June 2003, Issue 91 Published by Linux Journal
Front Page | Back Issues | FAQ | MirrorsThe Answer Gang knowledge base (your Linux questions here!)
Search (www.linuxgazette.com)

Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/
,
http://www.linuxgazette.com/
|
...making Linux just a little more fun! |
From The Readers of Linux Gazette |
 compressed tape backups
compressed tape backupsHi TAG's,
quite a while back I remember a discussion on compressed tar archives on tape and the security risk, i.e. the data would be unrecoverable behind the first damaged bit.
Now at that time I knew that bzip2, unlike gzip, is internally a blocking algorithm and it should be possible to recover all undamaged blocks after the damaged one.
Test RESULTS:
tar archive of 90MB mails, various size, mostly small
tar -cvjf ARCHIVE.tar.bz2
bvi to damage the file at about 1/3 (just changing a few bytes)
tar -xvjf ARCHIVE.tar.bz2
produces an error and refuses to continue after the damage. --ignore-failed-read doesn't help at all, neither -i
running bzip2recover produces a set of files rec00xxFILE.tar.bz2 decompressing them individually and cat all good ones into tar:
tar produces an error where the data are suddenly missing, skipping to next file header, but it's not recovering anything beyond the error. It seems it's unable to locate the next file header and simply skips through the remaining file. I also tried to run tar on the decompressed blocks after the error only -- same result: It's skipping till next file header, doesn't find one and ends with an error.
In my tar "tar (GNU tar) 1.13.18" I discovered the following option (man page):
--block-compress
this option is non-existent in "tar --help" and running:
tar -cvzf ARCHIVE.tar.gz --block-copmress
says:
tar: Obsolete option, now implied by --blocking-factor
Writing archives with --block-copmress and/or --blocking-factor 2[0] does not improve things very much. several times with gzip and a blcoking of 2, i.e. 1kB), I was lucky and the error was in one large mail (attachement). In that case tar was able to locate the next file header and I lost only the one damaged mail. I introduced some more damaged blocks and suddenly tar was skimming through the remaining tar-file again without recovering any more files.
Fazit:
- seems still to be highly risky to use compression on tapes archives
- blocking improves chances -> use a very small blocksize.
One question remains: Can some flag improve the tar behaviour in locating the next file header? I couldn't find one in either tar --help nor the man page.
I also start wondering what tar says to several unreadable tape blocks and how it's going to locate the next file headers after that.
I'm ordering the head cleaning tape I think....
K.-H.
Daemon vs CGI spawning processesDear all,
recently, I switched from using CGI to run a program to using the SOAP-Lite 0.55 XML-RPC Daemon to run the same program.
The only noticeable difference between using the two, is that using CGI, the web page reloaded straight away, but with the new daemon, the web page waits for the program to finish before reloading.
I have no idea about CGI and perl daemons, so I'm writing to this list to ask about processes. It seems to me that the Httpd daemon (Apache2) will spawn it's own CGI process that handles the program independently, whilst the self-created daemon doesnt.
Im posting the daemon's code below if it helps.
See attached soap-daemon.Seaver.pl.txt
Compiling qt 3 libI'm wondering if someone might have an idea about what's going wrong with my effort to compile ver 3 of the qt lib. I DL'd the source and unpacked to a dir under my user normal user's home dir, and ran configure with a few options specified. It completed normally w/o error. But when I run make from the same dir, it errors out immediately:
Insp8000:~/Builds/qt-x11-free-3.1.2 > make make[1]: Entering directory `/home/jkarns/Builds/qt-x11-free-3.1.2' cd qmake && make /bin/sh: cd: qmake: No such file or directory make[1]: *** [src-qmake] Error 1
I should mention that I didn't intend to address the question so much toward qt explicitly, but rather I'm wondering if the problem might be due to peculariarities of gmake, or some other system configuration issue - I guess I'll look into updating gmake on this machine. I've run into similar problems when compiling other pkgs, although most pkgs compile w/o a problem.
VP and net load equationHello,
Is it possible in a VPN based network. To get distribution of Net load on the side of the Linux servers so that each Client get (the client conect thru a VPN Tunnel through a Wierless Network) the same speed in the Internetconection
Best regard
Bernhard Schneider
Linux Gazette entry in WikipediaI've added a stubby entry to Wikipedia (http://www.wikipedia.org/wiki/Linux_Gazette). Anyone care to expand on it?
[Jason] Hmmm....are you sure the wikipedia folks like that sort of thing?
http://www.wikipedia.org/wiki/Wikipedia_is_not_a_dictionary
Yeah, I think it's OK. I've gone more for encyclopaedic information than a mere definition, even if it is a stub. Starting a stub is encouraged - an extreme version of how a stub can grow from a definition (from FOLDOC) is here http://www.wikipedia.org/w/wiki.phtml?title=PS/2&action=history - in the space of one hour it changed completely, and grew to about 4 times the original size.
Anyway, I cite precedence http://www.wikipedia.org/wiki/Macworld
Home Network Internet Connection SharingHi,
Thanks for you generous help. You must be very good-hearted people.
[Thomas] Yes, we are
[Ben] Thank you for the compliment, doctor. We're all here for a number of reasons, but I have to agree with you to this extent: everyone who has stayed with The Gang over the long term has earned my respect for their demonstrated willingness to give their time to this endeavor. If you believe, as I do, that Linux is improving the world by reducing the amount of chaos in the world of computers, then all of us have contributed to making this world a better place.
I think I have identified an area of need: I have used RHL for years, and am now getting a few machines around the place for different uses including software and hardware testing. I'd like to set up a network at home, which I am finding very difficult because my USB port has taken over my eth0 and the configuration tools won't let me save anything...
[Ben] Could you clarify that, please? eth0 is an Ethernet network interface; USB is a completely separate physical entity that, as far as I know, shares almost nothing with it. I would suggest that you carefully read "Asking Questions of The Answer Gang" at
<http://www.linuxgazette.com/tag/ask-the-gang.html>;
particularly the part about "Provide enough, but not too much information". Simon Tatham's page, linked there, is a really good guide to effective bug reporting and following it will benefit you when asking questions in technical fora.
[Thomas] How do you mean "taken-over"? Indeed, USB and "eth0" (which I'm transliterating to meaning your NIC (Network Interface Card) should be two separate issues (that is unless your NIC is USB based, which is obsured.....).
But the real area of need I think is sharing an internet connection. In Australia we have cable modems and ASDL as well as dial up modems, and I noticed Mandrake just has a button for this! RHL is much more terse.
[Thomas] Tut, tut -- what you are describing here is a difference in the GUI configurations of the two different distributions, essentially the underlying information about each network IP, interface, etc, is stored in the same configuration files in "/etc"
[Ben] Linux is based on understanding the underlying mechanisms rather than just "pushing the button" - whatever buttons may exist in specific distros. The process of sharing a net connection is not a difficult one, and is domented in the Masquerading-Simple-HOWTO, available at the Linux Documentation Project <http://www.tldp.org/>;. Read it and understand it, and you'll find that sharing a Net connection is very easy indeed.
I'll copy this to RHL, too, so they know the difficulties I'm having.
[Thomas] I wouldn't bother -- RH are most likely not concerned with helping you setup your network.
On the contrary, if changing something minimal about their installer would win them a few people more from one of the other distros, they might be inclined to make that easier. Also, if they never hear complaints they have to assume it's all good, right? -- Heather
It is hard to find authoritative info about this.
Thank you again,
Julian
[Ben] Not really. The Answer Gang's Knowledge Base containg this information; searches of the Net (I use Google but any search engine will find this) will come up with hundreds of thousands of hits. The trick is to search for knowledge on the topic rather than a button to push.
[Thomas] Your question is extremely loose -- what exactly do you want, what type of network? I only use PLIP, but that is only because I don't have any NIC's at the moment.... I suspect that this approach in networking is not what you want.
Please take a look through the past issues of the linux gazette - we have a search engine at the main site:
http://www.linuxgazette.com
and especially though the knowledge base (above).
When you can refine your question a little more, please let us know
I read your "How to Create a New Linux Distribution: Why?"This was a TAG thread in issue 39, quite a long time ago. The number of distros has increased drastically, but the need to ask "Why?" before sprouting a new one hasn't changed - in fact, if anything, it's gotten more important than ever... -- Heather
I have a similar idea. However, I don't know if I would go as far as calling it a distribution. All I want is to semi-duplicate an environment I have set up.
I would like to somehow create an installable version of my slackware system. Not a ghost but one where you can alter partitions and select (auto select) nic, MB-features etc, upon installation.
[Thomas] Installable version??? Hmmm, how do you mean? My first ever distribution I used was slackware 2.0, and that was installable. I disgaree with your methods. Tweaking partitions upon installation is perhaps fatalistic, especially if you don't know what you're doing. And in anycase, what is it that you're trying to achieve? I'd have said that most Linux distro's do a damn good job at installing Linux.
I'd be inclined to use a chroot first so that you can test it before you go live. Unfortunately, I don't have enough experience / knowledge to provide you with that. Heather Stern may well pipe up, I know that she does exactly that all the time, using chroot.
Yes - I either set aside a whole partition (for a "one big slash" installation of the given type) or prepare a file and format it as ext2 (for loopback mounting) then only mount the given environment when I need it. Compressed instances of the loopback version can serve as nice backups or baselines for fresh installs on a lab system. I often make a point of leaving bootloader code out of them, though; something I need to back in when preparing those same lab boxen. -- Heather
Do you know a good way to do this or maybe just some pointer on where and how I should get started?
Many thanks if you take the time to answer this.
Best regards - Jon
Ps. Do I need to subscribe to receive the answer? Ds.
[Thomas] Nope, by common courtesy, we always CC the querent (that's you).
Sending people their reply directly, they get it right away, and it's nice that they can see their answer even if their thread doesn't make it into the magazine.
I believ the set of scripts called YARD aims at being something like what you want; visit Freshmeat.Net to look it up. YARD stands for "yet another rescue disc" and is about rescuing the specific system in front of you, instead of just being a general case utility disc like Tom's Rtbt, LNX-BBC, superrescue, etc. -- Heather
[Kapil] You should take a look at mindi which tries to create a distribution out of an existing installation. It runs from a Live CD but can also be installed so that takes care of your "partitioning" issue (perhaps you need "mondo" to actually install your home dirs and so on). To handle hardware detection such as nic,video etc. you must install "discover" or "kudzu" and after that (As far as I can see) you are on your own.
Liunx Gazette in Palm Format
First off I'd like to say that the magazine is excellent, I've only just
come across it. I've been using Linux for around 5 years and there are still
some good hints and tips to be found!. Just a suggestion but any possibility
of a plucker version of your mag? I read alot on my palm and this would be
most useful, I have found that the downloadable HTML version of each mag has
links in the contents page that don't resolve within the document but to
seperate files on the server thus making conversion awkward i.e the contents
page links don't resolve
![]()
James Herbert Senior Software Engineer
[Mike] I assume you mean TWDT.html in each issue. Yes, we can assemble it using a custom TOC page with internal links. It may take a couple months till we get around to it though.
The way it's put together is by merging the fragment articles and columns along some fairly plain "startcut"/"endcut" blocks in the templates ... except for The Answer Gang, where I provide a TWDT edition for the back end.
But to solve his actual problem, he really wants to check out Sitescooper (www.sitescooper.org) and pick up the regularly prepared scoop of the LG issue. I hope they keep 'em up to date. It occurs to me that maybe we should list them on the mirrors page. That's http://scoops.sitescooper.org and it's available in 3 different Palm friendly formats. Plus sitescooper is open source - just download and have fun
[Mike] If there's anything else required to put it into Palm format, send us a HOWTO if there's one available. However, that might work better as a script on your end that downloads the issue (perhaps the FTP file) and converts it to plucker format, whatever that is. Since we have so many versions of the same thing already (web files, FTP tarball, TWDT, TWDT.txt), and only a few readers have Palms.
[Ben] You can use "bibelot" (available on Freshmeat, IIRC); it's a Perl script that converts plaintext into Palm's PDB format. I have a little script that I use for it:
See attached pdbconv.bash.txt
This uses the textfile name (sans extension) for the new file name and the PDB internal title, and does the right thing WRT line wrapping. Converting the TWDT would require a single invocation.
Does the raw PDB format have a size limit? Our issues can get pretty big sometimes... -- Heather
Your web siteHi
I've been an LG reader for 5 years now, and a year (or maybe more) ago you changed the web site. I really preferred the old site. Why?
Hmmmm it's hard to place a finger on it. One definite thing I miss is that I used to love having the really big index, which would show you a huge table of contents, with the table of contents of every issue listed.
[Mike] That is still around, but it's called "site map" now. There's a link on the home page, or bookmark the direct URL:
http://www.linuxgazette.com/lg_index.html
I'm blind and use a screen reader, and I could use my screen reader's search facility to find topics -- if I wanted to know about ncurses, I just search for that, and would hear the latest article which had ncurses in the title. Pressing a single key again and again would take me to all articles with ncurses, for example, in the title. Can this be reintroduced? I know the search feature does something similar, but I still think it makes it harder (for me) to find what I want. That's the main thing I can think of right now, but I'll keep you informed if I thik of the other little things.
But with regards to the content of the magazine - it's excellent, and the archives are a wonderful resource.
Saqib Shaikh
[Thomas] You're quite welcome
|
...making Linux just a little more fun! |
By The Readers of Linux Gazette |
 Reading email headers
Reading email headersHey, all -
A while ago, someone asked me how to read email headers to track a spammer (Karl-Heinz, IIRC.) I kinda blew it off at the time (ISTR being tired and not wanting to write a long explanation - sorry...) Lo and behold, I ran across this thing on the Net - it's an ad site for a piece of Wind0ws software which tracks (and maps the track - sooo cuuute!) the path an email took based on the headers. The explanation there is a rather good one; it's pretty much how I dig into this stuff when I get a hankering to slam a couple of spammers (yum, deep-fried with Sriracha sauce... I know, it wrecks my diet, but they're so nicely crunchy!)
The equivalent Linux tools that you'd use to do what these folks have to write commercial software for are laughably obvious. Anyway - enjoy.
<http://www.visualware.com/training/email.html>
The same company puts out a 'traceroute' program that plots each hop on a world map. Cute. Anyway, a google for:
http://www.google.com/search?q=how+to+read+email+headers
returns a fair amount of articles.
Jason Creighton
Just to make it clear, Ben's talking about some mswin software, and I dunno if he checked that it runs under WINE. But between following Jason's advice, and xtraceroute (http://www.dtek.chalmers.se/~d3august/xt) - our toy for traceroute on a world map - the world of free software should be able to come up with a similar tool. A curious tidbit is that IP addresses whose ranges aren't known to the coordinate system end up at 0,0, the center of Earth's coordinate system... deep underwater in the Atlantic Ocean, near Africa. I wouldn't be too surprised if a lot of spammers live there. Good spear-fishing, fellow penguins. -- Heather
colorful prompt signHi all,
I have seen a colorful prompt sign in RH 9.0 box at a local computer book
shop today. but the operator ( who has recently taken migration from M$ to
Linux ) has told me that she doesn't know how to do this as the shop has
purchased the machine with RH 9.0 preloaded ( & also with that colorful
prompt -
![]() ). so could some one please tell me how to do this ?
). so could some one please tell me how to do this ?
which answers your question above
![]()
About autofs and write permissions for floppyI have just configured /etc/auto.master and /etc/auto.floppy. I can now access the floppy without the need to mount it before. But I don't have write access to it. Only root has write access to my floppy.
here are the files I configured:
/etc/auto.master -
/mnt/cdrom /etc/auto.cdrom --timeout=60 /mnt/floppy /etc/auto.floppy --timeout=30
/etc/auto.floppy -
floppy -users,suid,fstype=vfat,rw :/dev/fd0
Did I something wrong? What did I forget?
Thank you in advance for all information you could provide.
Elias Praciano
[Kapil] The automatically mounted filesystems are mounted by the autofs daemon which runs as root and thus a "user" entry will cause files to be owned by "root".
One solution is to use the "mount" command as the user to mount the floppy.
Another solution is if the floppy is a dos floppy to put "umask=666" as a mount option.
[Thomas] I absolutely hate "autofs". I cannot stand it! How difficult can it be to either type: "mount" or "umount"?? Still, each to their own I suppose
Am I right in assuming that autofs overrides /etc/fstab in some way? Or is it that you specify "autofs" as the filetype within /etc/fstab ? Either way it shouldn't really matter.
To be on the safe side, I would just make sure that the entry for your floppy drive in "/etc/fstab" is genuine
exec rw
are present.
IIRC, "supermount" used to do ...
[Jimmy] Oh no! Supermount is evil! Especially for floppies. supermount tries to figure out when the disk has changed, and mostly fails.
[Thomas] If these suggestions still generate the same problem, please post us a copy of your "/etc/fstab".
Ah....I mentioned it because I vaguely remember John Fisk mentioning it in one of his Weekend Mechanic articles a long time ago.
Personally, I don't see why you don't just issuse:
mount umount
or even better, use "xfmount /dev/abc"
since as soon as you close "xftree", the device is umounted
[Ben] I use a series of scripts (all the same except for the device name) called "fd", "cdr", and "dvd" to mount and unmount these:
See attached dvd.sh.txt
I could probably have one script like this with a bunch of links, and use the name as the device to mount, but I'm too lazy to change something that's worked this well and this long.
Thank you all!
Rahul's solution solved my problem. I added myself to the group 'floppy' and changed the mountpoint group to 'floppy'. Then I changed the file auto.floppy to:
floppy -users,gid=floppy,fstype=vfat,rw,umask=002 :/dev/fd0
It's working fine now!
Thank you again. I learned a lot with you.
Best regards!
linux infraredhi. I'm using the circuit described there and it works great in linux with lirc. Another programs that you will probably find useful are:
lirc-xmms-plugin smartmenu irmix xosd
and to recompile mplayer with lirc support. The circuit cost me ~ 3$ (without the tools that I already had). Hope that I helped. If you need more informations mail-me.
A disabled querent asked about LIRC in general ... -- Heather
[JK Malakar] nice to hear your question on LIRC. yse I have made the home-brew IR receiver which is easy to build as well as cheap also. now I can enjoy MP3, MPlayer, xine etc and even shutdown the machine using my creative infrasuite cd drive remote -
you will get everything at http://www.lirc.org
[Robos] For more infos about how and if you have a question I would say go and ask the source: the lirc page has also a mailing-list where you can surely ask some competent people.
OK, now your question: I have looked at LIRC myself AGES ago and wanted to build that thing too. Didn't do it, mind you (forgot) but I think the hardware and software part were quite well documented. I looked again just now and this here http://www.manoweb.com/alesan/lirc looks really nice and easy. If you think you have problems with homemade stuff try either a TV card (can be had for as little as 50Euros here in Germany), quite a lot of them feature a infrared port already and are quite easy to set up (and you have the benefit of watching and recording TV too
On A Slower ComputerIn reference to Help Wanted #3, Issue 90 -- Heather
On a slower computer...
Now, small distros and distros-on-floppy we have by the dozens. But RH 8 compatible? Or kickstart floppies that chop out a bunch of that memory hogging, CPU slogging stuff? An article on keeping your Linux installers on a diet would be keen. Just in time for Summer, too. -- Heather
Definitely check out the RULE project (http://www.rule-project.org/en). They have installers for Red Hat 7.x and 8.0 for low memory and older processor machines. I have personally used it to install a minimal RH 7.3 system on a P75 with 16MB of RAM. Great stuff!
-- William Hooper
[Thomas Adam, the LG Weekend Mechanic] Indeed, William
I leave out the byplay of one-downmanship as Answer Gang folk chimed in with the older and slower machines of yesteryear which either gave them their start into Linux or still operate as some kind of server today. The winner and new champeen of Lowball Linuxing is Robos, who wondered why his 486/33 notebook with 16 MB RAM was even slower than its usual glacial self - since all but 4 MB of the memory had come a little loose and X had come up anyway. The winning WM for low end systems seems to be FVWM, with a decent place for IceWM, and a surprise showing for E - provided you use a theme on a serious diet. K is not recommended, and we don't exactly recommend Gnome unless it's a quiet and lazy day for you, either... -- Heather
Interesting take on C/C++/etc. by Jon LasserI think C is used as often as it is because it's the lowest common denominator - write a library in C, you can use it from any other language. It won't be the same for any of the scripting languages until Parrot is widespread.
