebooted.
This time I looked at what scsi devices were detected. Eureka! By looking at dmesg and also by using "cdrecord -scanbus" I discovered that the ide-scsi module had taken over both hdc and hdd, even though I requested only hdd. I asked for help on comp.os.linux.misc and within hours someone else confirmed the same thing, namely
"...if you have two devices on an IDE channel, and one of them is under ide-scsi emulation, it's better to treat both of them as if they were under ide-scsi emulation.
I don't know if this is due to a an error or a design change, but the work-around was quite straightforward.
The only tricky bit was that I wanted to be able to boot 2.2.16 so I had to devise a way to make both kernels boot up in a state where they could use the same devices and configuration files. My solution is as follows:
- Change the lines in /etc/lilo.conf to
append="hdc=ide-scsi hdd=ide-scsi"in both kernel sections.- Move the /dev/cdrom link from hdc to scd0.
- Change the scsi configuration for the cd-recorder in /etc/cdrecord.conf to 0,1,0 (since it is now the second scsi host).
After all that I am finally back to the point where I can mount the cd-rom and use the cd-recorder, with either 2.2.16 or 2.2.17 kernel.
Reading the logsFrom Andrew
Answered By Heather Stern
Hello Mr Answer Guy,
While i'm here i'm going to get my 2
cents worth &, so throw a few questions at you ( hehe that's funny since
you offer your knowledge for nicks). I'll get in now before you decide
to go commercial
![]() ..
..
![]() Running Redhat 6.1
1./ 1st thing is as soon as i decide to start logging Kernel logs
to /var/log/kernel via syslog.conf i get the following
Running Redhat 6.1
1./ 1st thing is as soon as i decide to start logging Kernel logs
to /var/log/kernel via syslog.conf i get the following
Mar 28 14:20:12 echelon kernel: klogd 1.3-3, log source = /proc/kmsg started. Mar 28 14:20:12 echelon kernel: Inspecting /boot/System.map-2.2.12-20 Mar 28 14:20:12 echelon kernel: Loaded 6865 symbols from /boot/System.map-2.2.12-20. Mar 28 14:20:12 echelon kernel: Symbols match kernel version 2.2.12. Mar 28 14:20:12 echelon kernel: Loaded 168 symbols from 12 modules.
(What does this mean???)
Removable media bays have either optical or mechanical sensors to detect that new media has arrived ... enough dust particles can screw up either one.
![]() I have included my syslog.conf . Do you have any idea how i can stop this
ocurring?? I thought it had something to do with having multiple things
pointing to the same place
I have included my syslog.conf . Do you have any idea how i can stop this
ocurring?? I thought it had something to do with having multiple things
pointing to the same place
But I'd do a shutdown and try a clean air cannister anyway, it doesn't hurt. Don't forget to cover your mouth, there are usually a lot more dust bunnies than I expect when I do this.
![]() 2./ Should I be concerned with this . I get it continually in my logs
2./ Should I be concerned with this . I get it continually in my logs
Mar 28 12:01:02 echelon sendmail[25388]: f2S212W25388: forward /home/Users/andrew/.forward.eziekiel: World writable directory Mar 28 12:01:02 echelon sendmail[25388]: f2S212W25388: forward /home/Users/andrew/.forward: World writable directory
I mean obviously if i am to receive mail this would need to be writable from ,as it says the world. I am right in thinking that aren't I ??
You should either fix your home from being world writable (after all, your other stuff is vulnerable too) or, you can set the DONT_BLAME_SENDMAIL feature in sendmail, and it will stop checking for silly things like these. And your own fault if it breaks wickedly because of weird permissions.
![]() There are so many questions I have when it comes to Linux.
There are so many questions I have when it comes to Linux.
3./ When I shut down X I might see these errors. They don't mean that
much but I would love to know how to fix then . These are found in .xsession-errors
xscreensaver-command: no screensaver is running on display :0.0 Xlib: connection to ":0.0" refused by server Xlib: Client is not authorized to connect to Server xscreensaver: Can't open display: :0 xscreensaver: initial effective uid/gid was root/root (0/0) xscreensaver: running as nobody/nobody (99/99) rm: cannot remove `/root/.gnome//gmc-aoiM8A': No such file or directory subshell.c: couldn't get terminal settings: Inappropriate ioctl for device
rm not being able to remove absent files, that's not a bug, it's just being noisy.
Usually apps that use ioctls recover from ioctl glitches, since ioctls are so "close to the bare metal" they behave differently on a lot of systems.
![]() 4./ When I start a ppp session via ifup ppp0 I get the following
4./ When I start a ppp session via ifup ppp0 I get the following
command not found but then I kicks in anyhow & dials up without problem.
Wish I could fix that strange one
![]() 5./ I think snort is a great program but it still throws some false alarms
I constantly see info I don't need to like the following
5./ I think snort is a great program but it still throws some false alarms
I constantly see info I don't need to like the following
![]() Then the like of this error
Then the like of this error
Mar 27 01:15:20 echelon pam_console[11450]: can't find device or X11 socket to examine for 1.
Can you suggest a book that gets away from the obvious within Linux & helps with questions that aren't as common like the last one for example..
![]() Thankyou
Thankyou
Andrew
Jim Dennis wrote a nice book "Linux System Administration" from New Riders, but it's more an explanation of planning and things to do in being a daily sysadmin, not "how to read syslogs". Mr. Sobell's "Hands On Linux" is good for getting people to swimming level in the Linux icy seas, but again, it's more about doing things, and less about logs reading.