In case anyone's interested, I came across these links --
Linux Journal Weekly News Notes - Tech TipsIt's always inconsiderate to quote more of someone's posting than you have to in a mailing list. Here's how to bind a key in Vim to delete any remaining quoted lines after the cursor:
map . j{!}grep -v ^\>^M}
where . is whatever key you want to bind.
If you want to train a Bayesian spam filter on your mail, don't delete non-spam mail that you're done with. Put it in a "non-spam trash" folder and let the filter train on it. Then, delete only the mail that's been used for training. Do the same thing with spam.
It's especially important to train your filter on mail that it misclassified the first time. Be sure to move spam from your index to your spam folder instead of merely deleting it.
To do the training, edit your crontab with crontab -e and add lines like this:
6 1 * * * /bin/mv -fv $HOME/Maildir/nonspam-trash/new/* $HOME/Maildir/nonspam-t rash/cur/ && /usr/local/bin/mboxtrain.py -d $HOME/.hammiedb -g $HOME/Maildir/no nspam-trash 6 1 * * * /bin/mv -fv $HOME/Maildir/spam/new/* $HOME/Maildir/spam/cur/ && /usr/ local/bin/mboxtrain.py -d $HOME/.hammiedb -s $HOME/Maildir/spam
Finally, you can remove mail in a trash mailbox that the Bayesian filter has already seen:
2 2 * * * grep -rl X-Spambayes-Trained $HOME/Maildir/nonspam-trash | xargs rm - v 2 2 * * * grep -rl X-Spambayes-Trained $HOME/Maildir/spam | xargs rm -v
Look for more information on Spambayes and the math behind spam filtering in the March issue of Linux Journal.
It's easy to see what timeserver your Linux box is using with this command:
ntptrace localhost
But what would happen to the time on your system if that timeserver failed? Use
ntpq -p
to see a chart of all the timeservers with which your NTP daemon is communicating. An * indicates the timeserver you currently are using, and a + indicates a good fall-back connection. You should always have one *, and one or two + entries mean you have a backup timeserver as well.
In bash, you can make the cd command a little smarter by setting the CDPATH environment variable. If you cd to a directory, and there's no directory by that name in the current directory, bash will look for it under the directories in CDPATH. This is great if you have to deal with long directory names, such as those that tend to build up on production web sites. Now, instead of typing
cd /var/www/sites/backhoe/docroot/support
you can add this to your .bash_login
export CDPATH="$CDPATH:/var/www/sites/support/backhoe/docroot"
and type only
cd support
This tip is based on the bash section of Rob Flickenger's Linux Server Hacks.
In order to store persistent preferences in Mozilla, make a separate file called user.js in the same directory under .mozilla as where your prefs.js file lives.
You can make your web experience seem slower or faster by changing the value of the nglayout.initialpaint.delay preference. For example, to have Mozilla start rendering the page as soon as it receives any data, add this line to your user.js file:
user_pref("nglayout.initialpaint.delay", 0);
Depending on the speed of your network connection and the size of the page, this might make Mozilla seem faster.
If you use the Sawfish window manager, you can set window properties for each X program, such as whether it has a title bar, whether it is skipped when you Alt-Tab from window to window and whether it always appears maximized. You even can set the frame style to be different for windows from different hosts.
First, start the program whose window properties you want to customize. Then run the Sawfish configurator, sawfish-ui. In the Sawfish configurator, select Matched Windows and then the Add button.
You can't include web documents across domains with SSI, but with an Apache ProxyPass directive you can do it to map part of one site into another.
You don't need to pipe the output of ps through awk to get the process ID or some other value you want. Use ps --format to select only the needed fields. For example, to print only process IDs, type:
ps --format=%p
To list only the names of every program running on the system, with no duplication, type:
ps ahx --format=%c | sort -u
If you have an ssh-agent running somewhere on your system and want to use it, you can get the SSH_AUTH_SOCK environment variable from one of your processes that does have the agent's information in its environment:
for p in `ps --User=$LOGNAME --format=%p`; do export `strings /proc/22864/environ | grep SSH_AUTH_SOCK` && break; done
This is handy for cron jobs and other processes that start without getting access to ssh-agent in the usual ways.
 Greetings from Heather Stern
Greetings from Heather SternSummer's looking bright and beautiful, the world is alive with free software, and we had oodles of good questions this month...
...many of which were in the LG knowledge base already. I think we had a record number of pointers back to Ben's writeup in Issue 63 about boot records.
...some of which were from students who've put their thinking caps on, and are now asking the kind of considered questions their professors can be proud of. Us too. These kind of students are the ones who will drive computer science into new nooks and crannies that it hasn't spread into yet. (Cue the english muffin with fresh butter. Yum.) May they graduate with high honors and a number of cool project credits under their belt.
I spent Memorial Day weekend at a science fiction convention - readers who've been keeping up know I mentioned this last month - so here's how we did. Linux seems to have all the web browsers anyone could use, and then some. Good. We've gotten much better at having sound support, and handling those whacky plug-ins sites seem to like to use. Our little netlounge was about half Macs, and there are a few people whose prejudices about what the GUI ought to work like drove them into Linux' arms - and they were pretty okay with that. Good stuff, Maynard.
Except for the folks who had to deal with office software and an office-like feature set. Floppy support under Linux desperately confused people - if it auto mounted, they couldn't figure out how to make it let go of a floppy safely (and of course, these are PCs, so they'll cheerfully let go of the floppy unsafely). If they weren't, they couldn't figure out how to use a floppy without technical assisitance. Mtools are great but only if you already know about them. And they suck for letting someone save things straight onto the floppy.
Word processors still seem to be flighty and fragile creatures. I saw not one but two of the beasties die and take a document with it just because the user wanted to switch to landscape mode. The frustrated user stomped off in a huff; he won't be using Linux again all that soon. Spreadsheets default to saving files in their own whacky and hopelessly incompatible formats, with no particularly simple way to change that behavior visible from the configs. I mean, this is Linux; I'm sure it can sing sonatas if I tell it too. But I am the Editor Gal with a world of notes at my fingertips. These hapless folk who just wanted to mess with numbers and run a couple of printouts are not doing so well.
And don't get me started about setting up printing...
But hey, K desktop looks pretty. There are a decent number of users who will forgive the OS that looks pretty, because they can see that some effort is being put into it.
Me, I'd kind of like to see more programs defened themselves against imminent disaster, and at least pop up with some sort of error message, note that they can't safely use this feature yet, or the like. We've got too many good coders out there - we shouldn't be having to look at raw segfaults. Compared to that.... why, the Blue Screen of Death almost looks well documented and friendly.
Until next month, folks. And if your project does a little more sanity checking and cleaner complaints because you saw this, let us know, okay? I like to know when these little rants of mine make a difference. Trust me - it really will make Linux just a little more fun for folks at the keyboard.
 Combining multiple PDFs into one
Combining multiple PDFs into oneFrom Faber Fedor
Answered By Ben Okopnik, Yann Vernier
From the chaos of creation
just the final form survives
-- The World Inside The Crystal, Steve Savitsky
We could have just posted the finished script in 2c tips. but there's juicy perl bits to learn from the crafting. Enjoy. -- Heather
![]() Hey Gang,
Hey Gang,
I was playing with my new scanner last night (under a legacy OS unfortunately) when I realized a shortcoming: I wanted all of the scanned pages to be in one PDF file, not in separate ones. Well, to that end, I threw together this quick and dirty Perl script to do just that.
The script assumes you have Ghostscript and pdf2ps installed. It takes two arguments: the name of the output file and a directory name that contains all of the PDFs (which have .pdf extensions) to be combined, e.g.
./combine-pdf.pl test.pdf test/
I'm sure you can point out many flaws with the script (like how I grab the command line arguments and clean up after myself), but that's why it's "quick and dirty". If/when I clean it up, I'll repost it.
See attached combine-pdf-faber1,pl.txt
[Ben] If you don't mind, I'll toss in some ideas.
#!/usr/bin/perl -w use strict;
Good idea on both.
# n21pdf.pl: A quick and dirty little program to convert multiple PDFs
# to one PDF requires pdf2ps and Ghostscript
# written by Faber Fedor (faber@linuxnj.com) 2003-05-27
if (scalar(@ARGV) != 2 ) {
You don't need 'scalar'. Scalar behavior (which is defined by the comparison operator) would cause the list to return the number of its members, so "if ( @ARGV != 2 )" works fine.
![]() Okay. I was trying to get ptkdbi (my fave Perl debugger) to show me the
scalar value of @ARGV and the only way was with scalar(). That's also
what I found in the Perl Bookshelf.
Okay. I was trying to get ptkdbi (my fave Perl debugger) to show me the
scalar value of @ARGV and the only way was with scalar(). That's also
what I found in the Perl Bookshelf.
my $PDFFILE = shift ; my $PDFDIR = shift;
You could also just do
my ( $PDFFILE, $PDFDIR ) = @ARGV;
Combining declaration and assignment is perfectly valid.
![]() Cute. I'll have to remember that.
Cute. I'll have to remember that.
chomp($PDFDIR);
No need; the "\n" isn't part of @ARGV.
$PDFDIR = $PDFDIR . '/' if substr($PDFDIR, length($PDFDIR)-1) ne '/';
Yikes! You could just say "$PDFDIR .= '/'"; an extra slash doesn't hurt anything (part of the POSIX standard, as it turns out).
![]() I know, but I really don't like seeing "a_dir//a_file". I always
expect it to fail (although it never does).
I know, but I really don't like seeing "a_dir//a_file". I always
expect it to fail (although it never does).
![]()
Which simply ensures that the string ends with exactly one /.
tr#/##s
Better yet, just ignore it; multiple slashes work just fine.
for ( <$dir/*pdf> ){
=head
Here's the beef, Granny! :)
All you get here are the specified files as returned by "sh".
You could also use the actual "glob" keyword which is an alias for the
internal function that implements <shell_expansion> mechanism.
=cut
# Mung individual PDF to heart's content
...
}
opendir(DIR, $PDFDIR) or die "Can't open directory $PDFDIR: $! \n" ;
Take a look at "perldoc -f glob" or read up on the globbing operator <*.whatever> in "I/O Operators" in perlop. "opendir" is a little clunky for things like this.
`$PDF2PS $file $outfile` ;
Don't use backticks unless you want the STDOUT output from the command you invoke. "system" is much better for stuff like this and lets you check the exit status.
Note - the following is untested but should work.
See attached combine-pdf-ben1.pl.txt
![]() Thanks, I've cleaned it up and attached it. there's one thing that I
couldn't make work, but first...
Thanks, I've cleaned it up and attached it. there's one thing that I
couldn't make work, but first...
(now looking inside Ben's version)
die "Usage: ", $0 =~ /([^\/]+)$/, " <outfile.pdf> <directory_of_pdf_files>\n"
unless @ARGV == 2;
Uh, that regex there. Take $_, match one or more characters that aren't a / up to the end of line and remember it and place it in $0? Huh?
print if /gzotz/; # Print $_ if $_ contains "gzotz" print if $foo =~ /gzotz/; # Print $_ if $foo contains "gzotz" print $foo if /gzotz/; # Print $foo if $_ contains "gzotz"
So, what I'm doing is looking at what's in "$0", and capturing/returning the part in the parens as per standard list behavior. It's a cute little trick.
I guess I will have to do this one soon in my One-Liner articles; it's a useful little idiom.
![]() I had to move a few things around to get it to work. I did have one
problem though
I had to move a few things around to get it to work. I did have one
problem though
#convert ps files to a pdf file system $GS, $GS_ARGS, $filelist and die "Problem combining files!\n";
This did not work no way, no how. I kept getting "/undefinedfilename" from GS no matter how I quoted it (and I used every method I found in the Perl Bookshelf).
perl -we'$a="ls"; $b="-l"; $c="Docs"; system $a, $b, $c and die "Fooey!\n"'
That works fine. I wonder what "gs"s hangup was. Oh, well - you got it going, anyway. I guess there's not much of a security issue in handing it to "sh -c" instead of execvp()ing it in this case: the perms will take care of all that.
![]() To get it to finally work, I did:
To get it to finally work, I did:
#convert ps files to a pdf file
my $cmd_string = $GS . $GS_ARGS . $filelist ;
system $cmd_string
and die "Problem combining files!\n";
<shrug>
Anywho, here's the final (?) working copy:
See attached combine-pdf-faber2.pl.txt
concurrent processesFrom socrates sid
Answered By Jim Dennis
What are concurrent processes how they work in distributed and shared systems?Can they be executed parallel or they just give the impression of running parallel.
"concurrent processes" isn't a special term of art. A process is a program running on a UNIX/Linux system, created with fork() (a special form of the clone() system call under Linux). A process has it's own (virtual) memory space. Under Linux a different form of the clone() system call creates a "thread" (specifically a kernel thread). Kernel threads have their own process ID (PIDs) but share their memory with other threads in their process.
There are a number of technical differences between processes and kernel threads under Linux (mostly having to do with signal dispatching). The gist of it is that a process is a memory space and a scheduling and signal handling unit; while a kernel thread is just a scheduling and signal handling unit. Processes also have their own security credentials (UIDs, GIDs, etc) and file descriptors. Kernel threads share common identity and file descriptor sets.
There are also "psuedo-threads" (pthreads) which are implemented within a process via library support; psuedo-threads are not a kernel API, and a kernel need not have any special support for them. The main differences betwen kernel threads and pthreads have to do with blocking characteristics. If a pthread makes a "blocking" form of a system call (such as the read() or write()) then the whole process (all threads) can be blocked. Obviously the library should provide support to help the programmer avoid doing these things; there used to be separate thread aware (re-entrant) versions of the C libraries to link against pthreads programs under Linux. However, all recent versions of glibc (the GNU C libraries used by all mainstream Linux systems) are re-entrant and have clearly defined thread-safe APIs. (In some cases, like strtok() there are special threading versions which must be used explicitly --- due to some historical interactions between those functions and certain global variables).
Kernel threads can make blocking system calls as appropriate to their needs -- since other threads in that process group will still get time slices scheduled to them independently.
Other parts of your question (which appears to be a lame "do my homework" posting, BTW) are too vague and lack sufficient context to answer well.
For example: Linux is not a "distributed system." You can build distributed systems using Linux --- by providing some protocol over any of the existing communications (networking and device interface) mechanisms. You could conceivably implement a distributed system over a variety of different process, kernel thread, and pthread models and over a variety of different networking protocols (mostly over TCP/IP, and UDP, but also possible using direct, lower level, ethernet frames; or by implementing custom protocols over any other device).
- (I've heard of a protocol that was done over PC parallel parts; limited bandwidth but very low latencies! Reducing latency is often far more important in tightly coupled clusters than bandwidth).
So, the question:
What are concurrent processes how they work in distributed and shared systems?
... doesn't make sense (even if we ignore the poor grammar). I also don't know what a "shared system" is. It is also not a term of art.
On SMP (symmetrical multiprocessor) systems the Linux kernel initializes all available CPUs (processors) and basically let's them compete to run processes. Each CPU, at each 10ms context switch time scans the run list (the list of processes and kernel threads which are ready to run --- i.e. not blocked on I/O and not waiting or sleeping) and grabs a lock on it, and runs it for awhile. It's actually considerably more complicated than that --- since there are features that try to implement "processor affinity" (to insure that processes will tend to run on the same CPU from one context switch to another --- to take advantage of any L1 cache lines that weren't invalidated by the intervening processes/threads) and many other details.
However, the gist of this MP model is that processes and kernel thread may be executing in parallel. The context switching provides the "impression" (multi-tasking) that many processes are running "simultaneously" by letting each to a little work, so in aggregate they've all done some things (responded) on any human perceptible time scale.
Obviously a "distributed" system has multiple processors (in separate systems) and thus runs processes on each of those "nodes" -- which is truly parallel. An SMP machine is a little like a distributed system (cluster of machines) except that all of the CPUs share the same memory and other devices. A NUMA (non-uniform memory access) system is a form of MP (multi-processing) where the CPUs share the same memory --- but some of the RAM (memory) is "closer" to some CPUs than to others (in terms of latency and access characteristics. In other words the memory isn't quite as "symmetrical." (However, an "asymmetric MP" system would be one where there are multiple CPUs that have different functions --- some some CPUs were dedicated to some sorts of tasks while other CPUs performs other operations. In many ways a modern PC with a high end video card is an example of an asymmetrical MP system. A modern "GPU" (graphical processing unit) has quite a bit of memory and considerable processor power of its own; and the video drivers provide ways for the host system to offload quite a bit of work (texturing, polygon shifting, scaling, shading, rotations, etc) unto the video card. (To a more subtle degree the hard drives, sound cards, ethernet and some SCSI, RAID, and firewired adapters, in a modern PC are other examples of asymmetric multi-processing since many of these have CPUs, memory and programs (often in firmware, but sometimes overridden by the host system. However, that point is moot and I might have to debate someone at length to arrive at a satisfactory distinction between "intelligent peripherals" and asymmetric MP. In general the phrase "asymmetric multi-processing" is simply not used in modern computing; so the "S" in "SMP" seems to be redundant).
Hey MAC, sign in before you loginFrom Carl Pender
Answered By Yann Vernier, Faber Fedor, Jay R. Ashworth, Ben Okopnik, Thomas Adam, Heather Stern
Hi, I have a Suse7.3 Linux PC acting as a gateway with an Apache server running. I have a web site set up and what I want to do is allow only certain MAC addresses onto the network as I choose. I have a script that adds certain MAC addresses onto the network which works perfectly if I type the MAC address in manually but I need to automate it. I'll nearly there I think but I need a little help.
Here's the question I asked someone on www.allexperts.com but unfortunately the person could [not] help me. Would you mind having a quick look at it and if anything jumps to your mind you might let me know.
Here goes.... I have a acript that matches an IP address with it's respective MAC address via the 'arp' command. The script is as follows:
#!/bin/bash
sudo arp > /usr/local/apache/logs/users.txt
sudo awk '{if ($1 =="157.190.66.1" print $3}'
/usr/local/apache/logs/users.txt |
/usr/local/apache/cgi-bin/add
Here is a typical output from the arp command:
Address HWtype HWaddress Flags Mask Iface 157.190.66.13 ether 00:10:5A:B0:30:ED C eth0 157.190.66.218 ether 00:10:5A:5B:6A:11 C eth0 157.190.66.1 ether 00:60:5C:2F:5E:00 C eth0
As you can see I send this to a text file from which I capture the MAC address for the respective IP address ("157.190.66.1") and then send this MAC address to another script, called "add", which allows this MAC address onto the network. This works perfectly when I do it from a shell with the ip address typed in maually.
My problem is that instead of actually typing in the IP address (e.g "157.190.66.1"), I want to be able to pipe the remote IP address of the user that is accessing my web page at the time to this script as an input.
In order to do this, I tried:
#!/bin/bash
read ip_address
sudo arp > /usr/local/apache/logs/users.txt
sudo awk '{if ($1 ==$ip_address) print $3}'
/usr/local/apache/logs/users.txt |
/usr/local/apache/cgi-bin/add
But I'm afraid this doesn't work. I'm wondering where I'm going wrong. I also tried putting quotations around the variable $ip_address but that doesn't work either. On my CGI script I have the line 'echo "$RENOTE_ADDR" | /usr/local/apache/cgi/bin/change' to pipe the ip address of the user. I know this is working because if I include the line 'echo "$ip_address"' in my script then the ip address is echoed to the screen
I hope that I have made myself clear.
Thanks Carl
That is, first a " (two apostrophes) quote block making sure $1 and a " is passed on to awk unchanged, then a "" (two doublequotes) quote block keeping any spaces in $ip_address (not needed with your data, but good practice), then another " (two apostrophes) block with the rest of the line. The primary difference between " and "" as far as the shell is concerned is that $variable and such are expanded within "" but not within ".
Also, your script could be a lot more efficient, and doesn't need superuser privileges:
/usr/sbin/arp -n $ip_address|awk "/^$ip_address/ {print \$3}"
This isn't the most elegant solution either, but somewhat tighter. '$1 =3D=3D "'$ip_address'" {print $3}' works the same.