Not that I'm trying to discourgae you! If more sysadmins cared a bit what the messages their logs contain really mean, I think many systems would be healthier. I just don't know a book that's the kind of reference you're thinking of.
![]() Hello Heather,
Hello Heather,
Wow you were right on the money with these kernel errors. I have just added a removable harddrive to this computer so i'll look into the jumper setting..Thanx
The one i'm not to sure about though is the sendmail part. My permisions for lets say my account/user directory is as follows
drwxr-xr-x 28 andrew users 4096 Mar 29 12:52 andrew
What permissions would you suggest here & for my other users ???
Thanks agian
Andrew
The really security conscious person might have one group per user, and reserve use of the group named "users" that contains normal accounts, for things for all the people to use, so that they can avoid world writable directories at all. Unfortunately directories and files can only belong to one group at a time. And it's a little odd to make your home world readable too, but not uncommon, and in a private system, not so much of a big deal.
![]() Hello Heather,
Hello Heather,
Just a quick message to again say thankyou very much for your prompt email reply. Un fortunately my friends & collegues are more windows based so i cant call on to many people for help when Linux hiccups..
Being able to ask people like you these strange types of questions help sooo much
Cheers
Andrew
So many users, So few POP accountsFrom Thomas Nyman
Answered By Mike Orr
![]() I have recently entered the magical world of Linux (Red Hat 7.0). In the
You see I would like to configure my linux machine so
that it polls a couple of pop accounts via a dialup ISP, and the distributes
any mail to users on the local network. In my mind a reasonable request. I
understand that sendmail and fetchmail can be used in this respect (although
sendmail "sends" mail and does not collect it). I have so far been inable to
find out exactly what I need to configure (besides fetchmail) to do this. I
have also tried to configure sendmail to no avail, it keeps complaining that
I have not set a que and have not set a mailbox...but try finding a how-to
that tells you how to setup a que and a mailbox locally - I cant do it. I
have also tried to instal qmail. I've downloaded a tar.gz file. Unpacked it
with gunzip and the run the tar -xvf comman on it. SO fall all looks fine. I
have then followed the install instructions and goes well untill I reach the
part of the install instruktions that instructs me to "make setup check",
many attempts have been made but qmail simply will not understand the
instruction..hence I cant continue the installation....ah but I digress...the
point is I want to collect popmail from different pop accounts and distribute
it to either eudora och outlookexpress on windows machines..can I do
this..and if so whaich programs do I need to configure and how???
I have recently entered the magical world of Linux (Red Hat 7.0). In the
You see I would like to configure my linux machine so
that it polls a couple of pop accounts via a dialup ISP, and the distributes
any mail to users on the local network. In my mind a reasonable request. I
understand that sendmail and fetchmail can be used in this respect (although
sendmail "sends" mail and does not collect it). I have so far been inable to
find out exactly what I need to configure (besides fetchmail) to do this. I
have also tried to configure sendmail to no avail, it keeps complaining that
I have not set a que and have not set a mailbox...but try finding a how-to
that tells you how to setup a que and a mailbox locally - I cant do it. I
have also tried to instal qmail. I've downloaded a tar.gz file. Unpacked it
with gunzip and the run the tar -xvf comman on it. SO fall all looks fine. I
have then followed the install instructions and goes well untill I reach the
part of the install instruktions that instructs me to "make setup check",
many attempts have been made but qmail simply will not understand the
instruction..hence I cant continue the installation....ah but I digress...the
point is I want to collect popmail from different pop accounts and distribute
it to either eudora och outlookexpress on windows machines..can I do
this..and if so whaich programs do I need to configure and how???
The next step is to set up your .fetchmailrc. Assuming all the mail from each pop account is going to a single user, you can use a configuration like this:
poll pop.my-isp.net proto pop3 user bob there with password XXXXX is bobby here poll pop.my-other-isp.net proto pop3 user frederick there with password YYYYY is fritz here
Now, each time fetchmail runs, bobby and fritz will find their pop mail in their Unix mailbox. You would then need to make that mailbox visible to Eudora or Outlook Express somehow, but that's another issue.
If your mail transport agent seems to be working but popped mail is still being lost, use fetchmail's -v flag to determine whether fetchmail is generating the correct recipient address and whether the mail transfer agent is accepting the message.
If you wish to distribute mail from a single pop account to several Unix accounts, it's more complicated. You could have fetchmail deliver it all to a single account which then uses procmail to distribute it (e.g., according to a special prefix in the subject). Or you could use uucp instead of pop/fetchmail. Uucp was designed for the "my site has multiple users but I only have one ISP account" problem, but pop was not. Pop was designed assuming each user would have their own mailbox at the ISP. However, finding an ISP that supports uucp nowadays is difficult, they may want a higher price for it, the configuration would be more complicated, and it would probably work best if you had your own domain.
scriptFrom Paul Wilts
Answered By Ben Okopnik
![]() Hello there, I am hoping you can help me out. I am writing a script. I have
a file that has two columns. one column with numbers and one column with
names. This file stores users disk-usage/user-name ie: 50000 paul. I would
like to run a script/command that would look into the file and if a user is
over a certain number , that number/numbers along with the user/users name
is copied from that file and put into a different file. I have tried almost
everything I know, which is limited, but have not had any success.
Thank you for your help
Hello there, I am hoping you can help me out. I am writing a script. I have
a file that has two columns. one column with numbers and one column with
names. This file stores users disk-usage/user-name ie: 50000 paul. I would
like to run a script/command that would look into the file and if a user is
over a certain number , that number/numbers along with the user/users name
is copied from that file and put into a different file. I have tried almost
everything I know, which is limited, but have not had any success.
Thank you for your help
5 joe 7 jim 12 jack 10 jeff 20 jose 1 jerry 3 jenny 8 jamal 6 jude
and we want only those users whose numbers exceed, say, 7, then we might do something like this:
while read a b; do [ $a -gt 7 ] && echo $a $b; done < quotas
What we've done here is read in each line and load the strings into two variables, $a and $b. We then check to see if $a is greater than our target number, and echo both of them if it is.
Note that the whitespace between the names and the numbers is ignored by 'read'; I only put it in to demonstrate how clever "bash" is about stuff like that.
You could also do it in Perl -
perl -wane 'print if $F[0] > 7' quotas
- split each line into an array, print if the 1st member of the array (arrays are indexed starting from 0) is greater than the target.
That should save lots of wear and tear on your fingers.
![]() Thanks very much for your help. Yes I was using Bash. I tried using the test
and expr. What would you suggest for a good web site that would also be a
good reference for information on scripts. Once again thanks.
Thanks very much for your help. Yes I was using Bash. I tried using the test
and expr. What would you suggest for a good web site that would also be a
good reference for information on scripts. Once again thanks.
A while ago, I wrote a 6-part series right here in Linux Gazette called "Introduction to Shell Scripting". It's been translated into 7 languages, and is used in at least two college courses. It was intended as a basic text - don't expect to be introduced into The Deepest Mysteries - but I believe that it's a very good start for anyone trying to learn shell scripting, and should get you up to basic competence in short order.
Take a look at LG issues 52-55 and 57-58 or <a href="http://www.linuxgazette.com/search.html">search for my last name (Okopnik)</a>, since one of the articles got misnamed in the e-mail shuffle.
Linux Box on windowsFrom Uri Rado
Answered By Heather Stern, Breen Mullins
How can I install a linux windows on windows?????
Thanks!!!!!!!!
Uri Rado.
- "a linux windows"
The usual graphical system for Linux is called the X Window System (no plural) or often, just X. The usual flavor of that we use is "Xfree86"... even if we're on Alphas and some other hardware, but since you're using Windows(tm) you're pretty likely to be using 80x86 compatible stuff.The part that makes it look impressive is called a "window manager" and many of them, even the really plain ones, support themes, though not the same theme files from Windows without a little help.- "on windows"
- a linux windows "inside" windows ... to run like a windows app?
One possible way is to use VMware for Windows, and install Linux into the child volume that it would create for you. This can be a little tricky to setup, but may not be too bad, and allows you to run Windows and Linux things at the same time. Yes, we here in The Answer Gang are more likely to do it the other way, running Windows inside of Linux, but it's your choice to make, not ours- a linux windows "inside" a windows partition, but to boot into from windows.
There are several distributions (many of them describe themselves as a "loopback loading" linux) whose install does not repartition your drive, just uses up a bunch of space inside of your C: ... I have little experience with them personally so I can't tell which one is the best. (PhatLinux got a lot of attention at one point :D) All I can say is that Linux Weekly News' "Distributions" section (http://www.lwn.net) has the best listing, and you'll want to look at several web pages before picking one, if this is what you wanted.- I'm using windows, how do I install linux without wiping my windows?
Many of the commercial distros promise to do this, and they have varying degrees of success... the most frightening part is the part about resizing your drive space so Linux can use the rest.Don't feel bad, it's frightening to us old hands too - and it should be. There was never a better time to make a backup!Partition Magic is reeeeally popular for doing that, in fact, so popular that it is what a couple of the big Linux distros use. But, I have heard of a few rare cases where it didn't do things right - and if you have Windows ME you desperately, importantly, don't-take-maybe-for-an-answer, need to use the newest version, or it won't work.FIPS used to be the handiest, but it's a DOS app. It's also quite old and unmaintained. Basically if you have a new enough version of Windows that you're not sure how to boot from a floppy into a DOS prompt... or that you *can't* ... you shouldn't use FIPS anymore. Its docs are still valuable reading though.GNU Parted is the current good tool to use if you come up in Linux. I'm not sure if it's seen any problems with those WinME partitions or not, but it is being actively developed, at least...The most careful way is to do your own defragging and backups, use any one of probably several available tools to cut your C: into a C: and D:, and then, start your selected Linux distro installer. The space assigned to be your D: can safely be chopped up into parts for Linux (for ordinary flavors of Linux) or used as the resting place for Linux parts (for distros which use UMSDOS, live in FAT filesystems directly, or use "loopback loading".)If you have an IDE drive your C: will almost certainly be /dev/hda1 when mentioned in the Linux tools, and should be left alone and absolutely NOT formatted during your installation of Linux. (For SCSI systems, /dev/sda1.)- I just want to make my windows box look like Linux so my nerdy friend will stop bugging me
(Hey, it's april coming up, isn't it?
- Maybe a student's project "icoutils" could help you out here:
- http://www.student.lu.se/~nbi98oli/src/icoutils-0.12.0.tar.gz
You'd have to be a little bit programmer instead of artist though, he says turning images back into .ico's is "not yet implemented". But it was just updated this week, so let's encourage him, okay?Anyways don't forget to use Windows' features to make the icons 48x48 size and not to lose pixels by getting stuck with 32x32 "old style" .ico or it won't look very linux-y...Hopefully, your buds would get the hint that by applying apropos Windows tricks, that you are nerdy enough in your own right, in the environment you prefer.