By the way, it's quite possible you don't need to write your own tools for a job like this, although it is a good way to learn. Have you examined arpwatch? (http://www-nrg.ee.lbl.gov and scroll down the page a bit)
Same fellow, slightly changed situation. -- Heather
![]() Hi I have a Suse 7.3 Linux PC acting as a gateway for
a wireless network. I have a script to allows users
onto the network depending on their MAC addresses and
another to stop them having access to the network.
Hi I have a Suse 7.3 Linux PC acting as a gateway for
a wireless network. I have a script to allows users
onto the network depending on their MAC addresses and
another to stop them having access to the network.
What I want to do is let them onto to the network and then 5 hours later, log them off again. I was told to use something like this:
#!/bin/bash /usr/local/apache/cgi-bin/add sleep 18000 /usr/local/apache/cgi-bin/remove
This is no good to me because if I put the program to sleep it will lock up. I cant have it locking up because then if another user logs on the program wll be locked up so they wont be able to access the net.
Do you habe any suggestions how to do this?
Thanking you in advance Carl Pender
Either way, why not use the at command? In their ~/.profile, place a line that says something like
at +5 hours < /usr/local/apache/cgi-bin/remove this_mac_address
(RTFM To get exact syntax, your script may need a wrapper, etc.)
For, as Ben says, some subset of the possible problem space.
![]() Well firstly, it a wireless Hot-spot kind of thing that
I'm trying to achieve here so the users dont have profiles.
Well firstly, it a wireless Hot-spot kind of thing that
I'm trying to achieve here so the users dont have profiles.
Secondly, I have a kind of "mock" billing system in place where the user enters credit card details (mock) and then they are allowed access onto the network for five hours. So I want them to be no longer have access to the network when that five hours has expired.
This is only for demonstartion purposes, so dont worry I'm not going to use this in a real life situation where I'll be handling credit card info.
I hope it is clearer now
Thanks Carl
I'm sure there are a number of other ways to accomplish similar things.
PAM allows for writing new modules, lemme check this partial list of them (http://www.kernel.org/pub/linux/libs/pam/modules.html) for some sort of moderated-login thingy? Hmm, unless TACACS+. RADIUS or Kerberos offer something like that, looks like you'll need to whip up something on your own, and mess with the control files underlying pam_time, too. However, here's something topical, an Authentication Gateway HOWTO: http://www.itlab.musc.edu/~nathan/authentication_gateway
WHich just goes to show that there are more HOWTOs in the world than tldp.org carries. Juicy references to real-world use in the References too.
Secure CVS - SSH tunnel problemFrom jonathan soong
Answered By Thomas Adam, Ben Okopnik, Jason Creighton, Kapil Hari Paranjape
Hi Gang,
I have been trying to install CVS securely on a machine that will be live on the Internet.
There are two ways i was hoping to secure it:
My problem is with (2) - securing pserver:
A common way of addressing this is to replace rsh with ssh, however
AFAIK this requires shell accounts
on the machine, a situation i _have to avoid.
![]() The solution i have which seems feasible is:
The solution i have which seems feasible is:
Using pserver's user management, tunnelled over ssh with a generic
ssh login and some sort of restricted shell.
I'm currently investigation this solution, however i'm not sure if there is a fundamental security flaw in this model, or what the restricted shell should look like.
I was wondering if you had any thoughts/opinions/suggestions on this? Or perhaps be able to point out a *much** easier way to secure it, that i missed!!
Any help would be much appreciated,
Jon
While I am not particularly sure of the security implications that my following suggestion has, I think that you could do something like this:
- Create a generic account
- edit "/etc/shells" and add at the bottom "/usr/bin/cvs"
- Save the file.
- change the generic user's shell.
(at this point, I am wondering whether or not it is a good idea to create a "wrapper" account for this "new" shell, something like:
See attached shellwrap.thomas.bash.txt
And saving it as "/sbin/cvsshell", which you could then add to "/etc/shells" instead?
(Details of step 4.) That way when the user is created,
- Edit "/etc/passwd"
- find the newly created user
- edit "/bin/bash" to "/sbin/cvsshell" (without quote signs mind you)
- and save the file.
Then you can use "ssh" to login into the newly created user and the default shell would be CVS by default.
I'm not sure how secure this would be.......
Using "rbash" is not an option in this case.
In almost-as-we-hit-the-press news, it looks like pserver doesn't require the local user to have a useful shell, so /bin/false should work. According to the querent, anyway. I'm not preceisely sure of the configuration on the pserver side that leads to that, though. -- Heather
Hmmm, it was just an idea..... I'm curious as to whether it would work, minus some of the security implications......
![]() Hi guys,
Hi guys,
Thanks for your help, i decided to implement it like so:
SECURE CVS without multiple unix accounts
Now only those developers who have sent you keys will be able to login (passwordless) to the CVS machine and will be automatically be dumped to sleep for 3 hours - this will keep the ssh port forward open.
![]() Now i can securely use CVS's pserver user management, without multiple
unix users.
Now i can securely use CVS's pserver user management, without multiple
unix users.
Anyone have any thoughts on the security implications of forcing the users to execute 'sleep 3h' e.g. can this be broken by sending weird signals?
kill -9 $(pidof "sleep 3h")
(I have seen the command "pidof" on Debian, SuSE and RH -- it might not be distributed with Slackware as this claims to be more POSIX compliant, something that "pidof" is not).
~$ about pidof /sbin/pidof: symbolic link to killall5 /sbin/killall5: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped ~$ greppack killall5 sysvinit-2.84-i386-19
(Of course, to use the 'about' and 'greppack' scripts, you'd have to ask me to post them.)
Last I recall POSIX was a stnadard that declared minimum shell and syscall functionality, so I don't see why it would insist on having you leave a feature out. In fact "minimum" is the key since merely implementing POSIX alone doesn't get a usable runtime environment, as proved by Microsoft. -- Heather
kill -9 $(ps aux | grep "sleep\ 3h" | grep -v "sleep\ 3h" | awk '{print
$2}'
If this happens then the rest of your command will fail.
The security implications of this, is that the rest of the command will never get executed. I came up with a "bash daemon" script three years ago that would re-spawn itself by "exec loop4mail $!" which used the same process number as the initial "loop4mail &" command.
Security was not paramount in that case.
If the command is killed, then the users will most likely be left dangling at the Bash prompt.....
Hmm... that's interesting. However, I already wrote the recursive version already, so I'll stick with that.
If a symlink doesn't point to anything, it will fail a test for file existance:
~/tmp$ ln -s doesnotexist symlink ~/tmp$ ls -l total 0 lrwxrwxrwx 1 jason users 12 May 27 10:46 symlink -> doesnotexist ~/tmp$ [ -e symlink ] && echo "symlink exists" ~/tmp$
Circular symlinks are fun too.......
$ namei /usr/bin/vi
Gives
f: /usr/bin/vi d / d usr d bin l vi -> /etc/alternatives/vi d / d etc d alternatives l vi -> /usr/bin/nvi d / d usr d bin - nvi
While
$ readlink -f /usr/bin/vi
Gives
/usr/bin/nvi
So I shall extend you the same offer, and say that I'll post you my script, if you like....
[time passes]
I was just looking at the options for 'grep' and it turns out that I could just call grep, like so:
grep killall5 -l /var/log/packages/*
'-l' causes grep to print the names of the files that match, not the lines that match.
Jason Creighton, CEO of Wheel Reinvention Corp.
(Our motto: "Code reuse is silly")
http://packages.debian.org
Contains a search link as well.
Otherwise, I'd just have written a little Perl interface to the search page and been done with it. Instead, I download a 5MB or so file when I have good connectivity so I have it to use for the rest of the time.
|
...making Linux just a little more fun! |
By Michael Conry |

|
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release. Submit items to gazette@ssc.com
 June 2003 Linux Journal
June 2003 Linux Journal
![[issue 110 cover image]](misc/bytes/lj-cover110.png) The June issue of Linux
Journal is on newsstands now.
This issue focuses on Program Development. Click
here
to view the table of contents, or
here
to subscribe.
The June issue of Linux
Journal is on newsstands now.
This issue focuses on Program Development. Click
here
to view the table of contents, or
here
to subscribe.
All articles older than three months are available for
public reading at
http://www.linuxjournal.com/magazine.php.
Recent articles are available on-line for subscribers only at
http://interactive.linuxjournal.com/.
OpenForum and Software Patents
A false or misled 'open source representative' has signed an industry resolution calling for the EU to allow software patenting, which has been sent to members of the European Parliament...In an open letter, Graham Taylor, director of OpenForum Europe, rejected Perens' interpretation. Taylor made the point that OpenForum Europe only had a brief to represent its members, largely composed of businesses and corporations, and did not seek or claim to represent the wider Free Software or Open Source communities. It is questionable whether this distinction was equally clear to other readers of the initial letter.
SCOundrels?
As readers are surely aware, SCO (the software company formerly known as Caldera) has launched a hostile legal attack against IBM in particular, and indeed against the GNU/Linux community as a whole. Although the details will remain somewhat obscured until the case is thrashed out in court, it appears that SCO is alleging that IBM took code it had licensed from SCO (for AIX) and showed it to Linux kernel developers. It was access to this code that allowed GNU/Linux to become the stable and powerful operating system it is today... or so the story goes. The entire suit can be read at SCO's website.
This has lead to some bizarre situations, such as SCO threatening to sue it's partners in the UnitedLinux project, and the suspension of its own GNU/Linux related activities. One can only guess at how this plays with SCO's GNU/Linux customers who have now been marooned in a dubious legal situation. Perhaps they could sue SCO, since SCO was illegally selling intellectual property SCO owned (or something!).
To try and make some sense of this situation, it is useful to read Eric Raymond's OSI position paper on the topic. This document is a fine read, and gives an interesting overview of Unix history as related to the legal case. It would appear that there are one or two inconsistencies, inaccuracies and perhaps outright lies and deceptions in SCO's claims. Some of this madness is further highlighted in Linux Weekly News's account of SCO's refusal to come clean with details of what code infringes on their intellectual property (at least without signing a nondisclosure agreement). SCO CEO Darl McBride is quoted as saying:
"The Linux community would have me publish it now, (so they can have it) laundered by the time we can get to a court hearing. That's not the way we're going to go."But as LWN points out
"The Linux community, of course, would be incapable of "laundering" the code, since it is, according to SCO, incapable of implementing (or reimplementing) anything so advanced without stealing it.One has to wonder who was responsible for stealing the "intellectual" part of SCO's intellectual property.
...
Such a series of events would not change SCO's case in any way, however. If IBM truly misappropriated SCO's code, that act remains. And it is an act that cannot be hidden; the evidence is distributed, beyond recall, all over the Internet. And all over the physical world as well.
How this will all pan out is anybody's guess. It is certain that the story has some way to run yet. Further spice was added to the mix by Microsoft's decision to license SCO software leading to suspicions that they were attempting to bankroll SCO's legal adventures and help to undermine confidence in Free and Open Source software. Reports that SCO has destroyed archives of the Caldera-Microsoft antitrust lawsuit documentation have fuelled such speculation. Novell weighing in and claiming ownership of the contested code has further confused matters. An interesting development is the granting by German courts of an injunction preventing SCO from saying (in Germany) that Linux contains illegally obtained SCO intellectual property.
Probably the best course of action is that proposed by Ray Dessen on the Debian Project lists and reported by Debian Weekly News
"the issue so far consists of allegations and rumors from a company that is far along the way to obsolescence. They have yet to produce anything that could be remotely considered evidence, while there have been concrete indications of SCO itself violating the GPL by the inclusion of GPLed filesystem code from the Linux kernel into its proprietary (Unixware?) kernel."This "wait and see" approach is also the one taken by Linux Torvalds. If you want to be more active, you could start shouting "Hey SCO, Sue Me" or answer Eric Raymond's request for information
Some interesting articles from the O'Reilly stable of websites:
IBM Developerworks overview on the Linux /proc filesystem.
>From The Register:
Open Source Digest introduction to SkunkWeb (continues in part 2
>From Linux Journal:
Some interesting links found via Linux Today:
And some links from NewsForge:
Listings courtesy Linux Journal. See LJ's Events page for the latest goings-on.
|
CeBIT America | June 18-20, 2003 New York, NY http://www.cebit-america.com/ |
|
ClusterWorld Conference and Expo | June 24-26, 2003 San Jose, CA http://www.clusterworldexpo.com |
|
O'Reilly Open Source Convention | July 7-11, 2003 Portland, OR http://conferences.oreilly.com/ |
|
12th USENIX Security Symposium | August 4-8, 2003 Washington, DC http://www.usenix.org/events/ |
|
HP World | August 11-15, 2003 Atlanta, GA http://www.hpworld.com |
|
LinuxWorld UK | September 3-4, 2003 Birmingham, United Kingdom http://www.linuxworld2003.co.uk |
| Linux Lunacy | September 13-20, 2003 Alaska's Inside Passage http://www.geekcruises.com/home/ll3_home.html |
|
Software Development Conference & Expo | September 15-19, 2003 Boston, MA http://www.sdexpo.com |
|
PC Expo | September 16-18, 2003 New York, NY http://www.techxny.com/pcexpo_techxny.cfm |
|
COMDEX Canada | September 16-18, 2003 Toronto, Ontario http://www.comdex.com/canada/ |
|
IDUG 2003 - Europe | October 7-10, 2003 Nice, France http://www.idug.org |
|
LISA (17th USENIX Systems Administration Conference) | October 26-30, 2003 San Diego, CA http://www.usenix.org/events/lisa03/ |
|
HiverCon 2003 | November 6-7, 2003 Dublin, Ireland http://www.hivercon.com/ |
|
COMDEX Fall | November 17-21, 2003 Las Vegas, NV http://www.comdex.com/fall2003/ |
IBM Announces New Grid Offerings, Partners to form Grid
EcosysteM
IBM has announced new offerings to further expand Grid computing into commercial enterprises, including the introduction of new solutions for four industries - petroleum, electronics, higher education and agricultural chemicals. In addition IBM announced that more than 35 companies, including networking giant Cisco Systems, will join IBM to form the foundation of a Grid ecosystem that is designed to foster Grid computing for businesses.
IBM is working with Royal Dutch Shell to speed up the processing of seismic data. The solution, based on IBM eServer xSeries running Globus and GNU/Linux, cuts the processing time of seismic data while improving the quality of the data. IBM also announced RBC Insurance and Kansai Electric Power as new Grid customers.
Geek fair
Free Geek is a 501(c)(3) non-profit organization based in Portland, Oregon, that recycles used technology to provide computers, education and access to the internet to those in need in exchange for community service.
They are organizing a GEEK FAIR (version 3.0) which will take place Sunday, June 29th Noon to 6pm at 1731 SE 10th Avenue Portland, Oregon. The free community block party will include Hard Drive Shuffleboard, Live Music, Square Dancing, Food, Sidewalk Sale, Funny Hats.
Obviously most readers (worldwide) will have geographical problems attending this particular event, but maybe it will give people ideas to organise something similar more locally.
GELATO Federation
Overwhelming interest in running GNU/Linux on Itanium processors has helped to double membership in the Gelato Federation to 20 institutions. Gelato is a worldwide collaborative research community of universities, national laboratories and industry sponsors that is dedicated to providing scalable, open-source tools, utilities, libraries and applications to accelerate the adoption of GNU/Linux on Itanium systems.
Gelato's technical foci are determined by the members and sponsors, and collaborative work is conducted through the Gelato portal. Portal activity has tripled in the past two quarters, reflecting the momentum in membership growth. Recent member software made available through the Gelato portal includes two contributions from CERN: GEANT4, a toolkit for the simulation of the passage of particles through matter; and CLHEP, a class library for high-energy physics; and one from Gelato Member NCAR: the Spectral Toolkit, a library of multithreaded spectral transforms.
College Linux
Tux goes to college. Russell Pavlicek of NewsForge reports on College Linux, which has been developed in Robert Kennedy College, Switzerland. The distro has quite an important place in the operation of the college as some students study entirely via the internet.
Debian
Debian Weekly News reported that The miniwoody CD, which offers a stripped down variant of Debian woody, has been renamed to Bonzai Linux.
SuSE
The SuSE Linux CGL Edition is available at no charge as a Service Pack to SuSE Linux Enterprise Server 8 customers. CGL incorporates technologies defined by the OSDL's Carrier Grade Linux Working Group, an initiative whose members include SuSE, HP, IBM, Intel and leading Telecom and Network Equipment providers.
UnitedLinux
UnitedLinux has announced that its four founding partner companies will offer special support programs and discounts to ISV participants in the Oracle's Unbreakable Linux Partner Initiative. Oracle's Unbreakable Linux Partner Initiative provides financial and technical incentives to ISVs delivering solutions on Oracle's Unbreakable Linux software infrastructure. The Oracle Unbreakable Linux Partner Initiative complements Oracle's partnerships with strategically selected Linux platform providers and with hardware companies.
Mammoth PostgreSQL 7.3.2 released
Mammoth PostgreSQL 7.3.2 from Command Prompt, Inc. has been released. Mammoth PostgreSQL is a robust, reliable, SQL-compatible Object Relational Database Management System (ORDBMS). It is designed to give small to medium size businesses the power, performance, and open-standard support they desire.
100% compatible with the PostgreSQL 7.3.2 release, Mammoth PostgreSQL provides a commercially-supported and optimized PostgreSQL distribution for Win32, MacOSX and Red Hat Linux x86 platforms.
Also released is Mammoth pgManage 1.0, a platform independent PostgreSQL administrator available for GNU/Linux and Windows.
Majesty, from Linux Game Publishing
Linux Game Publishing's long awaited new game Majesty, is now in stock. A Demo is available, and the game is available for shipment immediately.
Appligent AppendPDF Pro 3.0
Appligent, Inc., a provider of Portable Document Format (PDF)-related software solutions, has announced the release of AppendPDF Pro 3.0, which enables businesses and organizations to dynamically assemble sections from PDF documents to build a completely new version with a choice of personalized features, such as a cover page and table of contents. This allows any PDF file to be automatically built and customized to the needs of each individual requesting specific information. AppendPDF Pro 3.0 is available for Windows NT/2000/XP, Solaris, Red Hat Linux, AIX and HP-UX, as well as Mac OS X.
AppendPDF Pro is available for purchase at www.appligent.com, as well as through the U.S. General Services Administration (GSA) Advantage Web site.
Opera 7 now available on Linux
Opera Software has released Opera 7 for Linux. The new version includes new feature changes from Opera 6 for Linux as well as a built-in e-mail client, not previously available in Opera for Linux. Download Opera 7.11 for Linux from www.opera.com/download
Other software
|
...making Linux just a little more fun! |
By John B Cole |
The guys at Addison-Wesley are cool in that they give my LUG free books, and judging by the titles we have received lately, web site security is something readers cannot get enough of. I am not going to bother regurgitating the meaningless blurbs on the back cover, nor the lengthy credentials of the authors; instead, I am going to focus on a simple question: can this book teach a working web developer useful lessons? If it does, it is worth the $49.99 cover price and if it does not I can use it in my fireplace. I am quite critical of expensive books which grossly overreach and as a result are unsatisfying to all readers. Let us see how "Web Hacking" stacks up...
"Web Hacking" is divided into four major sections: The E-Commerce? Playground, URLs Unraveled, How Do They Do It?, and Advanced Web Kung Fu. The authors are off to a good start - they (unlike about 99% of the posters on Slashdot) realize that "URLs" does not require an apostrophe. That is enough for a whole star even if the rest of the book is copied, grammatical errors and all, from Usenet archives (although the Gentle Reader should note that I am making no such assertion). The authors utilize a chatty, conversational style of prose over an academic style, which is appropriate for this book.