[about adding Linux to an existing Windows install]
Make very very sure that you're using the latest version of whatever tool you're using if you've got WinME anywhere near your box.
![]() Thanks!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Thanks!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Uri Rado.
Take a Breath!From Wolf
Answered By Jim Dennis, Heather Stern
Answer Guy,
I just recently read that message from Rik, having trouble with some bad clusters under Windows. Anyway, I used to run a Win98 system, and I experienced the same problems, even if they might not be related to Rik's (just bad hardware or mis-partitioning, I assume). I had my HD partitioned into one primary and one extended partition, with approximately 20 gig each (HD is a Samsung 40.8 gig). Then, I used Partition Commander to make 4 out of the primary partition: One FAT32 (14 gig), and 3 FAT16 (2 gig each); and on the extended partition I put a 12 gig FAT32 and 8 gig for Linux, pre-formatted with Partition Commander. Now I know, that Linux doesn't like anything above 1024 cyl., but I always assumed, that it's translated in such a way, that only 1024 are reported (or am I wrong?). Installing Linux on that last partition was a bold failure. First, I never got it to boot from the HD, no matter if I used Loadlin or (tried) LILO, in the MBR or on the partition. When it booted after the CD install, fsck found a load of errors, and they all seemed to be beyond 32 gig. So I deleted the last partition and reformatted it as FAT32, which seemed to succeed without errors; even with bad clusters checking on. Letting a disk utility have it's way with it later, revealed again a bunch of bad clusters, and again. above the 32 gig limit. Not sure, if that's an OS or a hard error? Right now, I'm going to low-level format and re-partition the drive, then assign Linux all the space (this version doesn't like partitions picked from the middle of the drive). Hopefully it boots. Or the HD craps out altogether, there's still warranty on it... Had anyone reporting similar stuff with a big HD like mine is? Windoze is good for all kind of surprising crap, but I need it for development...
Thx,
To give the short form of the answer -- it's not an OS error at all. Bootloaders come before the OS, whether DOS or Linux. It's a dependency on firmware features - the BIOS on your system either does, or doesn't, have 1024 cylinder problems. If your BIOS doesn't have the boundary, the bootloader still has to make different calls to ask about later areas of the disk, because this is a newer feature, and is tacked on to the BIOS design.
I can just about guarantee that the final 8 Gb on a 40 Gb drive would be above that boundary!
LILO has an old keyword to beat this boundary (linear) and a new way (LBA) but this drive is so large you may need an even more special call (LBA32). Linear basically asks for cylinder/head/sector stuff. The LBA flavors tell LILO to make the new BIOS calls.
You mentioned the drive but not the motherboard - assuming it's modern enough, I'd try the LBA32 keyword in /etc/lilo.conf. (On a line alone.) If that doesn't work I'd probably use Loadlin, throw an icon for its correct command line on my desktop (looking like Tux of course) and forget worrying about it. Just remember to copy your kernel to the right place on your FAT drive that loadlin expects, whenever you decide to update your kernel.
Unfortunately, that you're seeing the drive poorly when the 8 Gb are FAT partitioned or ext2 partitioned, implies that I may be wrong about how modern it is. Or, the drive has memorized something poor about how to present itself to us. (Yes, drives have had their own brains for a while, that means they get to be artificially stupid sometimes too.) So, I'd check if your motherboard manufacturer has a BIOS revision, because it may help some. And during low level format I'd be really extra picky about looking through the options, in case something leaps out as meaning "My motherboard is so stupid I can't even see all 40 Gb. Just give me 32 of it. Thanks." Or as we'd say, ack! No thanks!
Linux has no problem at all with anything past the 1024th cylinder. The Linux kernel can handle any commodity drive.
Now over the years that have been several different workarounds to this problem. First we note that SCSI drives have normally not been afflicted with these limitations (since they don't emulate the old WD-1003 controller interface; they have their own BIOS extensions which provide the necessary support through the "INT 13" calls). Also we note that this problem is specific to the PC (so it's never been a problem on Macs, SPARCs or the many other platforms that Linux supports).
Also most IDE drives, though they mostly emulate the ST-506 interface, mostly as implemented by Western Digital's old 1003 chipset; they will perform their own "autotranslation" internally translating "virtual head" addresses into larger cylinder numbers. Later these drives dropped all pretense of using cylinder/head/sector (CHS) co-ordinates and used a technique called LBA (linear block addressing). That basically means that any block request it gets (which comes in the form of a cylinder/head/sector triplet) is translated into a single number (multiple the three numbers in the triplet together) and that is fetch according to the drive's own indexing and mapping. BIOS' then started supporting LBA which overcame the 8Gb limit.
Meanwhile the latest versions of LILO support the necessary BIOS call extensions to boot from any cylinder on any IDE drive; so long at the PC BIOS in question also supports the extension.
I've described alternatives to LILO MANY times in our column. Since this is almost always an issue of installing Linux unto a system that already has a copy of MS-DOS (or any of it's ilk, Win '9x, OS/2, etc) then it's usually easiest to configure you system to boot into MS-DOS and to run a program called LOADLIN.EXE to load your Linux kernel. Because MS-DOS is being booted from "the first" partition on the first or second drive (the only supported configuration) and because it has access to the "rest" of the drive (with it's device drivers, and various Microsoft supplied extensions) then LOADLIN can load any kernel that MS-DOS can "see."
Anyway, this issue is old and obsolete. Please reconsider before you repeat this misconception any further. This is not a "Linux" problem. It is a PC problem which has been faced (and addressed) by many Linux users *because Linux doesn't impose arbitrary constraints on how you configure your filesystems*. Linux doesn't make you install it in the first drive or the first partition, etc. Unfortunately with the freedom has common the confusing choices that have caused so many questions among Linux users.
This is the part where I rant about how if we improve the documentation enough at least these can be informed choices.
about the adaptation.From Meltem YAGLI
Answered By Ben Okopnik
![]() Hello,
I am the researh assistant in Eastern Mediterranean University, and i am doing
master in computer engineering department. About the adaptation of linux with
other operating systems, i have a problem. if you can help me, i will be very
happy.
Hello,
I am the researh assistant in Eastern Mediterranean University, and i am doing
master in computer engineering department. About the adaptation of linux with
other operating systems, i have a problem. if you can help me, i will be very
happy.
I have a program that is written in C and my operating system is linux now. This program has been done before on dos operating system, (it includes stdio.h, stdlib.h, conio.h, etc..). so, if i want to run this program, linux can not find conio.h. (there is no such library file in linux) Could you help me for this. i wonder, is there any corresponding�file in linux that can do the functions of conio.h? The only chance is�to include this corresponding file to my program.
/* conio.h
Direct MSDOS console input/output.
Copyright (c) Borland International 1987,1988,1990
All Rights Reserved.
*/
That's why there's none in the standard C 'include's for Linux: it's a DOS-specific library! Now, I've done very little C programming in the last few years - mostly just little quick things - so I haven't had to deal with any fancy console stuff, and no need for anything like "conio.h". If I did, the library that is commonly used in Linux for console I/O is "curses.h". Take a look at libncurses5-dev; you'll have to do a bit of rewriting, since Linux handles console I/O differently from DOS, but it shouldn't be too bad.
Good luck!
Changing the "login-sequence" in Linux?From Alf Kato Brandal
Answered By Ben Okopnik
![]() Hello! We are working on a student-project where we want to get a Perl-script
to log us in to Linux. Do anyone know how we can do this? Please do not just
answer that we need to use the "Expect" module in Perl, cause we don't
understand how we can use this. Is there any other way?
Hello! We are working on a student-project where we want to get a Perl-script
to log us in to Linux. Do anyone know how we can do this? Please do not just
answer that we need to use the "Expect" module in Perl, cause we don't
understand how we can use this. Is there any other way?
Read the "expect" man pages and documentation. It is probably the best tool for what you describe, since it is written for exactly this purpose. Put in a little effort, and you'll get back the result you're looking for.
Linux, X, Dell Video CardFrom Glenn Martyna
Answered By Ben Okopnik, Daniel S. Washko
![]() I have loaded Red Hat Linux 7.0 on my new Dell computer,
(4MB Integrated AGP Video Card,i810 chips set) however, X windows
will not start. I tried loading Xfree's 3.3.6 instead of higher
level of X present in the Red Hat release. Now I get an error
that says "_X11TransSocketUNIXConnext" failure.
I have loaded Red Hat Linux 7.0 on my new Dell computer,
(4MB Integrated AGP Video Card,i810 chips set) however, X windows
will not start. I tried loading Xfree's 3.3.6 instead of higher
level of X present in the Red Hat release. Now I get an error
that says "_X11TransSocketUNIXConnext" failure.
Also, if I remember correctly, there was either no or minimal support for the i810 in 3.3.6, but there was in 4.0. You may want to reinstall, this time with 4.0, and see what happens.
I hope this link works for you, if not, it is the first selection if you do a google search on "intel 810 and linux." The driver works with XFree 3.3.6 and up.
sendmailFrom Kenneth Moad
Answered By Jonathan Markevich, Dan Wilder
![]() I am trying to have sendmail send the contents of a file to an email
address. I want to do this from the command line though.
I am trying to have sendmail send the contents of a file to an email
address. I want to do this from the command line though.
I think the command is something like [sendmail -t <<fff] but that does not seem to be working correctly.
mutt -s "Here's the file" -a ~/procmail.log root@localhost
Most MTAs offer a "sendmail" binary with at least some command line compatibility. I've used Smail, Exim, and Postfix in preference to sendmail these last ten years, and the following works just fine with all of them. Most likely, it also works with Qmail, MMDF, and anything else that attempts to offer some sendmail compatibility.
"sendmail" may not be on your path. Try
which sendmail
and if it doesn't get you anything, use the full pathname. The usual location these days is /usr/sbin/sendmail. On older systems try /usr/lib/sendmail. If that doesn't work, try "locate sendmail".
To use "sendmail -t" you put the headers in the source document, with no intervening blank lines, then an empty line, then your email text. For example (drop the indents in the real thing):
From: me@someplace.com To: nobody@noplace.you.know.com Subject: email test This is a test. If this was a real email you would have been asked to read it. This is only a test
The "<<" construct you mention is a so-called "here" document. The above example, in the context of such, would look like (again, delete any indents or ">" quoting):
/usr/sbin/sendmail -t <<fff From: me@someplace.com To: nobody@noplace.you.know.com Subject: email test This is a test. If this was a real email you would have been asked to read it. This is only a test. fff
This can be very handy for scripts, as the shell expands shell variables that may appear inline. So:
WHAT="small armadillo"
/usr/sbin/sendmail -t <<fff
From: me@someplace.com
To: nobody@noplace.you.know.com
Subject: email ${WHAT}
This is a ${WHAT}. If this was a real email you would
have been asked to read it. This is only a ${WHAT}.
fff
will expand what was previously "test" as "small armadillo".