"The E-Commerce? Playground" leads off with a simple case study demonstrating an effective attack on a small business web site using only HTTP. The attacker exploited a poorly-written Perl script in the attack, and I hope we all realize that there is far more badly-written Perl in the world than not (the Reviewer must grudgingly admit that he has on occasion, contributed to that very problem). The authors point out that firewalls and intrusion detection systems are largely useless, and they will continue to emphasize this throughout the book. All of us would do well to remember that lesson. Sure, the attack in the case study would not work against Amazon or Dell, but there are a lot of small web sites that are ripe for the plucking...and one of those sites may have your credit card number. Chapter 1, Web Languages, covers everything from Perl to ASP in a nutshell. The idea here is more to demonstrate that every language (even HTML) has vulnerabilities that can be exploited by a knowledgeable hacker. Most web developers and system administrator will not learn anything new here, but pray that your boss does not skip this chapter before he picks the Perfect Language for your company's Web Site of Tomorrow. Chapter 2, Web and Database Servers, is very brief and only discusses Apache and IIS on the web server front and MS SQL Server and Oracle on the database front. I suppose it is not big deal that other web servers are not discussed, but it is worth noting that there are many different HTTP servers, and they turn up in the oddest places (What's running on your production servers? Are you sure?) A security-themed chapter written for enterprise-level customers, the sort who actually own licenses for Oracle and MS SQL Server, would be better off as a book. I am disappointed to see no discussion of MySQL or PostgreSQL here. More sites than you can shake a stick at, particularly mom-and-pop type businesses, are running MySQL on the backend, and there are a lot of poorly-secured MySQL installations in the world (-1/2 star). Chapter 3, Shopping carts and Payment Gateways, was largely new material for me. I was familiar with older attacks on systems which used client-side cookies and GET variables to store important (e.g. price) information. I had not considered some the attacks involving payment validation systems, and the examples in the book underscore the consequences of sloppy design. Chapter 4, HTTP and HTTPS: The Hacking Protocols, is included in large part to emphasize the fact that all an attacker needs is a URL to make you regret your choice of careers. That aside, its coverage of the HTTP and HTTPS protocols is useful as a thumbnail review, but the chapter will be of dubious value to a network novice. Chapter 5, URL: The Web Hacker's Sword, ends Section 1. This chapter is prefaced with a quote from "Star Wars Episode IV: A New Hope", which demonstrates clearly the geek-worthiness of the authors. Chapter 5 actually covers URL hacks, such as URL structure and encoding, as well as meta-character mischief and HTML forms. Some of the attacks described will only work with GET variables, which are visible to the user through the URL. So, a simple tip for avoiding easy web hacks might be: use sessions for persistent data and pass data from the browser to the server in POST variables. You have been warned. The material on metacharacters and form processing focus on the issue of user input processing. I have worked at universities for a long time, and believe when I tell you that you should never trust user input. Ever. As a whole, Section 1 of "Web Hacking" is useful to novice administrators and developers or managers; experienced professionals are unlikely to find anything new here.
Section 2, "URLs Unraveled", leads off with another case study. This case study demonstrates how a savvy hacker might analyze a web site based on the URLs exposed to the public, and use that knowledge to launch an attack. This case study serves to motivate the rest of the section. Chapter 6, Web: Under (the) Cover, provides an overview of web application structure, as well as the methods used by hackers to dissect target systems. There is all odd manner of thing in here, including web server APIs, ODBC, and JDBC. There is even a handy chart to help you match extensions to server platforms. The authors even mention some things you can do to limit your exposure, and one of the better ideas (IMHO) is to prevent the leakage of error and messages to the browser. Skim this chapter and look at the examples. Chapter 7, Reading Between the Lines, focuses on methods of analyzing HTML source (via "View Page Source") to identify vulnerabilities and develop attacks. Cool stuff here that can easily be overlooked during short, rapid development cycles. There is even an example of some nefarious uses of wget and grep. Chapter 8, Site Linkage Analysis, continues the exploration of site analytic methods. This chapter focuses principally on the uses of several software tools for site analysis, all of which are Windows tools (except for wget). I am torn about this section. Much of the material seems quite obvious, but that is because I was already familiar with it. However, I feel that all novices and many seasoned professionals can learn from the material in this section. No deduction.
Section 3, "How Do They Do It", purports to be the real heart of the book, the "Great Magic Tricks Revealed" of the web hacking world. Chapter 9, Cyber Graffiti, covers the web site defacement attacks typically reported in the media. A detailed case study covers a number of security issues, including proxy server configuration, HTTP authentication, and directory browsing. Good stuff. Chapter 10, E-Shoplifting?, provides a case study of an e-commerce system pieced together from several vendors (get this - an Access backend...). The basic attack was based on client-side forms validation and the use of hidden fields to pass price information. A site overhaul to address the risks exposed by an audit is detailed. Chapter 11, Database Access, is short but mentions some interesting attacks, as well as sound countermeasures. Chapter 13, Java: Remote Command Execution, was new ground for me. I would generally rather have hot pokers stuck in my eyes or program in COBOL than even look at Java source. However, being a savvy developer, I am well aware of the popularity of Java. I learned some neat stuff in this chapter, but the key take-home message is that you should always sanitize and screen user input. Countermeasures based on servlet management are also discussed. Chapter 13, Impersonation, deals with sessions, session hijacking, and cookies. This chapter is sort of interesting, but unless a developer does something spectacularly foolish, such as using a system which generates guessable session IDs or stores important data on the client using cookies, these attacks are not a prominent threat. Of greater concern might be physical security to prevent copies of cookies on a user's machine from being stolen. Chapter 14, Buffer Overflows: On-the-Fly?, could be a book in its own right. Almost every vulnerability I hear about these days is due to a buffer overflow. This chapter covers pretty technical material, and the reckless reader might be faced with some C or ASM code fragments; if your hair is pointy, you have been warned. I am not sure that this chapter is very valuable other than to highlight the fact that not every web site vulnerability is due to poor programming or systems administration on the part of the consumer of information systems. Sun, IBM, Microsoft, and their ilk have all shipped numerous products with buffer overflows that have been identified. Even vendors make mistakes. Section 3 is what we all opened the book to read. On the whole, it is worthwhile reading. The authors do a very good job of dissecting attacks, and of emphasizing simple countermeasures such as "validate all input, whatever the source".
Section 4, "Advanced Web Kung Fu", perked my ears up. Is this Keanu Reeves "Whoa, I know kung fu!"-type insight, or more pedestrian "Oh yeah, I heard about that somewhere"-type insight? Chapter 15, "Web Hacking: Automated Tools" is simply an overview of some commonly-used hacking tools. Frankly, I have only heard of netcat because it was the only Unix tool discussed. I'm never going to beat an agent at this rate... Chapter 16, "Worms", is just an overview of a few famous worms that have ravaged the Internet like Germany pillaging France. I'm never going to be on "Kung Fu Theater"! Chapter 17, "Beating the IDS", covers some interesting things that you can do to intrusion detection systems (IDS), but is simply a curiosity. This section is more like "hitting a drunk guy with a pool cue when he isn't looking" than "advanced kung fu", and is the most disappointing part of the book. It feels like three chapters of briefs written for PHBs so that they can feel savvy at the end of the day. Shame on you guys, you were doing so well (-1 star).
There is little excuse for any competent developer today to deploy an application susceptible to most of the attacks detailed in this book (the use of sessions alone would foil many of these attacks), but the book is a worthwhile read for novice developers and managers in general. More experienced developers should read it at the bookstore while on a coffee break or yoink it from the intern. Is the book worth $49.99? I am afraid that I must say "No". $24.99 is a much more reasonable price, the thickness (492pp.) of "Web Hacking" notwithstanding (-1/2 star).
John is currently using Mandrake 9.1 on his desktop machine, but is going
to switch to Gentoo and prove his manliness any day now.
John will be happy to tell you about his research in animal breeding and
quantitative genetics just as soon as he can find a scrap of paper. You see,
this next bit is rather technical...
![[BIO]](../gx/2002/note.png) John is a scientist and programmer who has been using Linux since 1998, when a
deranged - and somewhat frightening - colleague insisted that there was A
Better Way. John is a supporter of free software, and has written several
applications to support his research, and scratch itches, in PHP and Python.
On several memorable occasions, he wrote PHP program that called Python
programs, parsed the output streams, and presented the results. He promises to
not do that anymore.
John is a scientist and programmer who has been using Linux since 1998, when a
deranged - and somewhat frightening - colleague insisted that there was A
Better Way. John is a supporter of free software, and has written several
applications to support his research, and scratch itches, in PHP and Python.
On several memorable occasions, he wrote PHP program that called Python
programs, parsed the output streams, and presented the results. He promises to
not do that anymore.
|
...making Linux just a little more fun! |
By Shane Collinge |
These cartoons are scaled down to minimize horizontal scrolling. To see a panel in all its clarity, click on it.
![[cartoon]](misc/collinge/415sock.jpg)
![[cartoon]](misc/collinge/417siren.jpg)
![[cartoon]](misc/collinge/418burger.jpg)
![[cartoon]](misc/collinge/419perlburger.jpg)
![[cartoon]](misc/collinge/420linuxburger.jpg)
![[cartoon]](misc/collinge/421beosburger.jpg)
![[cartoon]](misc/collinge/422appleburger.jpg)
![[cartoon]](misc/collinge/424food.jpg)
![[cartoon]](misc/collinge/425temp.jpg)
![[cartoon]](misc/collinge/426typical.jpg)
![[cartoon]](misc/collinge/427routing.jpg)
![[cartoon]](misc/collinge/428pearl.jpg)
![[cartoon]](misc/collinge/429gimpgimp.jpg)
![[cartoon]](misc/collinge/430font.jpg)
![[cartoon]](misc/collinge/431compliment.jpg)
![[cartoon]](misc/collinge/432yesiree.jpg)
![[cartoon]](misc/collinge/433stop.jpg)
![[cartoon]](misc/collinge/434free.jpg)
![[cartoon]](misc/collinge/435lotusnotes.jpg)
![[cartoon]](misc/collinge/437twohours.jpg)
![[cartoon]](misc/collinge/438spellczech.jpg)
![[cartoon]](misc/collinge/440people.jpg)
![[cartoon]](misc/collinge/442bat.jpg)
![[cartoon]](misc/collinge/443offsite.jpg)
![[cartoon]](misc/collinge/446irresistable.jpg)
All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in a pair of colorful tights fighting criminals. During the day... well,
he just runs around. He eats when he's hungry and sleeps when he's sleepy.
|
...making Linux just a little more fun! |
By Alan Keates |
Until recently the extent of my backup efforts were to take the occasional CD copy of my home directory and keep copies of important files somewhere else, usually on another disk partition, or a floppy disk.
All this changed with the need to run some Windows legacy applications. The only machine really suitable for this work was my main workstation, a 1.2 GHz Athlon machine, multiboot with four distributions. I decided to free up the 1st primary partition, which held Mandrake 9.0, and set up a Windows partition.
I freed up the 1st primary partition by transferring the contents of that to the 7th partition, overwriting an expendable Vector Linux 3.0 Distribution. To be totally safe I booted into Debian 3.0, mounted both partitions to individual mount points in /mnt and as root used tar and a pipe to copy everything including all links and permissions from the source partition to the target partition. A few minutes later, after changing my grub boot menu, I was able to boot into Mandrake 9.0 Linux in the 7th partition and verify that everything worked as expected.
At this point one would normally just DOS format the now free first partition and install Windows. However I began to feel a little uneasy. Windows could just format the whole darn drive, or some other similar screwup could happen, in which case I would be placed in the position of fdisk'ing the partitions and reinstalling everything from scratch. The original disks would, of course have all the applications except for those extra packages installed by me, but any custom configurations would all be lost.
The machine was now running Mandrake 9.0, Debian 3.0 and Slackware 8.1. Of these, only losing my Slackware install would cause me grief. This has been running like a top, boots to KDE 3.0 in less than 30 seconds, including my sign on, and is absolutely rock solid stable. It also has the CUPS print system set up perfectly for all my printers on the LAN. So I must retain this setup at all costs. The solution of course is to fully back up everything from the Slackware install.
At that point the desire to have a simple, easy and foolproof backup and recovery method took hold.
If we are a home or SOHO Linux user I would suggest the following, it should:
A quick review of past Gazette articles and a search of the web will turn up hundreds of backup solutions. Many are specifically aimed at the backup function, many at the repair and system recovery part of the overall effort to get back to some predefined state. Virtually none are customized to your system, or your specific requirements, so why not roll your own solution? That is what we do here.
Most home or SOHO users do not have a tape drive system and are unlikely to purchase one for the sole purpose of backup, given that the cost of the tape system and software most probably exceeds that of the computer itself. This essentially leaves just backup to removable disk, backup to the same or another hard drive, backup to CD and backup over a network to some other hard drive. This last is essentially just a more complicated backup to local hard drive except there is zero chance of it being lost when your system goes down. So let us look at these options.
Floppy - Good for incremental backups on a daily basis and perhaps the best solution for saving work as it progresses, but useless for system wide restoration. The LS120 Disk and the Zip disk are not large enough or common enough to be considered for the sort of simple but complete backup considered here.
Hard Drive - One can back up to a separate partition on the same drive, which of course is of little use if that drive fails, or one can backup to another hard drive in the same computer. This is good except there is a fair chance that a power supply failure or nearby lightning strike could fry both drives (or somebody could steal the computer), leaving nothing to restore.
Network File System Transfer - This is a good solution to backup and restore of the files, for one interested enough to correctly install it, however it does nothing for the process of getting the system up again to the point where one can restore the files. Too complicated for most to institute.
CD-ROM - This is where it begins to look interesting. These days most Linux users have installed a CD burner and the availability of cheap CD-RW disks means that the cost of maintaining something akin to the traditional rotating backup system is definitely on. This is the one for us.
The most essential requirement is to have a working and reliable CD burner. Any current Linux distribution will have the tools required, and to minimize media costs, about $4 will supply two good quality CD-RW disks. For daily backups these will last for about five and a half years and used weekly a machine eternity!
The scheme proposed here is to use the two CD-RW disks to take backups in rotation; in my actual implementation I have color coded the spine of the disk covers Red and Green respectively, to aid in the correct rotation.
We also require the backup disk to self boot into a minimal working Linux system. This is to ensure that we can re-establish the Master Boot Record (MBR) and the rest of the original partition information if required. This rules out using a boot disk image as commonly supplied with the majority of distributions. These supply just a boot method and a Linux kernel, and usually boot straight to the partition they are customized to boot.
After a quick perusal of the small Linux on self boot CDs I settled on using the classic and well tried TomsRtBt disk in 2.88 MB image format. This is not an ISO image, but is suitable for being the boot image of an ISO we will burn. It is also to be found at various other sources on the web. I have used this in the floppy format and it is very good and quite complete. Note that it also includes a Toms FAQ.
In order to restore our working Linux system to a given state we will require records of all of the current directory contents which are changing on a day to day basis or have changed as customizations since initial install. This can be done laboriously by inspection and detailed lists, which will minimize what must be restored, or accomplished very easily by backing up the entire contents of these directories.
In my case I have decided to back up the entire contents of /home /etc /usr/local /opt /var /root /boot of the Slackware 8.1 partition.
In addition to the contents of each of the identified directories above there are some more very important pieces of information one wouldn't want to be without if a sudden failure to boot occured. These are a binary copy of the MBR, a text list of the Partition Table, a copy of the fstab file in case you have forgotten which partitions correspond to what filesystem, and optionally a copy of the current XF86Config file and/or the text output of commands like lsdev and lspci for full system information.
Also how are we going to structure all of this information to ensure it gets onto the CD in such a way as to be completely self contained and usable for the task at hand?
Here is what I did. Firstly create a directory to hold all of the information to backup. As root: mkdir /tmp/backup. Note here that I am using /tmp as repository for the constant part of the backup CD. This is safe in Slackware, but might not be in other distributions, choose a safe location and one not itself backup up by the tar file.
Put into the backup directory a copy of TomsRtBt Img file : cp ./tomsrtbt288.img /tmp/backup/tomsrtbt288.img, here the img file is in my home directory.
Put into the backup directory a copy of the Master Boot Record: dd if=/dev/hda bs=512 count=1 > /tmp/backup/MBR.bin. The MBR holds the first stage of the boot mechanism you employ, in my case stage1 of Grub, the GRand Unified Boot Loader, or LILO, and also the partition information for the Primary Partitions. The Extended Partition information is held elsewhere on the disk and can if required be restored with the information you will store from the fdisk command detailed next.
Put into the backup directory a list of the Partition Information : fdisk -l > /tmp/backup/Partition_Table, this will be used to compare with a Toms listing of the partition table before any restoration takes place.
Put into the backup directory a copy of fstab which defines the file system mount points, any errors here and the files and devices will not be accessible. cp /etc/fstab /tmp/backup/fstab.bak
Optionally copy any other information you wish available to you before you are able to boot into your newly restored Linux system. For easy accessability I keep a copy of XF86Config on the disk to ensure that I can always set up X the way I like even if installing a new system upgrade, and a copy of menu.lst as I use Grub as my boot loader of choice. cp /etc/X11/XF86Config /tmp/backup/XF86Config.bak ... cp /boot/grub/menu.lst /tmp/backup/menu.lst.bak
These files will be added to every copy of the backup disk that is burned, and need only be changed if one of them changes, when of course it should be copied over.
The script to accomplish this is shown below, for a text copy see backup. Be sure to rename the file without the .sh.txt part and to make it executable - chmod 755 ./backup - and copy to somewhere in roots PATH, /usr/local/bin is a good place, and do the same for the next script.
#!/bin/bash
# backup
#------------------------------------------------------------------------------
# Script to enable easy backup of all important Linux files
# and also creates a customized system repair disk.
# Uses two CD-RW Disks labled "RED" and "GREEN to rotate backups
#------------------------------------------------------------------------------
# The backup directory already contains files for boot and recovery.
# One can add more - my Slackware 8.1 system backup is < 580MB.
Backup_Dirs="/home /etc /usr/local /opt /var /root /boot"
Backup_Dest_Dir=/tmp/backup
Backup_Date=`date +%b%d%Y`
Image_File=/tmp/backup.iso
declare -i Size
# Create tar file with todays Month Day Year prepended for easy identification
tar cvzf $Backup_Dest_Dir/$Backup_Date.tar.gz $Backup_Dirs &> /dev/null
# Start backup process to local CD-RW drive
echo "Backing up $Backup_Dest_Dir to CD-RW Drive - $Backup_Date"
echo "Creating ISO9660 file system image ($Image_File)."
mkisofs -b toms288.img -c boot.cat -r \
-o $Image_File $Backup_Dest_Dir &> /dev/nul
# Check size of directory to burn in MB
Size=`du -m $Image_File | cut -c 1-3`
if [ $Size -lt 650 ]
then
echo "Size of ISO Image $Size MB, OK to Burn"
else
echo "Size of ISO Backup Image too Large to burn"
rm $Backup_Dest_Dir/$Backup_Date.tar.gz # Remove dated tar file
rm $Image_File # ISO is overwritten next backup but cleanup anyway
exit 1
fi
# Burn the CD-RW
Speed=4 # Use best speed for CD-RW disks on YOUR system
echo "Burning the disk."
# Set dev=x,x,x from cdrecord -scanbus
cdrecord -v speed=$Speed blank=fast dev=1,0,0 $Image_File &> /dev/null
Md5sum_Iso=`md5sum $Image_File`
echo "The md5sum of the created ISO is $Md5sum_Iso"
# Could TEST here using Md5sum_Iso to verify md5sums but problem is tricky.
echo "To verify use script md5scd, this will produce the burned CD's md5sum"
echo "run this as User with backup CD in drive to be used for recovery."
echo "This verifies not only the md5sum but that disk will read OK when needed."
# Remove image file and tar file
echo "Removing $Image_File"
rm $Image_File
echo "Removing : $Backup_Dest_Dir/$Backup_Date.tar.gz"
rm $Backup_Dest_Dir/$Backup_Date.tar.gz
echo "END BACKUP $Backup_Date"
echo "Be sure to place this backup in the RED CD case and previous CD in GREEN"
echo "------------------------------------------------------------------------"
exit 0
In use the process is simple, I usually backup every day, if not doing much on the system then every week. At the start of every backup I place the cdrom from the Green marked case into the CD burner. In an xterm I su to root and issue the command nohup backup &> /tmp/backup.log &, close the xterm and go to bed. The backup only takes about 15 minutes and so can also be done at any convenient time in a work day. When next at the computer I cat /tmp/backup.log and check that backup went well.