To use the contents of a separate file, say, a file called "fff", use
/usr/sbin/sendmail -t <fff
note the single "<". The contents of the file need to be the same as in the "here" document, no blank lines before the end of the headers, headers including at least "From: ", "To: ", and "Subject: ", then an empty line, then the body of the email.
![]() Thank you very much for the help! I decided I will use the "<" instead
of the "<<" in my script thanks to your email. You also gave me a couple
of other ideas too.
Thank you very much for the help! I decided I will use the "<" instead
of the "<<" in my script thanks to your email. You also gave me a couple
of other ideas too.
shade
about a stubborn mount errorFrom Gabriel Florit
Answered By Heather Stern
Dear Linux Gazette,
I come to you hoping that I might finally solve this problem. I have
extensively searched newsletters and IRC sessions, but nothing. Most
users give up after an hour or so, telling me they have no clue. I hope
you do...
![]()
![]() I am running RH7. I have two hard drives, a 10G and a 40G. The 10G is
the master one, no partitions, and it is where i have my win98 system.
The 40G is divided into four, where I have a swap, two linux natives, and
a dos partition, as storage for the win98 system. Now, when I am in Win,
I see both C (the 10G) and D(the dos partition of the 40G). But when I am
in linux, i only see hda1, that is, the 10G drive. sfdisk -l tells me that
the dos partition in the 40G drive is hdb7, but when i try to mount it
using
I am running RH7. I have two hard drives, a 10G and a 40G. The 10G is
the master one, no partitions, and it is where i have my win98 system.
The 40G is divided into four, where I have a swap, two linux natives, and
a dos partition, as storage for the win98 system. Now, when I am in Win,
I see both C (the 10G) and D(the dos partition of the 40G). But when I am
in linux, i only see hda1, that is, the 10G drive. sfdisk -l tells me that
the dos partition in the 40G drive is hdb7, but when i try to mount it
using
mount -t vfat /dev/hdb7 /mnt/win
or
mount -t msdos /dve/hdb7 /mnt/win
i get an error that says
mount: wrong fs type, bad option, bad superblock on /dev/hdb7,
or too many mounted file systems
You're certainly able to see the rest of /dev/hdbN, otherwise, your complaint would be about Windows making Linux not work.
Wrong fs type:
There are numerous partition types usable by Windows these days. You mention that sfdisk -l says /dev/hdb7 is your dos partition, but not which type that it is.
I've been hearing that WindowsME has slightly tweaked their partition type; this gave both Partition Magic and parted fits. So... while in most cases we here at the Gang wouldn't care... which flavor of Windows do you have, and do you have any Security updates or service packs? How did you make the D: drive?
Anyways I assume that you have the msdos and vfat filesystem support properly installed since you say that getting /dev/hda1 mounted isn't a problem. So my first guess would be that /dev/hda1 and /dev/hdb7 are different flavors of DOS partition.
Bad option:
Your command lines looked okay to me. Assuming /mnt/win exists.
Bad superblock on /dev/hdb7:
Well, I suppose there might be something subtle that really is wrong with your D: and Linux is just being extra super duper cautious. So perhaps you have run the Windows disk checker with all the "yes check everything thoroughly" options turned on. (As opposed to their normal mode, where they skip time consuming things like looking for bad spots on the drive.)
just curious, does /dev/hdb7 straddle the 1024 cylinder boundary? I've never heard of mount caring about that, but, it is in the middle of a huge drive, so...
![]() I have created the win dir in the mnt dir. (lots of people seem to ask me
that).
I have created the win dir in the mnt dir. (lots of people seem to ask me
that).
![]() I up2dated everything but the kernel, as suggested.
I up2dated everything but the kernel, as suggested.
![]() Still nothing. The odd thing is that I can access the hdb7 from windows.
I can even write to it. But in Linux, RH7 using GNOME, I can't.
Still nothing. The odd thing is that I can access the hdb7 from windows.
I can even write to it. But in Linux, RH7 using GNOME, I can't.
If you come up in "linux single" (by typing that at your boot: prompt) you should be in the same state that the mounting mechanism from /etc/fstab is in when doing its original mounts.
![]() I have asked many different linux users. None can help me. Hope you have an
idea of what's going on.
I have asked many different linux users. None can help me. Hope you have an
idea of what's going on.
Hmm, here's an idea, if you have spare space on one of your other partitions equal or greater than the complaining partition, you can make a binary copy of it to a file:
dd if=/dev/hdb7 of=/usr/local/bigspace/D-driving-me-crazy
Yes, this will take a while. Might want to add bs=1024 or even bs=4096 on the end so it will grab things in chunks. I think that should work even if the partition image isn't an exact multiple of the blocksize... but one of the Gang who plays more with dd than I do should comment on that.
Then, you can ask file if it looks like what you think it is:
file /usr/local/bigspace/D-driving-me-crazy
And if it agrees that it's a filesystem image, then try to loopback mount the file:
mount -o loop -t vfat /usr/local/bigspace/D-driving-me-crazy
...which is not a good solution to your problem, but would pinpoint that mount can, or cannot, mount this flavor of DOS partition. If it can't, then factors to consider are its size, and what type it really is; having got this far it probably wouldn't be a cylinder problem, since the image is at a new location.
![]() Regards,
Regards,
Gabriel Florit
![]() Dear Linux Gazette,
Dear Linux Gazette,
or The Gang,
Thanks very much for your prompt response! I will follow your advice and let you know as soon as possible.
Cheers,
Gabriel Florit
(the guy with the mount problem)
How do I choose?From Serge Wargnies
Answered By Heather Stern
Hi,
I may confess that I am coming from another platform and wants to migrate to the open world ...