If I also want to verify the backup ISO I note down the first and last four or five letters of the listed ISO md5sum. As my burner will not reliably read back the CD just written I transfer the CD to my cdrom and verify that the md5sums are identical using the script md5scd, see below for a listing. If they are, I put that newly burned CD into the red case and the last burned CD into the green case ready for the next backup cycle. If any possibility of confusion exists one can always check the date on the tar file. Note that because of the burner not reliably reading the backup CD, that I have not included an automatic check of the md5sums, as failure to validate does not mean the CD is in error, just the read from the burner was. In fact, I have never experienced a md5sum compare failure when using my cdrom. I consider the MD5 checksum essential as even a single bit error could conceivably corrupt the whole compressed archive.
#!/bin/bash
#------------------------------------------------------------------------
# md5scd ---- Data CD md5sum Verifier
# Script to automate determining Md5sum for ISO9660 CDs
# NOTE - This script assumes that correct md5sum is known and one wishes
# to verify that a particular CD copy has been burnt correctly.
# If working from a downloaded ISO image use "md5sum ISO" at command line
#------------------------------------------------------------------------
# Requires standard tools found in all Linux Distributions
# If script invoked as user, check all permissions, groups, etc.
# Missing arguments?
if [ $# -ne 2 ]
then
echo "Usage - md5scd mountpoint device, ex - md5scd /mnt/cdrom /dev/hdc"
exit 1
else
: OK have arguments
fi
# Loop over md5sum determination ...100 good copies for install-fest?
again=yes
while [ "$again" = yes ]
do
echo "Please insert CD at $1 and press ENTER when ready"
read #Wait for insertion of disk
mount $1
Block_Count=`df -k $1 | grep $1 | cut -c 25-30`
#700Mb disk cannot exceed this ^^^^^ column limit in 1k blocks
umount $1
Md5sum_Cd=`dd if=$2 count=$Block_Count bs=1024 | md5sum`
echo "The md5sum of the CD at $1 is " $Md5sum_Cd
echo
echo -n "Verify another CD? [yes/no]"
read again # Wait for "yes" -> repeat, anything else -> drop through'
done
exit 0
Before that eventuality one should make sure the backup disk will boot, make sure one understands the limitations of tomsrtbt and as the only editor available is VI, practice reading the various files placed on the backup disk. The disk will have to be mounted first mount -t iso9660 /dev/xxx /mnt. It is possible to unzip and untar the tarred file using tomsrtbt by first using gzip and then tar.
However it is probably better to first check that the partition table is correct by fdisk -l and reference to the stored table, and if not to restore the MBR dd if=/mnt/MBR.bin of=/dev/hda bs=1 count=512. This will restore the primary partitions and the bootloader. Then use fdisk and the partition table file to manually restore the extended partition and the logical partitions within. This all requires nerve and practice! However any changes can be abandoned if not sure or only practicing.
Next do a clean install to the now proper partitions. Reboot to the point where one has a root console, mount the backup CD and execute tar xvzf /Mount_Dir/Backup_Tar_Filename. This will restore all of the previous directories into their correct places, and should leave you with an almost fully restored system.
Note that if the problem is only lost or corrupted files, one can also restore any of the saved directories at any time by extracting with tar xvzf /Mount_Dir/Backup_Tar_Filename /home, for example.
The test of any system is, "Does it work?" I initially verified that the backup CD does boot into Toms wonderful Linux system, that all of the text material was readable, of course fdisk -l did correspond to the stored version. I did not reinstate the MBR from the binary image file, however it is there if I ever need it.
The final test was to restore my Slackware 8.1 system in place of the original Mandrake 9.0 system, before installing Windows and perhaps needing to restore.
In brief,
Backup is easy to do and easy to keep doing. In use there are a number of small improvements that could be made. The manual backup and verification commands could be made shell variables and invoked with a single word. Also if the total file size becomes a factor one could use the --exclude flag of tar to not include large sections of invariant code in the tar file, or use bzip2 compression. As it is now, complete directories from root are saved.
The urgent need for the Windows applications turned out not to be so urgent, but provided the prod to actually backup regularly. Perhaps my next project will be to install Wine and try to get those pesky applications to run within Linux, without the need to always reboot.
I would be interested in any comments for improvement, indeed any feedback would be welcome, particularly if glaring flaws or omissions are evident. I can be reached at this address. This scheme has been in use for only a short time but so far I'm very satisfied, I encourage you to also institute regular backups. If you want a quick ready made approach try this one,a few changes to the scripts should have you backing up today and everyday after that .
Retired Control Systems Engineer, spent much of career designing and
implementing Computerized Control and Shutdown Systems for Canada's CANDU
Nuclear Reactors. A programmer for over 40 yrs and a Linux enthusiast since
1994, first log entry shows 7.83 Bogomips on a 386 DX33 machine still running.
Linux and Golf are in first and second place among many other hobbies.
|
...making Linux just a little more fun! |
By Cezary M Kruk |
This article was translated from the Polish by the author. The original will be published in the summer issue of CHIP Special Linux.
Whenever a new version of your preferred distribution arises, you always have the same dilemma: to install everything from scratch or to try updating the system or to continue with something you are used to so far?
Let us take two extreme possibilities into consideration: installing and configuring the system from scratch lets you find out and use all its new properties, while staying with just what you have gives you the certainty that you could continue your projects without any obstacles. What you face is a standard opposition between innovation and stabilization.
The basic configuration of the system is not difficult. But the more you need to have, the more effort you must put into it. Is it possible to simplify the installation and the configuration of the system to do it easier? A complete and clearly designed base containing the information about the changes you have introduced working with previous versions of the system makes tuning of the new version much easier. This method is not much complicated when you collect data but it demands more work when you restore the configuration. How could you automate and simplify it?
Fortunately Linux stores the information about the configuration of each individual service in the text files. Moreover it gives you a bunch of very good tools for processing such files. So it should be enough to prepare the right scripts and to use them when you need to install the system once again.
This article describes two groups of the scripts: the first used for installing and removing individual packages, and the other one used for securing the system against the potential aggression. Both of them are designed for Slackware Linux. The tools for installing and removing packages are not as sophisticated as the programs from SlackPkg or Packware packages are, but they offer you the full control over the system instead. The same is true about the scripts for securing the system. They perform only elementary operations. Both sets of the tools we collected in the slack*more bunch.
Having it as a pattern you can prepare other tools for automating the process of the configuration of any services or programs. If you decide not to tune the system manually at all but to supplement the appropriate script with the consecutive procedure instead you will soon gain your own kit of programs for configuring the system. Moreover, because you will prepare these scripts by yourself, they will perfectly meet your needs.
We have discussed it using as an example Slackware Linux because that distribution in a natural way makes users interfere with the configuration files directly. Other Linuces, offering complex programs for those aims, separate users from the files containing the information about the configuration. Thus the programs either make them lazy or force them to make sophisticated investigations to establish what and where was actually changed in their system by so-called friendly programs.
Slack*more is divided into two parts. INSTALL.tgz archive contains the tools for installing, removing or upgrading programs, and SECURE.tgz archive -- the tools for the preliminary securing of the system.
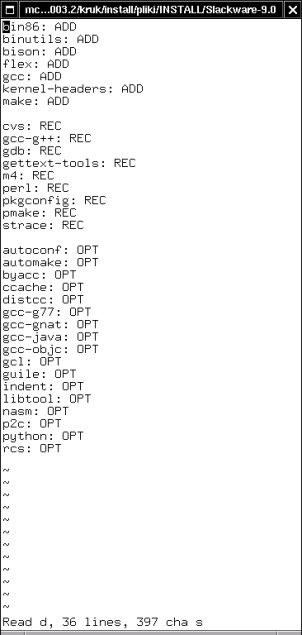
Figure 1. Thanks to SCRIPT.sh script from ./Slackware-9.0 directory you will generate a bunch of clear lists of packages from the individual groups. The figure shows the list of the packages from the d group (development)
The most important components of INSTALL.tgz package are INSTALL.sh script and ./Slackware-9.0 directory, containing SCRIPT.sh script and Slackware file.
To initialize those tools, you need to mount in /mnt/cdrom directory the installation version of Slackware, and then to run SCRIPT.sh from ./Slackware-9.0 directory. The script will look through the directories on the CD-ROM, and, guided by the tagfiles placed there, it will create the files containing information about the packages (Figure 1.). Each file will have the name corresponding to the name of the given group. For example: in the e file, registering the packages building Emacs, you will find among other things the following entries:
emacs: ADD emacs-misc: REC emacs-nox: OPT
The users who know Slackware Linux know that ADD category points out the packages essential to use in the given program, REC category means the recommended packages, and OPT category means the optional ones.
If you have such basic information about the packages, you can decide which components you want and which ones are useless for you. So if you modify the content of the above-mentioned e file in the following way:
emacs: ADD #emacs-misc: REC !emacs-nox: OPT
the emacs package will be expected to be installed, the emacs-misc package will be ignored, and the emacs-nox package will be not only ignored, but also -- if it was previously installed in the system -- will be removed.
In Slackware file from ./Slackware-9.0 directory there is some information about the individual groups of the packages:
a ap d e f ...
Basing on it the script will decide which groups of the packages should be taken into consideration. If you customize that file in the following manner:
a ap #d !e f ...
the d group will be ignored, and each package from the e group installed previously in the system, will be removed.
Thus: if you precede the name of the package or the name of the group by # , they will be omitted, and if you precede those names by ! , the corresponding components will be removed from the system. If a package or a group of packages have not been installed yet, the meaning of # and ! signs is equivalent. The entries from the files containing the names of the groups have priority over the entries in the files containing the names of the packages. So if you decide to ignore the whole group or to remove the packages belonging to it, the script will do it regardless of the information written down in the files collecting the names of the individual packages.
When you have prepared Slackware file and the files containing the information about the individual packages, you may run INSTALL.sh script. The script will add or remove the corresponding components from the system. If it is a preliminary installation of Slackware, and the system has not been tuned adequately yet, it is a good idea to optimize the work of the hard drive used as a platform for the new distribution. You can use for it one of -- INSTALL.hda or INSTALL.hdb scripts. Thanks to it the process of installing or removing the packages will be faster.
INSTALL.sh is designed for multiple usage. If there is nothing to do, it will do nothing. Using that script you can also perform the basic installation of Slackware. It is enough to install the packages from the a group first using Slackware's setup program, and next to put the script into the system, to comment the names of the packages or groups you do not need, and to install the rest, calling INSTALL.sh.
In ./Packages directory there is another SCRIPT.sh script. If you mount Slackware CD-ROM, and run the mentioned script, it will create the structure of the directories containing the files with information about individual packages of the system. Such reference data base about the packages is convenient because you do not have to mount the installation disc each time you want to check what the selected package is for. Building a base like that is reasonable only if you have not decided to install the entire Slackware Linux. Otherwise you will find the information about all its packages in /var/log/packages directory.
./Patches directory contains two scripts. If you want to use them, run 0.check first. It will check the sunsite.icm.edu.pl server looking for the available updating for Slackware 9.0 and will create the Packages.html file with the information about the updates and the Packages.txt file with the names of the packages:
mutt-1.4.1i-i386-1 sendmail-8.12.9-i386-1 sendmail-cf-8.12.9-noarch-1
1.get script will use the last file to get the packages, the appropriate .txt files, and the .tgz.asc files. In order to do it this script uses the command wget -c -t0 so there is no risk you will get the same files repeatedly. On the other hand checking if the given file is already got takes some time so it could be favorable to look through the Packages.txt file before you start 1.get, and to remove from it the names of the packages you already got or you do not care of. But this is not necessary.
You can change the command for getting of the files for wget -c -t0 -b . Then all the files will be got from the server at the same time -- in the background. But not every server allows you to establish such simultaneous connections. If the sunsite.icm.edu.pl server does not suit your needs, you can register in the 0.check and in 1.get scripts another host. Then you should customize the content of the command adequately generating the Packages.txt file from the Packages.html file. Originally it is the command:
cat Packages.html | grep ".tgz.asc" | sed 's/.tgz.asc//g' | sed \ 's/.*A HREF="//' | sed 's/">.*//' > Packages.txt
1.get script registers the information about casual packages only. The huge bunches of the updates for Slackware are put into separate directories (kde, kdei, etc.). If you want to get them, you will have to do it manually or to modify the original script suitably.
In ./usr/local/bin directory there is catpkg script which makes reviewing the files available in /var/log/packages directory for the information about all the packages installed in the system easier. INSTALL.sh copies the entire contents of the local ./usr/local/bin to its systemwide equivalent. So you can put here different scripts you want to use during the initial work with the system.
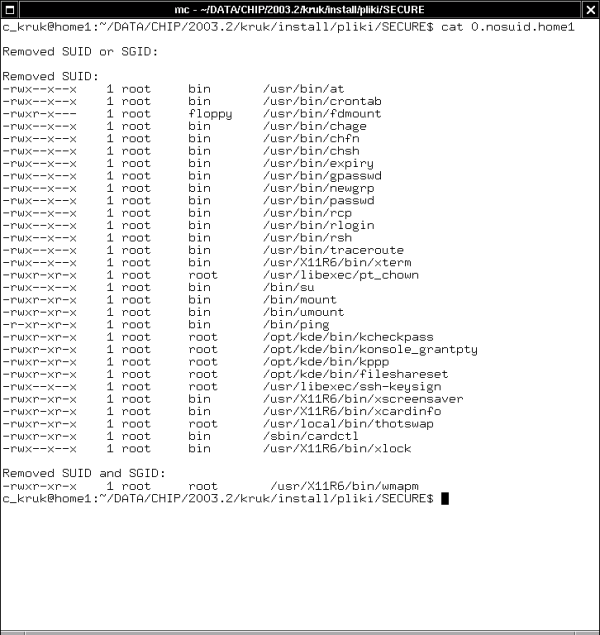
Figure 2. SECURE.sh script takes SUID and SGID bits away from the selected files and displays the information about it
The main script in SECURE.tgz archive is SECURE.sh. It performs the following tasks:
Sets in /etc/login.defs file the PASS_MAX_DAYS variable for 182. Thanks to it the validation time of the passwords of the new users will be limited to six months.
Sets in /etc/profile file the HISTFILESIZE variable for 100. Thanks to it the file of the commands history will be limited to one hundred lines.
Sets in the /root/.bashrc file the TMOUT variable for 900. Thanks to it the non active session of the root will be killed after fifteen minutes.
Comments in /etc/inetd.conf file all non commented, but potentially dangerous network services.
Puts in /etc/hosts.deny file the ALL: ALL@ALL entry, for blocking all exterior access to the machine.
Puts in /etc/hosts.allow file the ALL: ALL@127.0.0.1 : ALLOW entry, giving access to the resources of the local machine.
Changes in /etc/host.conf file the order hosts, bind sequence into the more secure order bind, hosts and adds the nospoof on sequence.
Blocks in /etc/securetty file the access for the root to all consoles except /dev/tty1.
Removes from /etc/group file the news and uucp groups superfluous in most cases. It is equivalent to give groupdel news and groupdel uucp commands.
Removes from /etc/passwd file news, uucp, operator, sync, and shutdown users. It is equivalent to the sequence of consecutive userdel commands taking the appropriate parameters.
Performs the parallel actions with reference to /etc/shadow file.
Sets in /etc/inittab file the comment sign at the line starting from ca::ctrlaltdel:/sbin/shutdown . Thanks to it the Ctrl-Alt-Delete shortcut stops to cause the reboot of the machine.
Takes away from all the scripts from /etc/rc.d directory the rights for reading or executing them by the group or by other users.
Adds to /etc/rc.d/rc.local file a few commands turning off or on different services. To make these commands work you should add to the kernel the IP: TCP syncookie support module.
Tests a few dozen of trouble programs and takes the SUID bit away from them. It stores the information about those modifications in the log file (Figure 2.).
Does the similar action with reference to a dozen or so of the programs, taking SUID and SGID bits away from them.
Puts in /etc/mail/sendmail.cf config file the entries O PrivacyOptions=noexpn and O PrivacyOptions=novrfy . It prevents the system from remote checking of the accounts.
Copies to /etc/cron.daily directory the remove script. It is used for automatic removing different temporary directories and files from the system.
Copies to /root/bin directory a few useful scripts.
Those actions increase the security of the system significantly, though it is just a beginning of the sealing it against the possible crack. SECURE.sh script was written in a way that it can be run repeatedly. So you can add any procedures to the script and to apply them without any problems.
The script modifies different services, but does not overload them. To reread /etc/inetd.conf, use killall -HUP inetd command. To execute the changed /etc/inittab, run init q command. To restart the sendmail use /etc/rc.d/rc.sendmail restart or kill -HUP `head -1 /var/run/sendmail.pid` command.
You may include those commands in the script, but it involves a potential risk you should take into consideration. If you make a small error in the call of the sed program, instead of the modified /etc/inittab file you can stay with an empty file. As a result after rebooting of the init you will lose the access to the system, and you will be forced to restore /etc/inittab from the copy, using Linux system installed on the other partition or disc. It is not always pleasant, particularly if you do not have another partition with Linux.
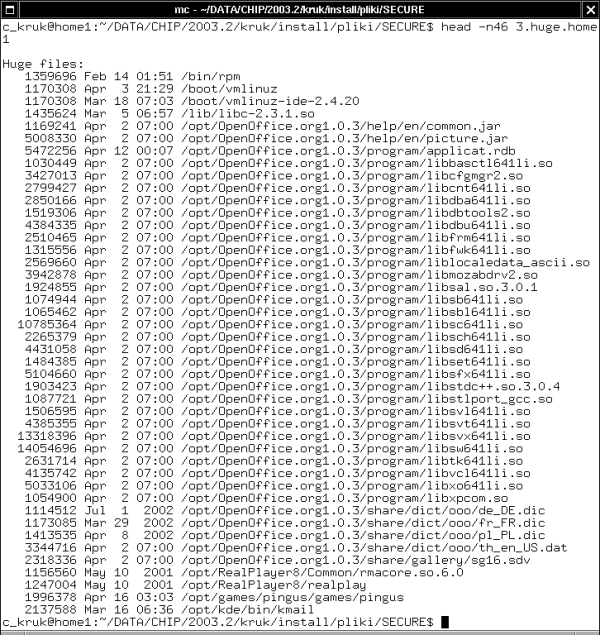
Figure 3. The list of the files of the huge size. As you can see, the prominent places are taken there by the files of the OpenOffice.org suite installed in /opt directory, as well as the RealPlayer and the Pingus files
TEST-SECURE.sh script seeks the system for some kinds of files:
The files having set SUID or SGID bits.
The huge and old files (the files over 1 MB, modified or used for the last time three months ago or before).
Exclusively the huge files (Figure 3.).
The files without any association to the user or group existing in the system.
The information about each category of the files is registered in the separate log file. Moreover TEST-SECURE.sh uses the results of the work of SECURE.sh script, showing the content of the log file with information about programs without SUID or SGID bits.
Because not always you will want to perform all these tests together, in /root/bin directory you will find 1.suid, 2.huge+old, 3.huge, and 4.nobody scripts-each of them does one particular test only.
It is worth extending SECURE.sh script with other procedures which will be responsible for configuration and installation of the further protections. Following the procedures used in the script you will be able to draw up the next scripts for tuning other services: configuring the accounts of the users, setting the network, e-mail and WWW services and clients, X Window environment, etc. The only limitation is your imagination because in that way Linux allows you to manage almost everything. So when you finish creating those scripts you will be able to configure the entire system exactly to your needs, just pressing the Enter key a few times.
Slack*more:
freshmeat.net/projects/slackmore
SlackPkg:
freshmeat.net/projects/slackpkg
Packware (Polish site):
Cezary lives in Wroclaw, Poland. He is an editor in the Polish-language
quarterly
CHIP Special Linux.
|
...making Linux just a little more fun! |
By Janine M Lodato |
I am lucky. I accompany my husband, Laszlo, to all the important high level board meetings and listen to how these smart Silicon Valley executives enjoy the new revolutionary passion of my husband, the Hungarian revolutionary who fought the Soviets and put the first big crack into that Evil Empire. But now his revolution is against the real Evil Empire: Microsoft. His new weapons are Linux and the Internet.
During one of the coffee breaks Laszlo cannot resist making the point about the importance of coffee in the world of revolution. The students in Budapest in 1956 sewed the seeds of revolution hovering over their double espressos in the coffeehouse on Castle Hill in Buda. Ever since the death of Joseph Stalin In 1953, the male youth of Budapest have been meeting almost daily to plot an uprising against their communist oppressors.
Not until today, October 22nd, 1956, does the time seem ripe for action.
His university colleagues and he determine which city squares they will stage their peaceful protests in: the technical university in Bem Square, the medical university in the square of the revolutionary poet, the universities of science and the arts in still other squares around Buda and Pest.
Over the centuries, coffee has earned the reputation of stimulating thought, boosting energy levels, preventing sleep, fostering opposition to rulers. Certain rulers throughout history (Napoleon, Frederick the Great, Pope Clement) have even tried to ban its widespread use because of its reputation. Late in the 16th century, Pope Clement liked coffee so much, he decided to adopt it, not ban it.
By 1700, coffeehouses in England were banned as hotbeds of revolution. In 1789, Danton met with fellow revolutionaries in Paris coffeehouses to plan the French Revolution. 1956 sees no bans on coffeehouses in Hungary, so he and his colleagues sip their espressos in this coffeehouse in Buda talking of strategies for the revolution they have planned to begin tomorrow.
The meeting is at the St. Francis Yacht Club in San Francisco with its atmosphere quite coffeehouse-like and quite appropriate for this revolutionary discussion.The Board members arrive early morning at the marina and are greeted by a high fog and drizzle. By noon, the fog burns off and the day is beautiful, clear, sunny and cool, typical of San Francisco's summertime weather. The setting of the Yacht Club with its great windows and verandas provides a spectacular panorama of the San Francisco Bay, Alcatraz at one end of the picture window and the Golden Gate Bridge at the other. Squawking seagulls furnish the sound effects for the meeting as they nose dive to the deck to pick up the bread crumbs left for them.
But the meeting is very long so my feet often swell from hanging down as I sit in my wheelchair.
The subject of the meeting is deep and important: what can assistive technology do for, what must it do for the baby boomers.
As baby boomers creep into old age, we acknowledge the passing of our grandparents, aunts and uncles, parents, movie stars and singers from the generation ahead of us. In rare instances, we have even been forced to accept the deaths of two famous peers, both Beatles, some infamous peers and worst of all, some of our children. Now it is time for us to face the reality of our own mortality, something I have had to do since being diagnosed with multiple sclerosis (MS) in 1980.
It won't be long before we must say goodbye to that generation of actors which includes Marlon Brando and Liz Taylor. In 1970 we tried hard to look like them. Now we try hard NOT to look like them. Soon enough, we will bid farewell to other favorite actors and singers, such as Dustin Hoffman, Meryl Streep, the two remaining Beatles, Elton John, Congress, the Clintons and finally to our families or whoever is left when our time is up.
Deadheads used to listen to the music of the Grateful Dead for relief from their woes. Now they call Dr. Jack Kevorkian for that relief.
In 1994, the world saw Superman as a courageous, heroic, fictitious character and admired him for his bravery. After his accident in 1995, the world saw Superman (Christopher Reeve) as a courageous, heroic, real-life figure and admired him even more for his bravery.
Because I am now confined to a wheelchair with near quadreplegia and can no longer run from anything, I need to use voice recognition for the computer and the telephone both requiring aid from my husband in moving the mouse and pushing buttons. The same goes for the remote controlling devices for the television and the CD player. I need hands-free control of the computer, telephone, television, CD player and wheelchair.
The point is, good things about me do exist: I am not blind, I am not broke, I am not boring, I am not betrayed and I am not braindead.
It would behoove people in the high-tech industry to produce hands-free products controlled by voice recognition paired with lip-reading to improve accuracy. I'm sure that day will come, I just don't know when. In the meantime, I must make use of voice recognition as it stands in 2002 so I speak to my computer and yell at my husband but the computer responds better and does not have an attitude.
Everyone is disabled at some time in their lives. Consider the driver who must always keep her eyes on the road. She is better off using voice activation to initiate, converse on and end telephone calls. One day , a car will be driven using voice activation. It's only a matter of time.
Technology developers should keep in mind that baby boomers make up a large share of the market. If they can bring in-home and automobile technology up to speed for that generation, they will win bigtime.
After many grueling hours of meeting at the Yacht Club, my husband reaches down and pulls my legs up to rest in his lap. Upon seeing this, one board member says to me, Your husband is so gracious. To which I respond, Yes, he can be very gracious. But don't let down your guard. He can also be a real asshole.
When Laszlo hears this, he adds, Mind you, that's not just any old asshole, that's a Royal Asshole.
|
...making Linux just a little more fun! |
By En D Loozzr |
THE CONSOLE DRIVER
As of Linux 2.4.x, the kernel includes a console driver sub-divided in a keyboard driver and a screen driver. The console driver is being entirely re-written for Linux 2.6.0 but at this stage, basically, the keyboard driver sends characters to an application, the application does its job and requests from the screen driver some output on the display. The console driver is complemented by the kbd package which is likely to reside either in /usr/share/kbd/ or in /usr/lib/kbd/.
In the path from the keyboard driver to the application and further to the screen driver, the characters are nothing but codes (hex numbers). And since in the end we want to see their little pictures (glyphs) on the screen there must be a way to associate the glyphs with those codes.
This article will focus on the screen driver only, taking for granted that something happens between keyboard and application. Some basic notions of fonts are required. Also keep the man page for the utility 'setfont' handy. The article is based on material from:
ftp://win.tue.nl/pub/linux-local/utils/kbd/
ftp://ftp.debian.org/debian/pool/main/c/console-tools/
http://qrczak.home.ml.org/programy/linux/fonty/
UNICODE
Traditionally, character encodings use 8 bits and are thus limited to 2^8=256 characters, which is not enough. Of course, once upon time printers and monitors knew nothing about diacriticals (accents, umlaut etc.) and further back in time they only had capitals and despised lower case. Those times are over and in the wake of i18n (internationalisation) 256 characters qualify as appetizers.
The UCS (Universal Character Set), also known as Unicode, was created to handle and mix all the world scripts, including the ideographs from China, Korea, Japan. It has more than 65000 characters for a start but it can go up to 2^31, figure it out.
UCS is a 32-bit/4-byte encoding. It is normalised by ISO as the 10646-1 standard. The most widely used characters from UCS are contained in its UCS-2 16-bit subset. This is the subset used now for the Linux console. The character set Linux uses by default for N and S America, W Europe and Africa is called latin1 or ISO 8859-1.
For convenience, an encoding called UTF-8 was designed for ASCII backward compatibility. All characters that have a UCS encoding can be expressed as a UTF-8 sequence, and vice-versa. Nonetheless, UTF-8 and Unicode are distinct encodings.
In UTF-8 mode, the console driver treats the ASCII range exactly as before, so old text viewers can continue to display ASCII. Characters above the ASCII range are converted to a variable length sequence of bytes (up to 6 bytes per character), UTF means indeed Unicode Transformation Format and UTF-8 covers the conversion of 8-bit characters - which was the range occupied by the traditional character sets.
Unicode is complex. Just keep in mind that it allows to assign an ID to any character. That ID has four bytes in its full form, and two bytes in UCS-2 subset, and here the unicode ID looks like e.g. 0x2502 also written as U+2502. If you know that ID, you can pick up the glyph (picture) for that character from a suitable font. Indeed, even the names of the glyphs are standardized and all capitals, e.g.:
FEMININE ORDINAL INDICATOR
All clear?
Problem 1: find out the official name for a given unicodeProblem 1 is not critical as far as the Linux console driver is concerned. The most common official names can be found in some *.trans files in kbd directory ../consoletrans or some *.uni files in the kbd directory ../unimaps. For more, refer to:Problem 2: get the glyph for a given unicode
http://partners.adobe.com/asn/developer/typeforum/unicodegn.htmlThe real hassle is problem 2.
GLYPHS
Although we have already been speaking of glyphs and it is kind of intuitively clear what they are, here are some additional remarks.
Launch your winword or equivalent word processor and type the letter 'a' several times changing font and size every time. All those a's look similar while they do differ in shape and size. What they have in common is that they all represent one glyph, the glyph for 'a'.
The reference to a glyph is just an abstraction from the particular font you will necessarily be using in order to see something.
A font a is a collection of glyphs in a particular shape. While in graphic
mode the typeface (shape) is emphasized, in the console we mostly bother
about which glyphs are included or not included - and possibly about font
size. A soft font for the console comes in a binary file with bit patterns
for each glyph. And there is a hardware font in the ROM of the VGA adapter.
This is the font you will see, if no soft fonts are loaded at boot time.
UNIMAP
The Screen Font Map gives, for each position in the console font, the list of characters it will render. Under Linux 2.4.x, the screen driver is based on the UCS-2 encoding.
The Screen Font Map is also called Unicode Map or Unimap or Console Map or Screen Map or psf table or whatever. The terminology varies a lot and does not contribute to easy understanding. Especially not as these terms had a different meaning before Unicode came up. And especially not when files that serve the same purpose and have the same format are named with different extension. Since it seems to be spreading and it sounds quite distinct, let us opt for unimap and its files *.uni. If you come across console utilities other than those from the kbd package, be wary of the terminology jungle.
There is always a unimap. It is included in the font or it is loaded from a distinct file or - as a last resort - it is the default straight-to-font or direct-to-font or trivial mapping or direct mapping or null mapping or idem mapping or identity mapping. Here again terminology has not settled and is hindering user empowerment. Idem mapping means that a request for character e.g. 0xB3 is received and the glyph at position 0xB3 in the font is directly picked up. To make the mess messier, the straight-to-font map is sometime not considered to be a unimap. We prefer to say that there is always a unimap even if setfont from the kbd package says otherwise. They use the option
setfont -u noneto enforce straight-to-font. mapscrn, now incorporated into setfont, used to call straight-to-font a special unimap. This is the more sensible choice, we'll stick to it.
One glyph can do for several different unicodes. How come? Well sometimes identical glyphs get multiple names. For instance, the capital letter 'A' is available in Russian and English with different names. But a font that covers both English and Russian does not need the glyph for 'A' twice. So two different unicodes give in this case the same visual result.
It can also happen that two glyphs are different but close to each other visually and only one of them is included in the font to save space and serves as surrogate for the other. This is analog to old habits from the era of the typewriter. For instance, opening and closing quotation marks were the same although in typography they are distinct.
Surrogates are formalised with the fallback entries. A fallback entry is a series of two or more UCS-2 codes, separated by whitespace. The first one is the unicode we want a glyph for. The following ones are those whose glyph we want to use when no glyph designed specially for the first code is available. The order of the codes defines a priority order (own glyph if available, then the second char's, then the third's, etc.)
Fallback entries are enabled if included in the unimap with a line like:
0x04a U+20AC U+004A(That means: for character numbered 0x04a we want the Euro symbol. If not available, take the currency symbol.)
SCREEN MODES
There are two screen modes, single byte mode (until recently the widely used default) and UTF-8 mode. Switching the screen to and from UTF-8 mode is done with the escape sequences '\e%G' and '\e%@' at the prompt. By issuing:
unicode_startyou switch both keyboard and console to and from UTF-8.
unicode_stop
In UTF-8 mode, the bytes received from the application and to be written to the screen are interpreted as a UTF-8 sequence, turned into unicodes and looked up in the unimap to determine the glyph to use.
Single byte mode applies an additional intermediate map to the bytes sent by the application before using the unimap.
This intermediate map used to be called the Application Charset Map or Application Console Map (ACM or acm). Unfortunately, this is the terminology of the console-tools package that seems to have quietly passed away.
The kbd package does not give any special name to the map, it refers to it as a translation table and puts it in files with extension .trans. The man page for setfont calls it Unicode console map which is extremely odd since it evokes the Unicode map (unimap). As a way out of the impasse, let us call it cmap, an abbreviation that already occurs here and there.
Here is a simple diagram for the two modes:
single byte mode:
application -> cmap -> unimap -> screen
(bytes) (UCS-2)
UTF-8 mode:
application -> unimap -> screen
(UTF-8 / UCS-2)
Memorize this diagram because it is the machete to cut through the documentation
jungle. Make sure you can tell cmap from unimap: what does the cmap do?
WHAT DOES THE CMAP DO?
There are several formats for the cmap and only one that allows to understand what the map really does. As an example, have a look at the file cp437_to_iso01.trans in directory ../consoletrans of the kbd package. Code page 437 stems from the early DOS and is still the font in the ROM of any VGA adapter.
This file has two columns of hex numbers. The first column is an enumeration of the slots in the font, 256 positions maximum. Only 256 can be handled by the cmap.
The second column is the translation. The file under consideration makes it possible to use a cp437 font as if it were a latin1 font. The translation is not perfect but it works. Example:
0xA1 0xADThe character 0xA1 in cp437 is an accented vowel which is not correct for this code in latin1. So cmap is informing the console driver to react as if the character request were for 0xAD. The console driver goes into the unimap (straight-to-font) and reads the unicode at position 0xAD. This happens to be U+00a1, the inverted exclamation mark. Next stop is the font where the glyph for U+00a1 has to be picked up. In the end, we had a request for 0xA1 but we did not get the character at that position in cp437, we got the inverted exclamation mark for the position 0xA1 in latin1. Our cp437 is behaving like a latin1 font thank to the cmap.
This example works flawlessly but since cp437 and latin1 differ a lot, in other cases you will get a miss, represented by a generic replacement character. Or you will get an approximation, a surrogate. For instance, you get a capital 'A' where you would need the same letter with a circumflex on top of it.
When using 256 char fonts, a cmap that really translates means surrogates. When no surrogates are needed, the cmap is straight-to-font: every character is translated into itself, only the unimap is relevant. This is the most natural and common case.
However, a font may be designed to cover more than one character set.
This is evident for 512 char fonts but there are indeed 256 char fonts
that can handle more than one character set (albeit only partially). If
you are using such a font, the cmap allows you to select one of the character
sets covered. One example (lat1-16.psfu) is discussed below.
G0/G1 LEGENDS
Although there is only one cmap active at a given time, the kernel knows four of them. Three of them are built-in and never change. They define the IBM code page 437 from early DOS versions with box draw characters, the DEC VT100 charset also with box draw characters, and the ISO latin1 charset. The fourth kernel charset is user-defined, is by default the straight-to-font mapping, and can only be changed loading a soft font.
The console driver has two slots labelled G0 and G1, each with a reference to one of the four kernel charsets. G0 and G1 can vary from console to console as long as they point to cp437, vt100, latin1. If you put a cmap different from those three in any slot G0 or G1 in any console, all other consoles will switch to that same user-defined charset. By default, G0 points to latin1, G1 points to vt100. G0 and G1 can be acted upon with escape sequences at the prompt. And although they are mentioned quite often, you better leave them alone. Why?
If you load a soft font and send escape sequences to switch between kernel charsets, you may well be applying to your soft font a translation that produces plenty of junk. The cmap you select must be suitable for your font and be a team player with the current unimap. The only guarantee you have in this respect is to rely on setfont and control both cmap and unimap. If you start mixing setfont commands with escape sequences to the console, also partly relying on defaults, you may (you will!) end up losing any sense of orientation. To keep cmap and unimap under control, use fonts that have a unimap built-in and use
setfont -m none this_beauty_of_font.psfuwhen loading a 256 char soft font. This gives a good guarantee of no interference if you are not playing with keyboard tools at the same time since keyboard tools may affect the console font. For 512 char fonts, you must know what's inside, and you must know the names of the charsets covered (i.e. the corresponding files *.trans) otherwise you will not be able to switch between them.
And what about the user-defined character set? If you have loaded a soft font (and any run of setfont loads a soft font except when you are just saving from the current font to disk), the escape sequence to pick up the user-defined character set from the kernel will make that soft font active with the charset implicit to it as cmap and you will not be able to revert to the ROM font. If you look into setfont's source code, you will see that they are activating the soft font's character set anyway. Forget the user-defined character set, it's none of your business, leave it to setfont.
On the other hand, if you run the ROM font and have not loaded a soft font, requesting the user-defined charset will only reset to cp437, the reason being that the user-defined charset has the default value straight-to-font. For instance, assume that you have chosen vt100 which does not have lower case letters and will immediately display junk. Send the escape sequence for the user-defined charset (which has not been defined yet and so still has the default value): the junk disappears, you get the lower case letters again.
There is, however, a soft font which has been explicitly made to cope with the kernel charsets. This font is called
lat1-16.psfuand is not a latin1 font as the name suggests, it is a mongrel. With the cmap set to cp437 it will deliver most of cp437 (all block and box draw elements), with the cmap set to latin1 it will deliver latin1. And it will also deliver vt100 should anybody care for it. Requesting the user-defined cmap unveils that the font uses the normally empty control ranges (0-31, 128-159) to pack together chars from cp437 and latin1.
Advice: if you are in a region where latin1 is not suitable, stick to
the font provided by your distro (and kiss most probably good bye to
the box draw elements). If latin1 is ok, use lat1-16.psfu. That will
give you the latin1 characters plus box lines for your file
manager.
DOCUMENTATION OR LACK THEREOF
The issues around Linux console fonts are poorly documented. The man pages are too dense, the terminology is windy, the HOWTO that comes with the kbd package is a despair, I wonder whether people who recommend it ever tried to read it.
The stuff presented in this article is elementary and still took quite an effort to grasp. Let us summarize it from a different angle, it will do no harm.
(i) ROM font (always 256 characters) (ii) console soft font
(a) 256 characters maximum (b) 257-512 characters
QUERIES & ANSWERS
How do I enforce the ROM font in the console?
There might be a utility for that somewhere but it is not in the kbd package. Without such a utility, the only way to enforce the ROM font is to boot into the ROM font. Check your init scripts and make sure no soft font is loaded. If you fail, rename the directory where the soft fonts reside so it cannot be found at boot time.How do I save the ROM font to a file?
When using the ROM font, issueHow do I find out which font the console is currently using?echo -ne '\e(U'
setfont -o cp437-16.psfat the prompt. The file cp437-16.psf contains the ROM font. This font has a height of 16 pixels.
If you mean which name the font has, look in the boot scripts and/or the shell history to find out what soft font was loaded last (possibly none, so the ROM font is on). If you want to see the characters in the font according to their internal arrangement, issueI have created my own font based on latin1 but adding box draw elements in the unused range 128-159. It works but the horizontal lines have little gaps. How come?echo -ne '\e(K'
setfont -om current_font.transand look inside current_font.trans with an editor. This does not work 100% because certain character ranges (0-31 and 128-159) are not properly displayed although they may be storing glyphs. If the font has a unimap, the unimap will list all characters with their official names. That will often give an idea of the glyph.
The characters are 8 pixel wide but the VGA hardware adds a 9th column of blanks so as to display them at a small distance from the each other. That is very appropriate for most characters but not for horizontal line segments that should rather close up to each other. For this reason, the VGA hardware makes an exception for box draw elements: instead of inserting blanks, the 9th column repeats the 8th column of pixels. So far, so good. But how does the VGA adapter know where you put your box draw elements? It does not, either you put them in the same range as they were in cp437 or you will get gaps.How can I use a 512 char font and save my bold colours?
You will have to boot into the framebuffer, for details see Framebuffer-HOWTO.html. Opinions about the framebuffer are divided, Mandrake boots into the framebuffer by default, SuSE advises against. Red Hat's official position is not known to me but they do not boot into the framebuffer although they use a 512 char console font that disables bold colours.The lati1-16.psfu is a 256 char font and still covers more than one charset. How is it possible?
It is only possible because it covers charsets only partially or covers charsets that are smaller than 256 characters. cp437 is full house, it has exactly 256 characters so lat1-16.psfu covers it only partially. On the other hand, latin1 keeps the control range 0-31 and 128-159 empty so it has only 192 characters. vt100 is handled as 128 characters but complemented with latin1 in the 160-255 range. So what lat1-16.psfu does is essentially keeping box and block draw elements where they used to be in cp437 and moving latin1 characters elsewhere. This way everything fits within 256 characters. Well done.Is the console font unique for all consoles or may it vary from console to console?