My question which distribution choosing ... I am lost between caldera, redhat and other SuSe ...?
We have had this question fairly recently and discussed it in some detail. Basically, you need to know what kind of things you want to use your Linux for, and what things various distros are aiming to be -- then, you can pick one that is trying to head your direction, and you have a much better chance of picking usefully.
The Gang expounded on this in Issue 60, "Best Linux Distro for a Newbie...?" (http://www.linuxgazette.com/issue60/lg_answer60.html#tag/4) and I hope you'll find that answer useful too. If these aren't quite enough, let us know what you're thinking of, and we'll try to help out a bit more.
![]() Thanks very much in advance...
Regards
Serge Wargnies
Thanks very much in advance...
Regards
Serge Wargnies
![]() Thank for you answer, I read the Gazette but I am still a bit confused so
...
Thank for you answer, I read the Gazette but I am still a bit confused so
...
![]() I am coming from the Windows world, started as a developer on Windows 2, 3,
3.1, 9X and NT/2000. I also did a lot on the system side as well as acquired
a certain knowledge on Databases ...
I am coming from the Windows world, started as a developer on Windows 2, 3,
3.1, 9X and NT/2000. I also did a lot on the system side as well as acquired
a certain knowledge on Databases ...
As you mentioned, it depends what you want to do with it. I don't search for a new graphical environment, I look for acquiring some new knowledge on a growing system that - if I am not that wrong - is quite close to UNIX. Because as my experience should tell that I am not too much into console mode only, I want something with a GUI which is not available on my home PC at this time...or I am wrong...???
If those are close enough to a usable GUI for you then you can probably do okay with most of the nicer distributions, and the next concern would be making sure that you have a decently safe bet on a clean install, followed by an interest in good access to developer tools.
If that's too different from the GUI you enjoy, there's a Window Manager named fvwm95 that's designed, as you might guess, to be a really close match. That means the task bar acts the same, for example. There will still be slight differences.
Once you start to get used to a few applications, you can play with loading a few other Window Managers and see if you like some of the others; many have interesting extra features.
![]() I plan to learn about the environment but once it is installed, I don't want
to spend 10 weeks - I am not often at home - to have the PC installed...This
has to be done in one shot. I will learn from the system after...as well as
starting to do some development - porting application from Windows to
LINUX/UNIX ....
I plan to learn about the environment but once it is installed, I don't want
to spend 10 weeks - I am not often at home - to have the PC installed...This
has to be done in one shot. I will learn from the system after...as well as
starting to do some development - porting application from Windows to
LINUX/UNIX ....
...and if having to run an occasional, but possibly well behaved Windows binary on your Linux is interesting, you'll also want to keep an eye on the WINE project (http://www.winehq.com) which is trying to provide a support layer for win32 binaries to be run directly within Linux and a few other OS'.
![]() So what can I do, doctor?
So what can I do, doctor?
Serge Wargnies
Most packages available out there are available in at least one of 4 states: source tarballs (you get to build it yourself; if you're lucky that's only 3 commands, not very hard, and listed in the README or INSTALL textfile for the package), Redhat style rpm files, rpm files for non-redhat derivitive systems (like SuSE or TurboLinux), and Debian packages. Mandrake and some other Redhat derivitives can share Redhat style rpms. Stormix, CorelLinux, Libranet, Progeny, and Debian itself all can share deb files.
If you decide that a debian based system works for you, then I'd definitely choose either Libranet or Corel, instead of "the real debian" installer, because in your case, you're not a Linux expert; even though the Debian installer is ok, the boost in helpfulness that these commercial distros provide during the install would be extremely worthwhile for you.
If you're afraid of repartitioning but still want an fairly easy install of a "big name" Linux distro, consider BigSlack... the version of ZipSlack (http://www.slackware.com/zipslack) that includes X and Gnome, but can be installed directly into a FAT filesystem just using PKunzip. Slackware has been around a long time and is well known as being friendly for people who like to work directly with source code.
If you decide that because there are lots of Redhat-style packages out there, you need a redhat compatible system, I guess Mandrake would be worth a try. Make sure to get a really recent version or buy it direct tho, because they had some bugs during install that they fixed recently, and you wouldn't want to get nailed by one just because the local store had a dusty copy.
I notice you're not in the U.S. so if English isn't your native language, maybe there's a localized variant that would be handy for you. Linux Weekly News lists a whole bunch of them (http://www.lwn.net) in its Distributions sidebar. Some of the major distros support many languages too.
Backing up the system in its current state is a good idea, not so much because of the risk (well, yes, there's some, not horridly bad) but because now is a good time to decide what's important and not on your machine; it will be good to have if there's any sort of trouble, not just linux install issues. For example, a power outage right when you've almost got things humming :(
Let us know if you need more!
![]() Thanks very much fir the answer, I guess you have summarized the situation
pretty well ...
Thanks very much fir the answer, I guess you have summarized the situation
pretty well ...
I will follow the links...
Regards
Serge Wargnies
I was wonderingFrom andrew
Answered By Mike Orr
i see a number of suspicious files in my proc directory.For example there is a directory that is called 6 & when i look in this folder i see i number of files eg
[root@echelon 6]# ls -la ls: exe: Permission denied ls: root: Permission denied ls: cwd: Permission denied total 0 dr-xr-xr-x 3 root root 0 Mar 26 14:28 . dr-xr-xr-x 89 root root 0 Mar 26 07:32 .. -r--r--r-- 1 root root 0 Mar 26 14:29 cmdline lrwx------ 1 root root 0 Mar 26 14:29 cwd -r-------- 1 root root 0 Mar 26 14:29 environ lrwx------ 1 root root 0 Mar 26 14:29 exe dr-x------ 2 root root 0 Mar 26 14:29 fd pr--r--r-- 1 root root 0 Mar 26 14:29 maps -rw------- 1 root root 0 Mar 26 14:29 mem lrwx------ 1 root root 0 Mar 26 14:29 root -r--r--r-- 1 root root 0 Mar 26 14:29 stat -r--r--r-- 1 root root 0 Mar 26 14:29 statm -r--r--r-- 1 root root 0 Mar 26 14:29 status
![]() Notice the permission denied on those 3 files. Why is this if i am root??.
Notice the permission denied on those 3 files. Why is this if i am root??.
![]() I
cant delete them or change anything about them. What would you suggest?? I
mean they are links to other files so why can i just unlink them.
I
cant delete them or change anything about them. What would you suggest?? I
mean they are links to other files so why can i just unlink them.
To see for yourself that nothing funny is going on, run "umount /proc" as root. (If you get a "Device Busy" error, it probably means some process has its current directory inside /proc. You cannot unmount a filesystem if somebody's current directory is inside it.) The /proc directory should be empty now. Run "mount /proc" or "mount -t proc proc /proc" and the "files" should reappear.
![]() Also as a side note do you have any idea that when im in shell within this
directory that those 3 files are flashing??
Also as a side note do you have any idea that when im in shell within this
directory that those 3 files are flashing??
More observations of a cardboard boxFrom Randjbarnhart
Answered By Heather Stern
![]() Maybe the lady who asked about the cardboard box is a spanish teacher. I
recently got a version of Don Quixote that talks about him fixing up old
knight accessories with cardboard. Since Cervantes wrote the book in the
1500's, I was wondering when cardboard was first used. I know that when my
students read this, someone is going to ask about it. Maybe the word
"carton" meant a thin type of board used for crates or something. The
footnote says cardboard but it has to be wrong --don't you think so? Anyway,
sorry for boring you. Just wanted to express empathy for the cardboard box
lady.
Maybe the lady who asked about the cardboard box is a spanish teacher. I
recently got a version of Don Quixote that talks about him fixing up old
knight accessories with cardboard. Since Cervantes wrote the book in the
1500's, I was wondering when cardboard was first used. I know that when my
students read this, someone is going to ask about it. Maybe the word
"carton" meant a thin type of board used for crates or something. The
footnote says cardboard but it has to be wrong --don't you think so? Anyway,
sorry for boring you. Just wanted to express empathy for the cardboard box
lady.
Our only previous mention of cardboard before that had been to describe that chroot (while imperfect) was better than someone's attempt to keep his users safely trapped in their home directories.
- There's a more complete history of packaging than we found last time at:
- http://www.ag.ohio-state.edu/~ohioline/cd-fact/0133.html



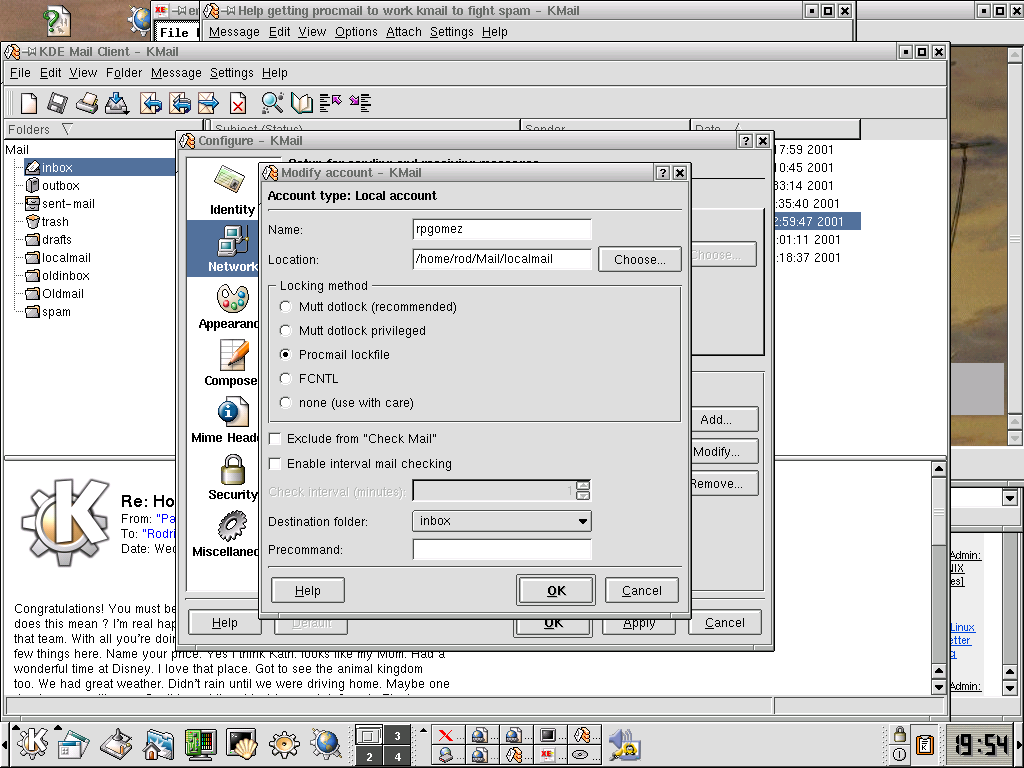{kind=link}