The console font is the same for all consoles, what can vary are the character sets (cmaps) used in the consoles.
|
...making Linux just a little more fun! |
By Cherry George Mathew |
It's hectic at work today. You have a hundred emails to reply to. There's that quality analysis report to submit this afternoon, a business presentation to prepare for the PR team, and a whole bunch of code to sift through for formatting errors. And then there's that favourite TV program that you can't miss out on by any chance. What do you do ? Switch on that TV tuner card of course. And watch the TV program in a window all by itself at the top right corner of your computer screen. All work and no play indeed! Now you can minimize the video window out of sight whenever the boss decides to take a peek over your shoulder. Or you could have it running full screen and beckon at him to come over and have a look if he's a fan too. ;-) Ah! The vagaries of technology!
The Linux platform supports a good number of tuner cards, as well as web cameras and an assortment of such multimedia devices. And as in every other operating system, the tasks of application programs and the kernel proper, are well demarcated and cut out distinctly. Video4Linux (or V4L), as the technology is called, is still evolving from a draft version 1, to a more robust version 2. On the way, lots of device drivers have been developed, primarily around the brooktree chip-set, but now increasingly around other models as well. Application programmers focus on preparing easy GUI based interfaces for the user, either for watching TV, or recording to disk or decoding and reading teletext and so on and so forth. For TV viewing, tasks such as preparing a window of just the right size on screen, requesting the relevant device driver to fill it in with live video (overlay), resizing the viewing area and asking the device driver to adjust the overlay size accordingly, passing on user requests to tune into a specific channel or to change the input from tuner to AV mode, or simply mute sound - these are responsibilities of the application programmer. The application therefore sits as a front end to the tuner driver, and passes on requests from the user to the driver in a previously agreed upon manner, called an Application Programmers Interface (API).
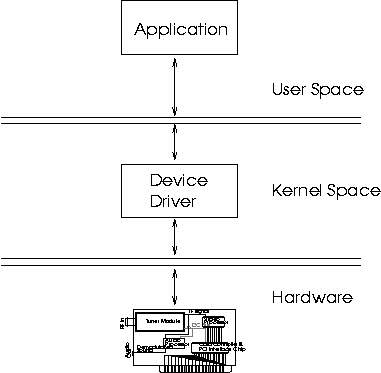
This is explained in detail later.Device Driver programmers, on the other hand, concentrate on translating user requests as mentioned above, into hardware instructions to the specific tuner card. They also make sure that they communicate with applications using the V4L API. Device drivers therefore, sit in between the hardware and the application, taking commands from them, translating them, and passing them on to the underlying hardware, in machine specific jargon.
Over the next couple of pages, you and I are going to try each others'
patience . We're going to show each other, among other things, how
TV tuner cards work, what they're made of, what types there are, how
to make them work in Linux etc etc etc. I say "show each"
other, because in attempting to put this article together, I've had
to do a bit of research myself, and that's because of you, dear Reader!
This is mutual then; so grab a piece of paper and a pen, sit back,
and read on.
Warning: Do not nod off. You're going to have a test afterward.
Keywords: PCI bus, I2C bus, IF (Intermediate Frequency), Video Processor,
Frame Buffer, DMA, IRQ.
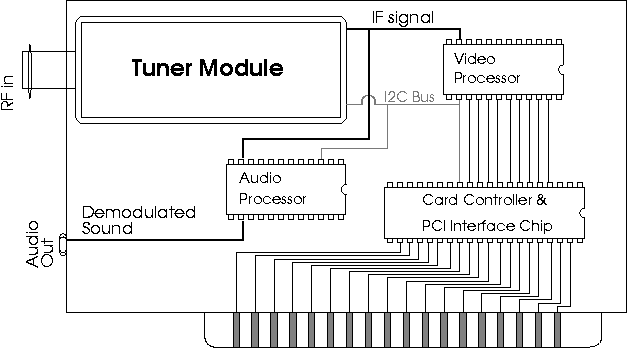
Alright, lets find out what a TV tuner card looks like. Typically, you'd spy at least three functional chips on board.
The tuner "chip", is actually a whole board with all the Radio Frequency Components mounted on it, and nicely wrapped up in silver foil, I mean, protective shielding. Take a look at the diagram. Tuner modules come in distinctive packaging, which often look very much like each other. Your antenna cable goes right into the socket at one end of the tuner module. The job of the tuner module, is to do all the Radio Frequency mixing magic, which tunes into a specific TV programme. Whatever frequency the TV programme be on, it is converted into a pre-determined intermediate frequency (IF). This "pre-determined" frequency is actually a real mess, because of historic (political ?) reasons. Each TV system (eg: PAL, SECAM, NTSC, etc.) has a unique IF. Whatever the IF is, the tuner takes care of one, and only one job - it takes in all the zillions of possible frequencies of radio waves in the universe, and at your command, filters out just the right TV programme for you. In the ''I2C section" 5, we'll find out how you "command" the tuner module to tune into your favourite Sports Channel.
The IF which comes from the tuner module, needs to be decoded, and transformed into a viewable format. This is the job of the Video Processor. Viewable Formats, again, due to historic reasons, come in various shapes and sizes. You've got the plain old bitmap format, palletized and planarized (uh, whatever does that mean ?) VGA format, RGB (for Red Green Blue) format, YUV Format (and its subtle variants) and of course, various proprietary formats. If you're keen at reading between the lines, you might have guessed that the "transformation" mentioned above, includes demodulation and Analog to Digital Conversion - which is the whole point of the TV tuner card anyway. When you watch TV on your Computer Screen, what you're actually looking at is Digitized Video Data from the Video Processor being displayed by your VGA adapter. Right, lets break that up into two steps:
Any data within the frame buffer, is immediately reflected on the screen. This is the job of the VGA controller. If you want to display something on the screen, all you need to do is to dump some data into the frame buffer. Voila! You can immediately see it on screen. On most platforms, this will involve just a plain memory to memory copy, because the frame buffer is mapped into the physical memory address space, just like any other RAM. However on a system which implements some sort of memory protection, applications may not be allowed direct access to system RAM. In Linux, this is controlled by means of the mmap() system call in conjunction with the /dev/ram device node or the frame buffer device driver. Check the manual page of mmap() for details. Of course, for this to work sensibly, the VGA controller has to agree with you about what you wanted to display, and what you wrote into the frame buffer, and where. This is done by "setting the VGA mode". By setting the VGA "mode", the meaning of every bit of data in the frame ram, is now known to the VGA controller. For example, if the VGA mode is set to "640x480" at 8 bpp. The VGA controller knows two things about the display:
Picture then, the typical tuner card in question. It has been instructed to tune into a particular channel, capture the video data from it pixel by pixel into some digital format (eg: 8 bpp or YUV), and to dump it into RAM. This procedure is called "video capture". Here are a few possibilities of video capture:
Tuner Cards typically handle sound in two different ways. The first method uses the audio processor to demodulate sound from the IF (IF contains both audio and video information). The audio signal thus obtained is routed to an external audio jack, from where one would need to re-route it to the line input of a separate sound card by means of a suitable external cable. If you're not wealthy enough to own a sound card, the line input of your hi-fi set will do :-).
The second approach is for the audio processor to demodulate sound from the IF, convert it into Digital Samples, and use techniques such as DMA (DMA is explained in the section on "PCI buses") to move these Samples to the sound card via the internal system bus (eg: The PCI bus), and from there, to use the sound card to reconvert the digital samples back to the audio signal. This method is more complicated, but more flexible, as the TV sound levels are controllable on the tuner card itself. The first method can avail of that luxury only by talking to the sound driver of the separate sound card. Either way, let's sum up our requirements, and what is required of us as competent device driver writers for tuner cards.
Alan Cox has written an excellent article on the Video For Linux API for capture cards in Linux. It comes with the kernel documentation (Documentation/DocBook/videobook.tmpl)2 and covers many issues connected with the Video4Linux API. What it does not cover are details of the tuner capture process. Although attempting to cover details about all varieties of TV capture devices in a single article is impossible, a good share of the tuner cards (I cannot vouch for web cameras, etc, which plug into the USB port) available may be expected to conform to what is presented here.
linux/videodev.h3 is the authoritative reference for the V4L API. We will therefore avoid a detailed description of the V4L API here. Any conceptual details about it may be made out from the document by Alan Cox mentioned above. Moreover the V4L API is an evolving standard. What holds good today, may not be applicable tommorow.
First, lets take a look at the mechanism involved in communication between application and device driver. If you already know about character devices, this is a repetition, and you may safely skip this topic.
In every Unix system, the /dev subdirectory holds special files called device nodes. Each device node is associated with a specific device number registered in the kernel. In Linux, the video4linux driver is registered as device number 81. By convention, the name of the node associated with this device number is /dev/video0. See (Documentation/devices.txt) for details about numbering device nodes. The node /dev/video0, if nonexistent, may be created with the mknod command from the root shell as shown below:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
main(){
char *buffer;
/* Lets allocate as big a buffer as we can. */
buffer = malloc(65535);
/* Open the device node for reading */
if((fd = open("/dev/video0", O_RDONLY))<0)
fprintf(stderr, "Sorry, error opening device /dev/video0\n");
exit(-1);
}
/* Read until program is killed or device runs out of Data (unlikely). */
while( read(fd, buffer, 65535)) write(0, buffer, 65535);
free(buffer);
}
Want to switch on the video display ? Do a
ioctl(fd, VIDIOCSAUDIO, &v);
int video_exclusive_release(struct inode *inode, struct file *file);
int video_usercopy(struct inode *inode, struct file *file, unsigned int cmd, unsigned long arg, int (*func)(struct inode *inode, struct file *file, unsigned int cmd, void *arg));
What we can do, then, is to focus our energies on writing code to program the tuner hardware to do various things like start capture, switch on sound, copy video data back and forth, etc. Most V4L ioctls boil down to tackling these problems anyway. Finally, when everything is ready, we could go about bridging the latest greatest V4L API with our underlying code. This is standard engineering practice.
--------------- Snippet -------------------
Brigadier to Engineer: "Lieutenant, I want that bridge up and ready by nightfall. "
Engineer: "Uh, that's impossible sir. We need to take measurements on the ground and order the parts from supplies before we can even think of starting to build. That'll take at least a couple of weeks Sir!."
Brigadier: "So there are no struts or screws, no angle bars or I joints, absolutely nothing with you to start work immediately ????
Engineer: "Uh, no sir, I never thought we'd need spare parts at such short notice...."
Sound of Gunshot.
End of Take 1.
--------------- End of Snippet ----------------Let's begin building the parts.
One part of the driver is concerned with acquisition of video data, ensuring that the tuner module is properly tuned in, that the video processor is decoding the correct standard (eg: PAL, NTSC etc.), that picture properties such as brightness, hue, saturation and others supported by the video processor hardware is adjusted, properly fine tuned or set to default values. Sound Acquisition can also be the responsibility of this part of the driver. These are described in detail in the section on I2C.
The other part of the driver is concerned with making sure that the acquired data is displayed properly on the screen. This part of the driver has to ensure that if video is viewed in a window, overlapping issues with windows of other applications are handled correctly. Details of parameters which get affected when the video window is resized or dragged to another location, such as pitch of the video window, number of lines acquired, number of pixels acquired etc are the responsibility of this section of the driver. Lets take a look at the window overlap problem, in more detail. In a windowing environment such as Xwindows, video overlay needs to be implemented in a window. The overlap problem begins the moment a corner of another application window overlaps a part of the video window.
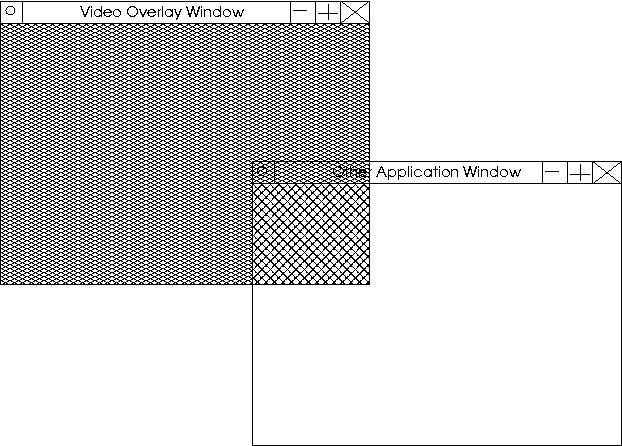
There are two options here:
What we can do then, is to begin writing routines which do little
things like setting the chroma key, setting the size of the video
window, positioning the window properly, etc. The best way to learn
such things is by example. We'll base our study on a few code snippets
from my unofficial and partly working driver for the Pixelview Combo
TV plus. This is a simple card, as simple as tuner cards can get to
be. The Tuner Module, video processor and VGA controller, all sit
on the same card. This card is plugged into the PCI slot, and doubles
both as a tuner card, and as a VGA display card.
Card Description:
The video buffer may be located anywhere within the frame buffer,
but typically, it is located at the end of the frame buffer. This
keeps captured video data samples from overwriting graphics samples
that were already present in the frame buffer and vice-versa.
Let us illustrate with an example:
| Frame buffer size | = | 2MB |
| Display mode | = | 640x480 @ 16bpp. |
| Total memory required for VGA display | = | 640 x 480 x 2 bytes |
| = | 614400 bytes | |
| = | 0.59 MB |
| Unused Memory at the end of the Frame buffer | = | 2MB - 0.59MB |
| = | 1.41 MB |
The hardware window interprets and displays data within its jurisdiction, entirely differently from what the VGA mode dictates. The size and location of this video window, can be changed by programming relevant VGA registers. The GD-5446 has three sets of registers namely: control registers , graphics registers, and sequence registers . Each of these VGA registers is accessed by multiple reads and writes to hardware ports, and are hence encapsulated in specialized functions. I've named them gd_read_cr(), gd_write_cr() and so on. This improves readability of the code, and reduces the chances of error. Here are a few routines from my driver. I've stripped them down for brevity:
#define GD_SR_OFFSET 0x3c4
#define GD_GR_OFFSET 0x3ce
#define GD_CR_OFFSET 0x3d4
/* Adapter - Low level functions */
unsigned value;
io_writeb(reg, gd_io_base + GD_CR_OFFSET);
value = io_readb(gd_io_base + GD_CR_OFFSET + 1);
return value;
}
Here are a few higher level functions
void gd_enable_window();
static void gd_set_window(,,,);
void gd_set_pitch(
{
CR3C = gd_read_cr(card_p, 0x3c);
CR3D = gd_read_cr(card_p, 0x3d);
/* CR3C[5] = offset[11], CR3D = offset[10:3]*/
gd_bit_copy(&CR3C, 5, &offset, 11, 11);
gd_bit_copy(&CR3D, 0, &offset, 3, 10);
gd_write_cr(card_p, CR3C, 0x3c);
gd_write_cr(card_p, CR3D, 0x3d);
gd_write_cr() is used to write a value into a specified VGA register. Please ignore the variable card_p for the moment. It is a structure where global state information about the driver is stored. card_p is use by gd_write_cr for book keeping purposes only. gd_write_cr(card_p, CR3C, 0x3c) will write the contents of the variable CR3C into the control register 0x3c. (don't be fooled by the name CR3C, its as much a variable as 'unsigned long foo' is.)
In the general case of a tuner card, where the VGA controller does not provide a separate hardware video window, the video processor will have to dump frames right into the middle of the graphics data. This will have to be done in such a way that when the VGA controller displays the new contents of the frame buffer, the video frame must appear correctly, and not skewed. This requires aligning the video data on pixel boundaries (every byte for 8bpp, every other byte for 16bpp, every four bytes for 32bpp, etc.). Besides that, the pixel representation within the video processor must match that of the current mode of the VGA controller. The video processor cannot acquire video at 32bpp and dump it into a 16bpp frame buffer. Also, video data cannot be overlaid in a linearly continuous fashion. The buffer offset of every line will have to be calculated as shown in the figure below:
Video Buffer Offset = Video Buffer Offset + Video Window Pitch x Line No.
In other words, all the precautions and calculations that the Xserver makes while drawing an application window, need to be taken by the video processor. Here, the video processor writes directly into the graphics buffer, and there is no distinction between video data and graphics data.
However, in the case of the GD-5446, the video processor does not write into the graphics area, and need not worry about alignment issues. All that the video processor routines need to ensure, is that video gets captured into the correct offset within the frame buffer, where the video buffer starts. The gd_set_vbuf1() routine takes care of that for us. The windowing details are then taken care of by the GD-5446 hardware.
For detailed descriptions of GD5446 hardware registers, take a look at the GD-5446 Technical Reference Manual.
Its time now for a guided tour of an IOCTL call. Consider that instant of time at which a video4linux application, such as xawtv (see: http://bytesex.org), calls ioctl() to switch on the TV window.
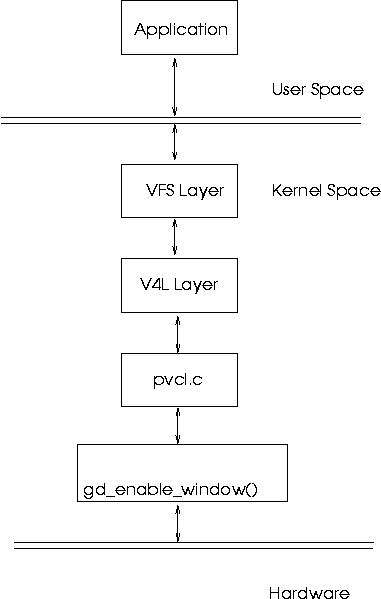
The application queries the device driver for available chroma keys, and selects one. It then proceeds to fill in the background of the video window with that single colour. Overlaps are then allowed to be painted over the application window, and the video capture is then turned on. Naturally, only the non overlapping regions, ( which are filled with the chroma key background ), are filled in with video data.
The GD-5446 has two interesting features, as far as tuner capture
is concerned. It has an I2C bus interface via two pins, and a Video
Port interface via 16 pins. The video port interface follows the ITU-656
standard for exchange of video data. Don't get scared here: Remember
that pixels can be made up of more than one byte ? eg: 16 bpp equals
two bytes. Well, somebody needed to tell chip manufacturers that in
the case of multiple bytes per pixel, transmissions between chips
needed to be done in a certain order. Take the case of YUV. Y stands
for brightness, U and V stand for the two colour components of a pixel.
Let each component occupy 1 byte (this is not true in real life YUV
4:2:2 format, but what the heck, let's illustrate to taste.). One
pixel therefore requires 3 bytes, ie; 24 bits. Here's the deal: If
you're a chip manufacturer, and you want to boast of an extra incomprehensible
line in your features list (to grab the attention of potential customers,
of course), consider the ITU-656 seal. But be-warned - once you're
sealed, the spirit of the beast is upon your chip. Video gets transmitted
only in a particular order: U-Y-V. And here's the good news: The VPX
3225D is part of the brotherhood! Ah, so now it all falls in place.
The VGA controller and the Video Processor have a clandestine path
of communication, via something called the VPort. And here's further
good news: the VPX 3225D has an I2C bus as well! Surprise Surprise
!
Ahem, alright, lets sober down a bit and figure out what this means:
Quiz time again:
Identify the master chip on the I2C bus of our Pixelview tuner card.
Let's take a look at SDA and SCL, the two I2C pins:
The SDA pin is the data pin. The SCL pin is the clock pin. The SDA pin may be driven either by the master or the slave, depending on the direction of data transfer. The SCL pin is driven exclusively by the master.
As Linux device driver writers, we're quite lucky. Most of the low level, pin level details are handled for us by the kernel. What we need to do is to plug in certain helper routines into the kernel. These helper routines allow the kernel to talk to the I2C bus on our tuner card. Helper routines are like sports car drivers on a cross country rally. Not only do Rally drivers know how to drive really well, they also know their cars in and out - whether its time to change the oil, or whether that front right shock absorber is leaking fluid, or when the clutch plate is close to tatters - little things like that; if there is a problem, the driver knows about it in a jiffy. The navigator, on the other hand knows the terrain, and the race route like the back of his hand. So seconds before the next hairpin curve, he shouts "one hard left coming up!", and the driver shifts down a gear, caresses the brake pedal, does a double twist on the steering wheel - and that's one less hair pin to take. Similarly, the kernel here knows the I2C protocol, and knows when the SDA and SCL pins need to be wiggled. The kernel barks orders to the helper functions, who do the actual wiggling. In order for the kernel to talk to helper functions, they need to be registered with the kernel. The kernel provides a registration function for this: i2c_bit_add_bus(). We pass it a structure defined so in linux/i2c-algo-bit.h :
void (*setsda) (void *data, int state);
void (*setscl) (void *data, int state);
int (*getsda) (void *data);
int (*getscl) (void *data);
/* local settings */
int udelay;
int mdelay;
int timeout;
struct i2c_algo_bit_data gd_bus;
gd_bus.setsda = gd54xx_setsda;
gd_bus.setscl = gd54xx_setscl;
gd_bus.getsda = gd54xx_getsda;
gd_bus.getscl = gd54xx_getscl;
udelay = 16;
mdelay = 10;
timeout = 200;
i2c_bus_add(&gd_bus);
Let me refer you to documents in the ('Documentation/i2c/') subdirectory for comprehensive details on the I2C implementation within the kernel. In particular, ('Documentation/i2c/writing-clients') is a very nicely written intro on writing I2C drivers.
Answer to quiz:
The GD-5446.
The kernel implements access to a few I2C master chips as well as a direct interface to the SDA and SCL pins. This interface is called the bit bang interface. In the case of the Pixelview Combo TV plus tuner card, we have direct access to the SDA and SCL pins of the I2C bus via SR8 of the GD-5446 VGA controller. SR8 is accessible via hardware ports 0x3c4 and 0x3c5. I've done these accesses using the gd_read_sr() and gd_write_sr() routines. Refer to (pvcl.c). Here's a description of the I2C control register, SR 8, of the GD5446:
| I/O Port Address: | 3C5h |
| Index: | 08h |
| Bit | Description |
|---|---|
| 7 | I2C SDA Readback |
| 6 | I2C Configuration |
| 5 | Reserved |
| 4 | Reserved |
| 3 | Reserved |
| 2 | I2C SCL Readback |
| 1 | I2C Data (SDA) Out |
| 0 | I2C Clock (SCL) Out |
Whenever one of the I2C bits within SR8 register is wiggled, it is reflected on the I2C bus and all slaves see the change. For example, if bit 1 of SR8 is set to 0, the GD-5446 pulls the SDA line low. If bit 0 of SR8 is set to 1, the GD-5446 pulls up the SCL line. Time to look at set_sda() and get_sda(). As usual, these two are from pvcl.c, and are stripped down for readability.
void gd54xx_setsda (int state)
{
set_bit(6, &i2c_state);
/* Set/Clear bit */
state ? set_bit(1, &i2c_state) : clear_bit(1, &i2c_state);
gd_write_sr(, i2c_state, 0x8);
What basically happens here is that gd54xx_setsda (1) pulls the SDA line high, while gd54xx_setsda (0), pulls it low.
set_scl() works similarly, except that the SCL pin is affected.
Getting the current status of the SDA pin works by reading the corresponding status bit from SR8. In this case, it is bit 7. If the SDA pin is high, bit 7 will be equal to 1. If it is low, bit 7 will be 0. This can be read into a variable, as shown below:
int gd54xx_getsda (i2c_state)
{
The first, is the concept of an adapter.
linux/i2c.h says: " i2c_adapter is the structure used to identify a physical i2c bus along with the access algorithms necessary to access it."In our case, the GD-5446 I2C bus along with the bit-bang access algorithm, make up the adapter.
Next comes the algorithm:
Here's what (linux/i2c.h) has to say about access algorithms:
"(an access algorithm) ... is the interface to a class of hardware solutions which can be addressed using the same bus algorithms - i.e. bit-banging or the PCF8584 to name two of the most common."The gd54xx_setsda(), gd54xx_getsda(), gd54xx_setscl() and gd54xx_getscl() functions, are helper functions for the bit-bang access algorithm. Consequently, they would not have existed if the GD-5446 I2C bus used some other mechanism, such as a PCF 8584 I2C interface.
The third concept we have to deal with is that of an I2C client.
Once again (linux/i2c.h) is the authoritative reference:
"(A client) ... identifies a single device (i.e. chip) that is connected to an i2c bus."In our case, we have just two clients: the VPX-3225D and the Phillips FM1216ME MK3 tuner module. The I2C protocol makes sure that only one chip is accessed at a time, by assigning certain addresses to certain chips. Therefore, every client has an address number associated with it. The VPX-3225D only responds to addresses 0x86 and 0x87 or, addresses 0x8e and 0x8f, depending on how the chip is configured. The tuner module responds to address 0xc6.
Every I2C transaction is prefixed by a target address. This must be done by the master. Only addressed slaves, may thus respond to queries from the bus master. This may also be used as a method to probe the I2C bus to see if it can detect any chips. The Linux kernel supports this kind of probing.
do:
"A driver is capable of handling one or more physical devices present on I2C adapters. This information is used to inform the driver of adapter events."At first it may seem funny that we're talking about another device driver within a device driver! But you notice that there may be more than one chip on a given adapter, and each chip needs to be programmed separately. Any piece of code, which understands the working of a piece of hardware, and programs it accordingly, may be called a driver. In this case, the driver may be just a couple of routines within a module, and there may be more than one driver, in that sense, within a kernel module.
It might be instructive to note that I've implemented the I2C driver for the VPX-3225D within another file called vpx322xd.c This separates the code between the main v4l driver, and the vpx part neatly. The two drivers would talk to each other via an internal arrangement similar to that of the IOCTL call in user space. Interestingly, the driver for the Phillips FM1216ME MK3 tuner module, is already available with the 2.4 kernel, and may be compiled as a separate module. This is an example of how open source works so well. I provide the adapter and windowing functions, somebody else provides the tuner driver to work over my adapter, I have a video processor module to add to that, and yet someone else, has written the video4linux user space client, which understands the V4L API. Cool, eh ?
To understand how to code the I2C driver for the video processor (the VPX-3225D, in this case), we need to know two things - the context in which our code runs, and the environment within which it runs.
When all is said and done, the purpose of the VPX-3225D driver, is to implement instructions passed down from the application. A generic I2C driver registers something called a ``command'' function, when it registers itself with the Linux I2C core. Once registered, this command function may be called by tracing it through a list of available I2C adapters. The linked list goes this way: adapter-> clients[n]-> driver-> command , where n is the nth client on an adapter. Therefore, adapter-> clients[n]-> driver-> command() would translate to ``call the command function associated with the driver for client ``n'' which resides on adapter''. The adapter structure is of course, accessible from the main V4L driver, pvcl.c, which registered that adapter in the first place. Therefore, all clients on that adapter, and hence, all client drivers and their callback ``command'' routines are accessible from pvcl.c by simply traversing through the adapter structure.
Let's trace through an ioctl() call for switching on capture.
Thus ends the section.
The PCI bus, is the most common bus used in today's computers. (For really innocent novices: A bus, is any piece of wire or set of wires, on which more than one peripheral is connected to at the same time, and therefore has be treated as a shared resource.) Apart from speed (33MHz up-wards), the PCI bus is a plug and play bus. This has nothing to do with the wires, of course. The wires on a PCI bus are as brain dead, as the wires in my table lamp. The difference is that any device connected to the PCI bus, must behave in accordance to a set of rules called the PCI specification. Among other things, PCI devices, ie; devices which are connected to the PCI bus, need to give information to the Bus Master about the Name, Type and number of functional Chips, their preferred IRQ lines, DMA capability etc. This helps the bus master share the resources of the bus effectively. The bus master in this case, would be a proxy of the system processor, usually a ``steering device'' or a ``bridge device''. We won't go into the details here. What interests us as tuner card device driver writers are three things:
Device Identification, DMA, IRQ line allocation.
Linux provides a set of functions for accessing information about PCI devices. These functions talk with the PCI hardware, and have already obtained details about all cards which are connected. What concerns us is identifying the Chip on board. pci_find_device() fills in a structure, with the name of the card, the Vendor ID of the card, and the Chip ID of the chip on board. These IDs are available in linux/pci_ids.h. They are available there, because each of the chip manufacturers has registered their devices in a central, public database beforehand.
In the case of the Pixelview card, the task of identifying the GD-5446 is very simple. Look for the PCI_VENDOR_ID_CIRRUS and PCI_DEVICE_ID_CIRRUS_5446. If both fields are available in the card database, then the card is indeed controlled by the CL-GD5446. Look for the probing function in i2c_clgd54xx_find_card() in pvcl.c, for info about how this is done.
Like any other bus, the PCI system allows transfer of data only between one master, and one slave. The master initiates the conversation, and the slave responds with data, or requests. On the PCI bus, the master, is usually a proxy of the system processor. This chip, behaves like the system processor itself, bossing all other chips into submission. Effectively, system devices see the processor in the proxy, and obey its instructions. But the processor is a very busy chip, and cannot devote itself to transferring data between PCI chips without giving up on performance. So the bus is designed to occasionally allow other slave chips to become masters, under the delegation of the system processor. In such cases, the new master of the bus has control over the PCI bus, and can initiate any type of transfer it likes. Of course, this mastership is on a lease of time, and the moment the processor desires so, the upstart has its rights revoked and is put in its place, and the processor takes over.
Let's take the case of a tuner card, which desires to transfer data to the VGA card. The tuner card chip, indicates its desire to do so, by raising a DMA request, on a special line called DREQ, on the PCI bus. The PCI controller chip, in consultation with the processor (via other lines external to the PCI bus), grants or revokes the request. Once the request is granted, the tuner card can address the VGA chip, just like the processor would, and it could initiate a transfer of data over the PCI bus, with the system processor happily going about other jobs. If ever the processor needed to access the VGA chip as well, it would only need to revoke the tuner card's bus rights, and write to the VGA chip, as usual.
In older buses like the ISA bus, a dedicated chip called the DMA controller was used for delegated bus mastering. It was the responsibility of the system kernel to allocate resources on the DMA controller itself, and thus the advantages of DMA were limited to a small number of devices, on such busses. In the case of PCI, any chip may become bus master, and the DMA controller would be placed on the individual card itself. This would make contention of the request line, DREQ, the only bottleneck. To alleviate the problem, multiple DREQ lines are available on the PCI bus, with the PCI bus controller arbitrating between simultaneous DREQs on multiple lines.
Devices need to indicate to the processor, events which are not predictable beforehand. Such events are called asynchronous events. Examples of Asynchronous events are: The arrival of a packet of data on a network card, the opening of the CD-ROM tray, the completion of filling a frame of video data by a video processor, etc.
Asynchronous events, are indicated by devices by using a line on the PCI bus called the Interrupt Request Queue (IRQ) line. IRQ lines, are scarce resources on a bus, and the PCI bus is no exception. However, IRQ lines may be shared between devices, if there were some means to discern between multiple parties sharing the same line. The code responsible for handling IRQ requests is called the Interrupt Service Routine (ISR). If an IRQ is indicated by some chip, the processor immediately switches to the ISR. The ISR then reads registers on each suspect device, until it finds which device on the shared line was the culprit for raising the IRQ, and does whatever needs to be done in servicing that request. Servicing might include tasks like saving the newly arrived packet, flushing system buffers, or resetting the pointers within a video processor. Each of these tasks is device specific, and hence, the device driver must contain the ISR, which is registered with the system kernel, so that it may be called at Interrupt time.
Nobody writes code from scratch. The very few who do, have very specific reasons for doing so, and even then, they rely on code templates, or ideas borrowed from their own or others' code. So if you are a budding device driver writer, the best way to start would be to read through device driver code which is already available in the Linux kernel. Don't worry, nobody will accuse you of plagiarism - the Gnu Public License (GPL) under which the Linux kernel is released, actually encourages code re-use. As long as you don't make verbatim copies of somebody else's code and change the authors' name to your own, you're free to use the kernel code. Any new part of existing code, may be claimed by you. Of course, remember that any GPL code which is altered, although the changes may be copy righted to you, may only be released again, under the terms of the GPL.
Click on the following links to see the source code.
An unofficial patch of the author's Linux Driver for the Pixelview Combo TV plus TV tuner card, is available for download at http://cherry.freeshell.org/downloads/
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_subdir -split 0 -show_section_numbers /tmp/lyx_tmpdir12763rVg3I/lyx_tmpbuf1276gZAXat/article.tuner.tex
The translation was initiated by Cherry George Mathew on 2003-05-20
Cherry is a graduate in Electronics Engineering, who
lives in the Indian City of Bangalore. His favourite hobbies are
Reading novels, playing the Guitar, and Hacking Code.
|
...making Linux just a little more fun! |
By Ben Okopnik |
- "Well, well - what have we here?"
Woomert Foonly had been working with his collection of rare airplanes, and
was concentrating on the finer details of turbocharger gate flows and jet
fuel cracking pressures. Nevertheless, the slight noise behind him that heralded
an unannounced visitor (Woomert could recognize Frink's step quite well) caused
him to instantly spin around and apply a hold from his Pentjak Silat
repertoire to the unfortunate sneak, causing the latter to resemble a fancy
pretzel (if pretzels could produce choked, squeaking sounds, that is). The
question was asked in calm, measured tones, but there was an obvious undertone
of "this hold could get much more painful very quickly, so don't waste
my time" that changed the helpless squeaking to slightly more useful words.
- "Ow! I'm - ow! - sorry, Mr. Foonly, but I just had to come
see you! I've got this bad problem, and - ow, ow! - I really didn't want anybody
to know, and - ouch! - I didn't want to use the front door, 'cause somebody
might have spotted me! I didn't mean any - ow! - harm, really!"
Woomert sighed and released his grip, then helped the stranger untangle
himself, since he clearly would not be able to, for example, untie his left
shoelace from his right wrist - especially since it was tied behind his back.
He smiled briefly to himself while working; the old skills were still in
shape, and would be there when he really needed them.
- "Next time, I suggest calling or emailing me ahead of time. The
Zigamorph Gang, whom I helped apprehend when I solved the Bank Round-Downs
Mystery, is out of prison and threatening various sorts of mayhem; I can
handle them and their plotting, but it's just not a smart idea to sneak up
on me right now - or at any time. Who are you, anyway?"
The visitor shook himself and made a forlorn attempt at straightening out
his rumpled jacket. Since it now resembled a piece of wrung-out laundry, he
gave up after a few moments and shook his head mournfully.
- "Well... my name is Willard Furrfu. You see, Mr. Foonly, I'm working
as a data entry operator, but I've been trying to learn some programming skills
after work so I can get ahead. I've managed to install a C compiler in my
home directory, and I've been experimenting with loops... and I managed to
really screw things up. I'm hoping you can help me, because if anybody
finds out what happened, I'm toast!"
While Willard was talking, Woomert quickly cleaned up his workbench and
closed the plane's cowling. When he was done, he beckoned his guest out of
the hangar and into the house. Once inside, he started a pot of tea, then
sat down and examined his guest.
- "Tell me exactly what happened."
- "Well... I'm not really certain. I wanted to practice some of the
stuff I've learned by copying an existing file to a random filename one line
at a time; unfortunately, it seems like the function that I wrote looped
over the file creation subroutine as well as the line copy function. It took
me only a few seconds to realize it and kill the process, but there are now
thousands and thousands of files in my home directory where there used to
be only fifty or sixty! Worse yet, given the naming scheme for the valid
files, it's impossible to tell which ones they are - the names look kinda
random in the first place - and I can't even imagine doing this by hand,
it's impossible. I don't mind telling you, Mr. Foonly, that I'm in a panic.
I tried writing some kind of a function that would loop through and compare
each file with every other one in the directory and get rid of the duplicates,
but I realized half-way through that, one, I'm not up to that skill level,
and two, it adds up to a pretty horrendous number of comparisons overall
- I'll never get it done in time. Tomorrow morning, when I'm supposed to
enter more data into these files, I'll be in deep, deep trouble - and I'd
heard of you and how you've helped people with programming problems before.
Please, Mr. Foonly - I don't know what I'll do if you turn me down!"
- "Hmm. Interesting." Woomert sniffed the brewing tea and closed the
lid tightly, then sat down again. "What kind of files are these?"
- "Text files, all of them."
- "Are they very large?"
- "Well, they're all under 100kB, most of them under 50kB. I'd thought
of taking one file of each size, but it turns out a number of them are different
even though the size is the same."
- "Do you care what the actual remaining file names are, as long as
the files are unique?"
- "Why, no, not at all - when there are only the original files, I
can go through them all in just a few minutes and identify them. Mr Foonly,
do you mean that you see a solution to this problem? Is it possible?"
Woomert shrugged.
- "Let's take a look at it first, shall we? No point in guessing until
we have the solid facts in hand. However, it doesn't look all that difficult.
You're right in saying that comparing the actual files to each other would
be a very long process; tomorrow morning would probably not suffice unless
it was a very powerful computer..." At Willard's hangdog look, Woomert went
on. "I didn't suppose it was, from the way it sounded. Well, let's give it
a shot. How do we get there from here?"
Willard brightened up.
- "I'd followed a number of your cases in the papers, Mr. Foonly,
and knew that you preferred SSH. In fact, I had just convinced our sysadmin
to switch to it - we'd been using telnet, and after I showed him some of
what you'd said about it (I had to censor it a bit, of course), he became
convinced and talked the management into it as well."
- "Not bad, Willard. You're starting off right - in some ways, anyway.
Whatever language you choose to learn, you need to be careful. You
never know what the negative effects could be, so until you're at least semi-competent,
you need to stay away from live systems. When this is over, I suggest you
talk to your sysadmin about setting up a chroot jail, where you can experiment
safely without endangering your working environment."
- "I'll do that, Mr. Foonly, as soon as I get back to the company.
Do you think that fixing this will take long?"
- "Let's see. Go ahead and use that machine over there to log in,
and we'll see what it tells us. What do you know - ``ls -l|head -1''
says ``total 27212'', which tells us that's how many files you've
got. So far, so good. All right - first of all, what did you call the program
that did this?"
- "Um, ``randfile''. I've still got the source..."
- "That's good, because we're going to delete it. I'd hate to have
you accidentally undo everything after it's fixed! Now, let's see... yep,
these look like all text, no problem. Another notch for you, Willard: accurate
problem reporting is a good skill to have, and you seem to be doing well.
All right then..."
Woomert's fingers flew over the keyboard as he fired off the one-liner. After about a second, he smiled but kept watching the screen - which, after a another second or two, printed a list of filenames.
perl -MDigest::MD5=md5 -0we'@a=@ARGV;@h{map{md5($_)}<>}=@a;@b=values%h;print"@b\n"' *
perl -MDigest::MD5=md5 -0we'@a=@ARGV;@h{map{md5($_)}<>}=@a;@b=values%h;print"@b\n"' *
#!/usr/bin/perl # "md5check" created by Ben Okopnik on Wed Apr 9 21:27:05 EDT 2003 use warnings; use strict; use Digest::MD5; die "Usage: ", $0 =~ /([^\/]+)$/, " <filename> <md5_hex_digest>\n" unless @ARGV == 2; open Fh, shift or die "Can't open: $!\n"; my $d = Digest::MD5 -> new -> addfile( *Fh ) -> hexdigest; print "MD5 sums ", ($d eq shift) ? "" : "*DO NOT* ", "match.\n"
key1 => value1 key2 => value2 key3 => value3 key4 => value4 key5 => value5 ...you'll see that it's an array of keys which point to an array of values. Consequently, we can treat it as such; as an example, we can create a hash of the alphabet and letters' numerical positions by saying
@alpha{ 1 .. 26 } = "a" .. "z"; # The range operator, '..' generates the two lists
The ``@'' sigil before the hash name simply indicates the context
of what is going on; what tells us about the type of variable we're using
are the curly braces following the variable name - that indicates a hash.
If we saw square braces, we'd know we were dealing with an array slice
instead.After a moment or two, Willard suddenly spoke up.
#!/usr/bin/perl -w use Digest::MD5 qw/md5/; { local $/; # Temporarily undefine EOL @n=@ARGV; $count = 0; while ( <> ){ $key = md5($_); $value = $n[$count++]; $uniq{ $key } = $value; } } print"$_ " for values %uniq
[1] Larry Wall, the creator of Perl, has suggested "Pathologically Eclectic Rubbish Lister" for those who simply can't stand to have Perl not be an acronym. "Practical Extraction and Report Language" has also been suggested for those who have to sell the idea of using it to management, which is usually well-known for its complete lack of a sense of humor.
[2] A zigamorph, according to the Jargon File, is a hex 'FF' character (11111111). A numerical complement of this would, of course, be all zeros - a null.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}